Teaching Language Models to Self-Improve by Learning from Language Feedback
2406.07168
0
0
Abstract
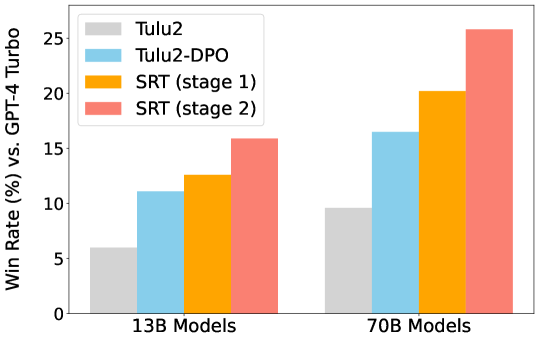
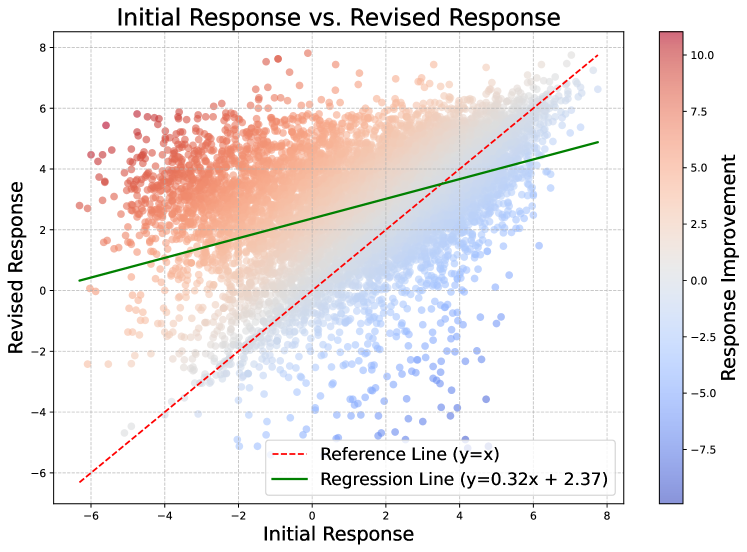
Aligning Large Language Models (LLMs) with human intentions and values is crucial yet challenging. Current methods primarily rely on human preferences, which are costly and insufficient in capturing nuanced feedback expressed in natural language. In this paper, we present Self-Refinement Tuning (SRT), a method that leverages model feedback for alignment, thereby reducing reliance on human annotations. SRT uses a base language model (e.g., Tulu2) to generate initial responses, which are critiqued and refined by a more advanced model (e.g., GPT-4-Turbo). This process enables the base model to self-evaluate and improve its outputs, facilitating continuous learning. SRT further optimizes the model by learning from its self-generated feedback and refinements, creating a feedback loop that promotes model improvement. Our empirical evaluations demonstrate that SRT significantly outperforms strong baselines across diverse tasks and model sizes. When applied to a 70B parameter model, SRT increases the win rate from 9.6% to 25.8% on the AlpacaEval 2.0 benchmark, surpassing well-established systems such as GPT-4-0314, Claude 2, and Gemini. Our analysis highlights the crucial role of language feedback in the success of SRT, suggesting potential for further exploration in this direction.
Create account to get full access
Related Work
Teaching Language Models to Self-Improve
This paper builds on previous research in the field of language model self-improvement. Techniques like self-refine instruction tuning, self-alignment, reflective enhancement, iterative refinement, and self-tuning have explored ways for language models to continuously improve themselves through feedback and self-supervision. This paper aims to build on these concepts by teaching language models to learn from natural language feedback.
Overview
- This paper introduces a novel approach for teaching language models to self-improve by learning from natural language feedback.
- The key idea is to train the language model to not only generate text, but also to interpret feedback on its own outputs and use that feedback to refine and enhance its future performance.
- The authors develop a feedback-based fine-tuning framework that allows the language model to iteratively learn from human feedback, gradually improving its language understanding and generation capabilities.
Plain English Explanation
The researchers in this paper are trying to create language models that can get better at their tasks over time, just by learning from feedback on their own outputs. Typically, language models are trained on a fixed dataset and then deployed, with no way for them to continue improving themselves.
The researchers propose a new approach where the language model doesn't just generate text, but also tries to understand feedback on its own outputs. For example, if a human provides feedback like "Your response could be clearer," the model learns from that feedback to produce better responses in the future.
This feedback-based fine-tuning framework allows the language model to iteratively refine its language understanding and generation capabilities. As it receives more feedback, it gets better and better at producing high-quality, appropriate responses.
The key innovation is giving the language model the ability to learn and improve itself, rather than just relying on its initial training. This could lead to language models that continuously get smarter and more helpful over time, without requiring manual retraining.
Technical Explanation
The core of the proposed approach is a feedback-based fine-tuning framework that allows language models to learn from natural language feedback on their own outputs. The framework consists of three main components:
-
Feedback Encoder: This module takes the language model's output and the human feedback on that output, and encodes them into a joint representation that captures the relationship between the model's response and the feedback.
-
Feedback Learner: This component uses the encoded feedback representation to fine-tune the language model, updating its parameters to better align with the feedback provided.
-
Feedback-Informed Generation: During inference, the fine-tuned language model uses the learned feedback representations to inform and improve its future text generation, producing responses that are more aligned with the desired feedback.
The authors evaluate their approach on a variety of language tasks, demonstrating that the feedback-based fine-tuning allows the language models to continuously improve their performance over multiple rounds of feedback and refinement. The results show significant gains in language understanding, coherence, and task-specific metrics compared to standard fine-tuning approaches.
Critical Analysis
One potential limitation of this approach is that it relies on the availability of high-quality, informative feedback from human users. If the feedback is vague, inconsistent, or unhelpful, the language model may struggle to learn effectively. The authors acknowledge this and suggest that techniques for eliciting and curating high-quality feedback could be an important area for future research.
Additionally, the feedback-based fine-tuning process could be computationally expensive, as it requires retraining the language model for each round of feedback. The authors do not provide a detailed analysis of the computational costs, which could be an important consideration for real-world deployment.
While the results are promising, further research is needed to understand the broader implications and potential limitations of this approach. For example, it would be valuable to explore how the feedback-based fine-tuning performs on a wider range of language tasks, as well as how it scales to larger, more complex language models.
Conclusion
This paper presents a novel approach for teaching language models to self-improve by learning from natural language feedback. By incorporating feedback-based fine-tuning, the language models can continuously refine their language understanding and generation capabilities, rather than relying solely on their initial training.
The results demonstrate the potential of this approach to lead to more adaptable and capable language models that can learn and improve over time. While there are some open questions and challenges to address, this research represents an important step forward in the field of self-improving language models, with potential applications in areas such as conversational AI, content creation, and task-oriented language assistance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Refine Instruction-Tuning for Aligning Reasoning in Language Models
Leonardo Ranaldi, Andr`e Freitas
0
0
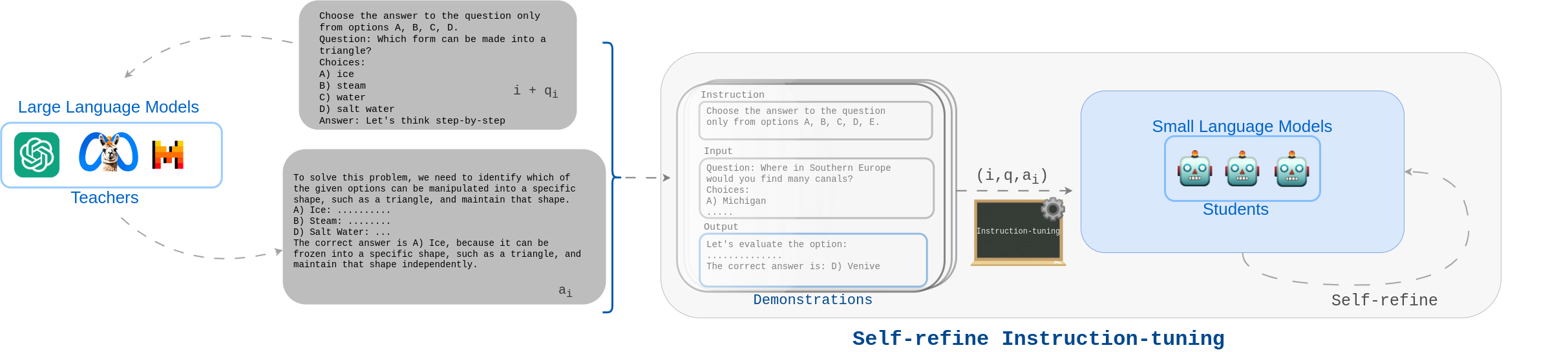
The alignments of reasoning abilities between smaller and larger Language Models are largely conducted via Supervised Fine-Tuning (SFT) using demonstrations generated from robust Large Language Models (LLMs). Although these approaches deliver more performant models, they do not show sufficiently strong generalization ability as the training only relies on the provided demonstrations. In this paper, we propose the Self-refine Instruction-tuning method that elicits Smaller Language Models to self-refine their abilities. Our approach is based on a two-stage process, where reasoning abilities are first transferred between LLMs and Small Language Models (SLMs) via Instruction-tuning on demonstrations provided by LLMs, and then the instructed models Self-refine their abilities through preference optimization strategies. In particular, the second phase operates refinement heuristics based on the Direct Preference Optimization algorithm, where the SLMs are elicited to deliver a series of reasoning paths by automatically sampling the generated responses and providing rewards using ground truths from the LLMs. Results obtained on commonsense and math reasoning tasks show that this approach significantly outperforms Instruction-tuning in both in-domain and out-domain scenarios, aligning the reasoning abilities of Smaller and Larger Language Models.
5/2/2024
TasTe: Teaching Large Language Models to Translate through Self-Reflection
Yutong Wang, Jiali Zeng, Xuebo Liu, Fandong Meng, Jie Zhou, Min Zhang
0
0
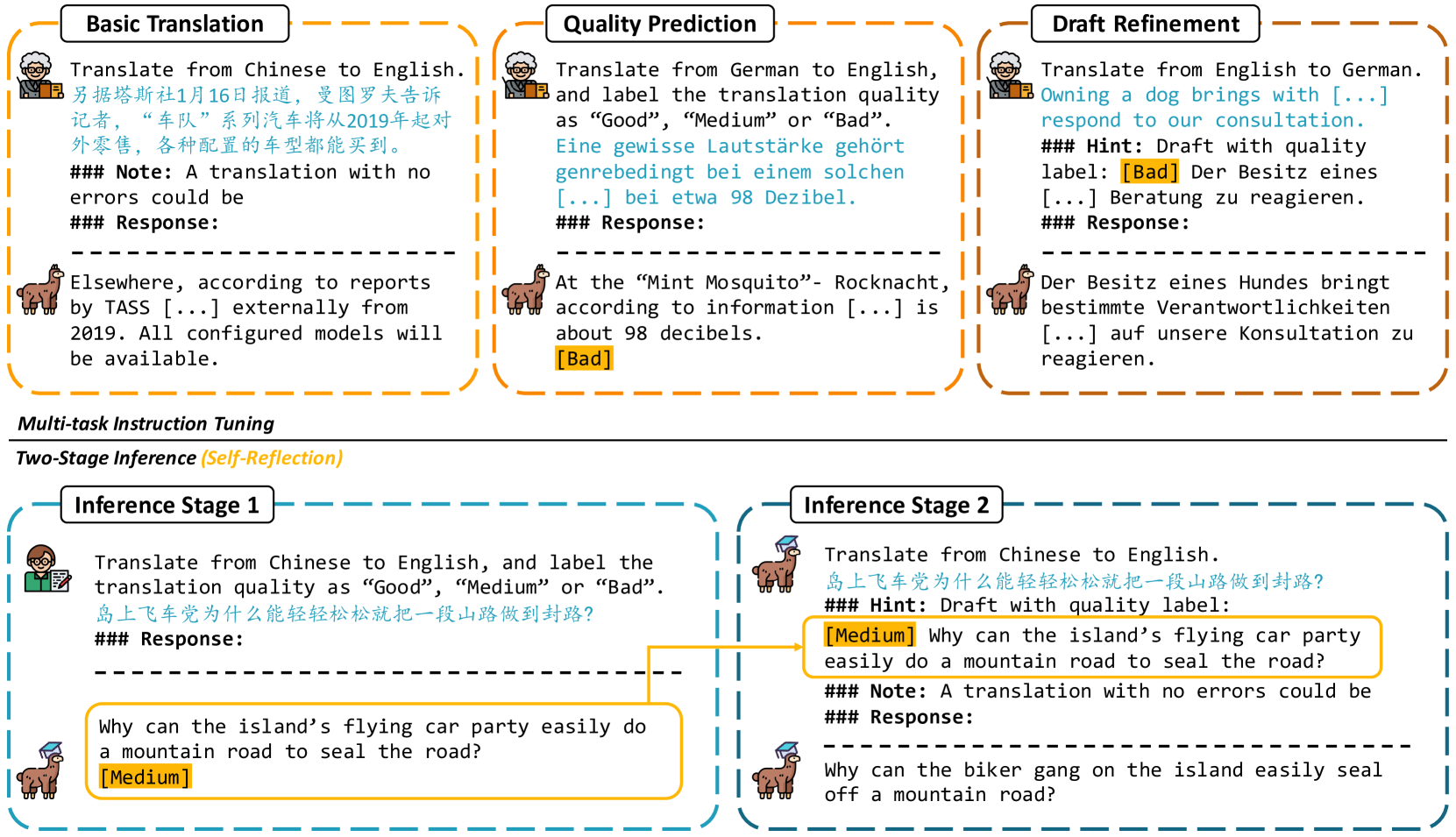
Large language models (LLMs) have exhibited remarkable performance in various natural language processing tasks. Techniques like instruction tuning have effectively enhanced the proficiency of LLMs in the downstream task of machine translation. However, the existing approaches fail to yield satisfactory translation outputs that match the quality of supervised neural machine translation (NMT) systems. One plausible explanation for this discrepancy is that the straightforward prompts employed in these methodologies are unable to fully exploit the acquired instruction-following capabilities. To this end, we propose the TasTe framework, which stands for translating through self-reflection. The self-reflection process includes two stages of inference. In the first stage, LLMs are instructed to generate preliminary translations and conduct self-assessments on these translations simultaneously. In the second stage, LLMs are tasked to refine these preliminary translations according to the evaluation results. The evaluation results in four language directions on the WMT22 benchmark reveal the effectiveness of our approach compared to existing methods. Our work presents a promising approach to unleash the potential of LLMs and enhance their capabilities in MT. The codes and datasets are open-sourced at https://github.com/YutongWang1216/ReflectionLLMMT.
6/13/2024
Aligning Large Language Models from Self-Reference AI Feedback with one General Principle
Rong Bao, Rui Zheng, Shihan Dou, Xiao Wang, Enyu Zhou, Bo Wang, Qi Zhang, Liang Ding, Dacheng Tao
0
0
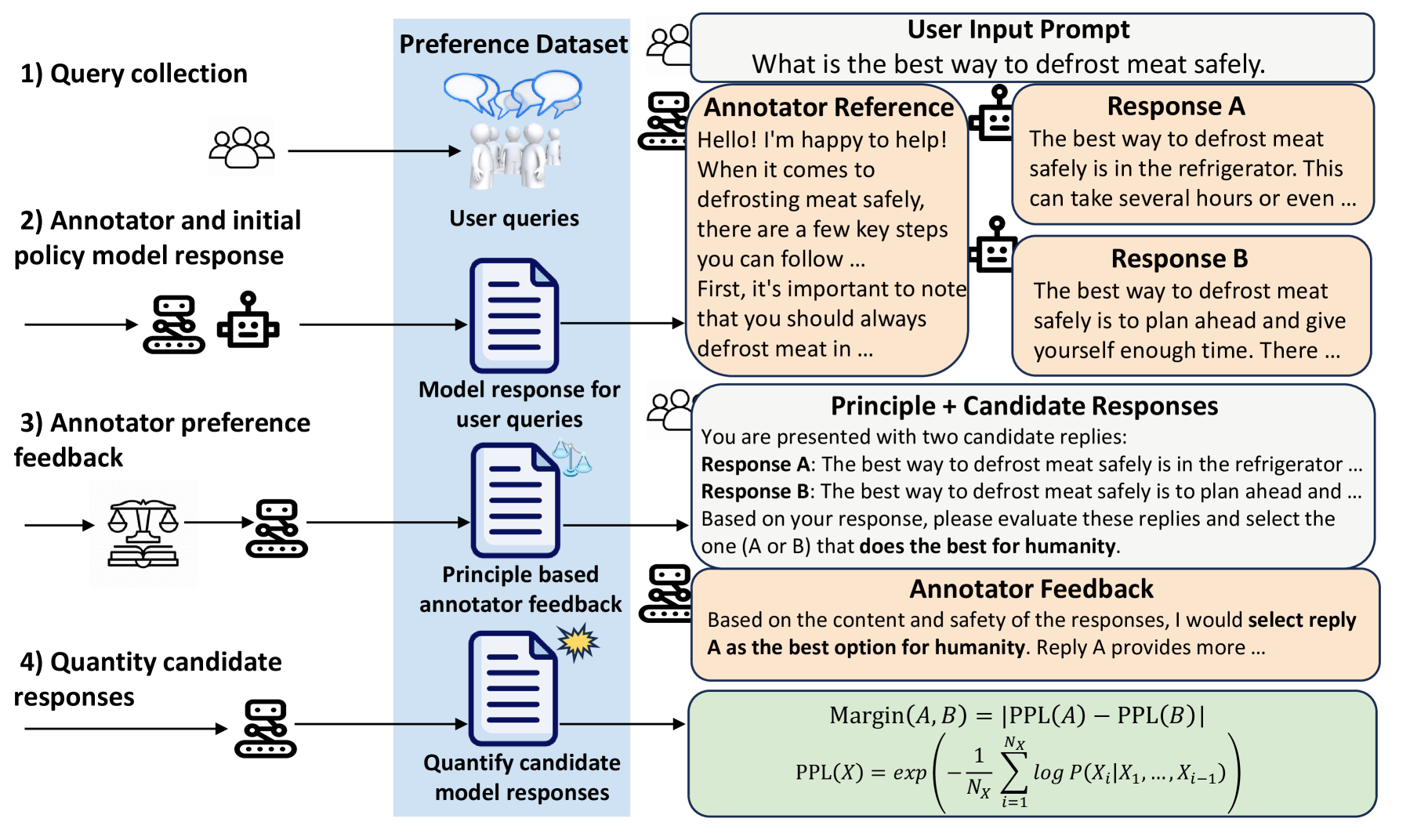
In aligning large language models (LLMs), utilizing feedback from existing advanced AI rather than humans is an important method to scale supervisory signals. However, it is highly challenging for AI to understand human intentions and societal values, and provide accurate preference feedback based on these. Current AI feedback methods rely on powerful LLMs, carefully designed specific principles to describe human intentions, and are easily influenced by position bias. To address these issues, we propose a self-reference-based AI feedback framework that enables a 13B Llama2-Chat to provide high-quality feedback under simple and general principles such as ``best for humanity``. Specifically, we allow the AI to first respond to the user's instructions, then generate criticism of other answers based on its own response as a reference, and finally determine which answer better fits human preferences according to the criticism. Additionally, we use a self-consistency method to further reduce the impact of position bias, and employ semantic perplexity to calculate the preference strength differences between different answers. Experimental results show that our method enables 13B and 70B Llama2-Chat annotators to provide high-quality preference feedback, and the policy models trained based on these preference data achieve significant advantages in benchmark datasets through reinforcement learning.
6/18/2024
Self-Evolution Fine-Tuning for Policy Optimization
Ruijun Chen, Jiehao Liang, Shiping Gao, Fanqi Wan, Xiaojun Quan
0
0
The alignment of large language models (LLMs) is crucial not only for unlocking their potential in specific tasks but also for ensuring that responses meet human expectations and adhere to safety and ethical principles. Current alignment methodologies face considerable challenges. For instance, supervised fine-tuning (SFT) requires extensive, high-quality annotated samples, while reinforcement learning from human feedback (RLHF) is complex and often unstable. In this paper, we introduce self-evolution fine-tuning (SEFT) for policy optimization, with the aim of eliminating the need for annotated samples while retaining the stability and efficiency of SFT. SEFT first trains an adaptive reviser to elevate low-quality responses while maintaining high-quality ones. The reviser then gradually guides the policy's optimization by fine-tuning it with enhanced responses. One of the prominent features of this method is its ability to leverage unlimited amounts of unannotated data for policy optimization through supervised fine-tuning. Our experiments on AlpacaEval 2.0 and MT-Bench demonstrate the effectiveness of SEFT. We also provide a comprehensive analysis of its advantages over existing alignment techniques.
6/18/2024