Self-Guiding Exploration for Combinatorial Problems
2405.17950
0
0
Abstract
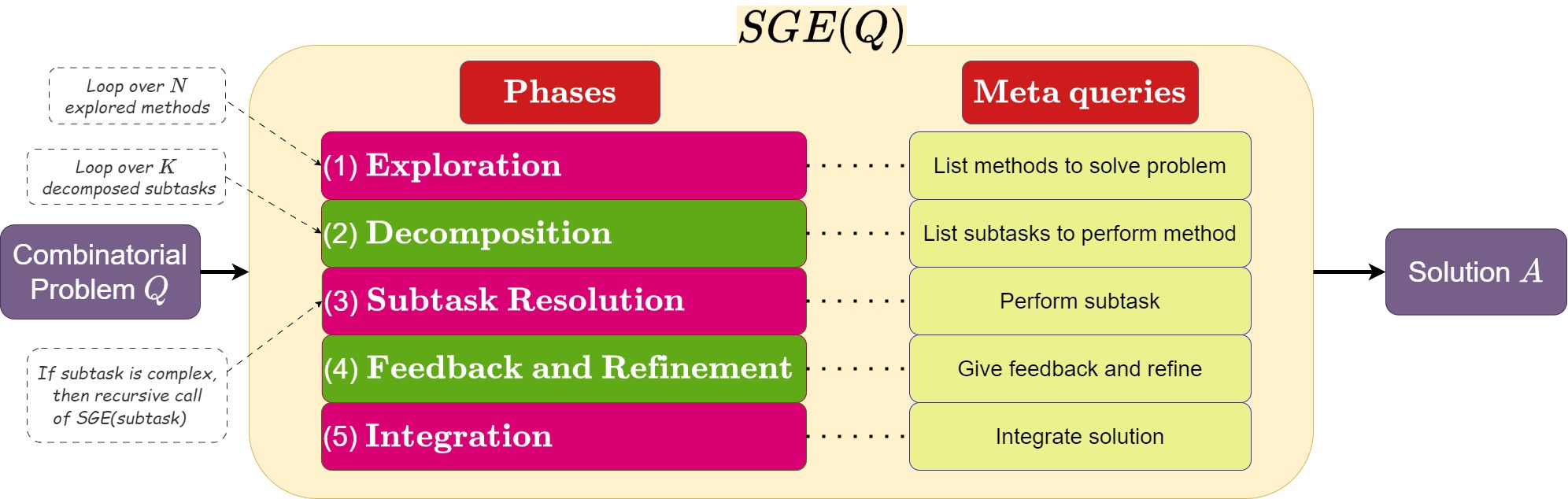
Large Language Models (LLMs) have become pivotal in addressing reasoning tasks across diverse domains, including arithmetic, commonsense, and symbolic reasoning. They utilize prompting techniques such as Exploration-of-Thought, Decomposition, and Refinement to effectively navigate and solve intricate tasks. Despite these advancements, the application of LLMs to Combinatorial Problems (CPs), known for their NP-hardness and critical roles in logistics and resource management remains underexplored. To address this gap, we introduce a novel prompting strategy: Self-Guiding Exploration (SGE), designed to enhance the performance of solving CPs. SGE operates autonomously, generating multiple thought trajectories for each CP task. It then breaks these trajectories down into actionable subtasks, executes them sequentially, and refines the results to ensure optimal outcomes. We present our research as the first to apply LLMs to a broad range of CPs and demonstrate that SGE outperforms existing prompting strategies by over 27.84% in CP optimization performance. Additionally, SGE achieves a 2.46% higher accuracy over the best existing results in other reasoning tasks (arithmetic, commonsense, and symbolic).
Create account to get full access
Overview
- This paper explores a novel approach for solving combinatorial problems using large language models (LLMs) called "Self-Guiding Exploration".
- The key idea is to enable LLMs to guide their own exploration of the solution space, rather than relying on human-provided prompts or heuristics.
- The authors propose several techniques, including Plan-Thoughts, Imagination Searching, and Comm, to empower LLMs to independently discover solutions to complex combinatorial problems.
- The paper presents experimental results demonstrating the effectiveness of the Self-Guiding Exploration approach on a range of combinatorial optimization tasks.
Plain English Explanation
The paper explores new ways for large language models (LLMs) to solve complex combinatorial problems on their own, without relying too much on human guidance. Combinatorial problems are like puzzles where you have to find the best arrangement or combination of things, and they can be really hard for computers to solve.
The key idea is to give the LLMs more autonomy and flexibility in how they explore the possible solutions. Instead of just following instructions or using predefined heuristics, the LLMs can guide their own exploration of the solution space. This is done through techniques like Plan-Thoughts, where the LLM plans out a series of steps to reach a solution, Imagination Searching, where the LLM imagines different possible solutions, and Comm, where multiple LLMs work together to find solutions.
The paper shows that this "self-guiding" approach can be effective at solving a variety of combinatorial optimization problems, where the LLMs are able to discover good solutions on their own without as much human intervention. This could be really useful for tackling complex real-world problems in areas like logistics, scheduling, and resource allocation.
Technical Explanation
The paper introduces a novel approach called "Self-Guiding Exploration" for solving combinatorial problems using large language models (LLMs). The key idea is to empower LLMs to guide their own exploration of the solution space, rather than relying solely on human-provided prompts or heuristics.
The authors propose several techniques to enable this self-guiding exploration:
- Plan-Thoughts: The LLM generates a step-by-step plan to reach a solution, reasoning about its own thought process.
- Imagination Searching: The LLM imagines and evaluates different possible solutions, honing in on promising ones.
- Comm: Multiple LLMs collaborate, sharing their individual explorations and insights to collectively discover solutions.
The paper presents experimental results on a range of combinatorial optimization tasks, including the Traveling Salesman Problem, the Knapsack Problem, and the Job Shop Scheduling Problem. The results demonstrate that the Self-Guiding Exploration approach can outperform traditional approaches that rely more heavily on human-provided guidance.
Critical Analysis
The paper presents a promising direction for empowering LLMs to solve complex combinatorial problems more autonomously. The proposed techniques, such as Plan-Thoughts, Imagination Searching, and Comm, seem well-designed to enable LLMs to guide their own exploration of the solution space.
However, the paper does not address some potential limitations and avenues for further research. For example, it is unclear how the self-guiding exploration techniques would scale to larger, more complex combinatorial problems, or how they would perform in the presence of noisy or incomplete information. Additionally, the paper does not explore the potential for incorporating general-purpose verification techniques to ensure the reliability and robustness of the LLM's solutions.
Further research could also investigate the synergies between the self-guiding exploration techniques and other approaches, such as the use of domain-specific knowledge or the integration of traditional optimization algorithms, to create more comprehensive and effective combinatorial problem-solving frameworks.
Conclusion
The paper presents a novel approach called "Self-Guiding Exploration" that empowers large language models (LLMs) to solve complex combinatorial problems more autonomously. By equipping LLMs with techniques like Plan-Thoughts, Imagination Searching, and Comm, the authors demonstrate the effectiveness of this self-guiding approach on a range of combinatorial optimization tasks.
This research represents an important step forward in empowering LLMs to tackle complex, real-world problems with less reliance on human guidance. As the capabilities of LLMs continue to grow, techniques like Self-Guiding Exploration could pave the way for more autonomous and versatile problem-solving systems, with applications spanning logistics, scheduling, resource allocation, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏷️
Navigating the Labyrinth: Evaluating and Enhancing LLMs' Ability to Reason About Search Problems
Nasim Borazjanizadeh, Roei Herzig, Trevor Darrell, Rogerio Feris, Leonid Karlinsky
0
0
Recently, Large Language Models (LLMs) attained impressive performance in math and reasoning benchmarks. However, they still often struggle with logic problems and puzzles that are relatively easy for humans. To further investigate this, we introduce a new benchmark, SearchBench, containing 11 unique search problem types, each equipped with automated pipelines to generate an arbitrary number of instances and analyze the feasibility, correctness, and optimality of LLM-generated solutions. We show that even the most advanced LLMs fail to solve these problems end-to-end in text, e.g. GPT4 solves only 1.4%. SearchBench problems require considering multiple pathways to the solution as well as backtracking, posing a significant challenge to auto-regressive models. Instructing LLMs to generate code that solves the problem helps, but only slightly, e.g., GPT4's performance rises to 11.7%. In this work, we show that in-context learning with A* algorithm implementations enhances performance. The full potential of this promoting approach emerges when combined with our proposed Multi-Stage-Multi-Try method, which breaks down the algorithm implementation into two stages and verifies the first stage against unit tests, raising GPT-4's performance above 57%.
6/19/2024
💬
Exploring Combinatorial Problem Solving with Large Language Models: A Case Study on the Travelling Salesman Problem Using GPT-3.5 Turbo
Mahmoud Masoud, Ahmed Abdelhay, Mohammed Elhenawy
0
0
Large Language Models (LLMs) are deep learning models designed to generate text based on textual input. Although researchers have been developing these models for more complex tasks such as code generation and general reasoning, few efforts have explored how LLMs can be applied to combinatorial problems. In this research, we investigate the potential of LLMs to solve the Travelling Salesman Problem (TSP). Utilizing GPT-3.5 Turbo, we conducted experiments employing various approaches, including zero-shot in-context learning, few-shot in-context learning, and chain-of-thoughts (CoT). Consequently, we fine-tuned GPT-3.5 Turbo to solve a specific problem size and tested it using a set of various instance sizes. The fine-tuned models demonstrated promising performance on problems identical in size to the training instances and generalized well to larger problems. Furthermore, to improve the performance of the fine-tuned model without incurring additional training costs, we adopted a self-ensemble approach to improve the quality of the solutions.
5/6/2024
💬
Plan of Thoughts: Heuristic-Guided Problem Solving with Large Language Models
Houjun Liu
0
0
While language models (LMs) offer significant capability in zero-shot reasoning tasks across a wide range of domains, they do not perform satisfactorily in problems which requires multi-step reasoning. Previous approaches to mitigate this involves breaking a larger, multi-step task into sub-tasks and asking the language model to generate proposals (thoughts) for each sub-task and using exhaustive planning approaches such as DFS to compose a solution. In this work, we leverage this idea to introduce two new contributions: first, we formalize a planning-based approach to perform multi-step problem solving with LMs via Partially Observable Markov Decision Processes (POMDPs), with the LM's own reflections about the value of a state used as a search heuristic; second, leveraging the online POMDP solver POMCP, we demonstrate a superior success rate of 89.4% on the Game of 24 task as compared to existing approaches while also offering better anytime performance characteristics than fixed tree-search which is used previously. Taken together, these contributions allow modern LMs to decompose and solve larger-scale reasoning tasks more effectively.
5/1/2024
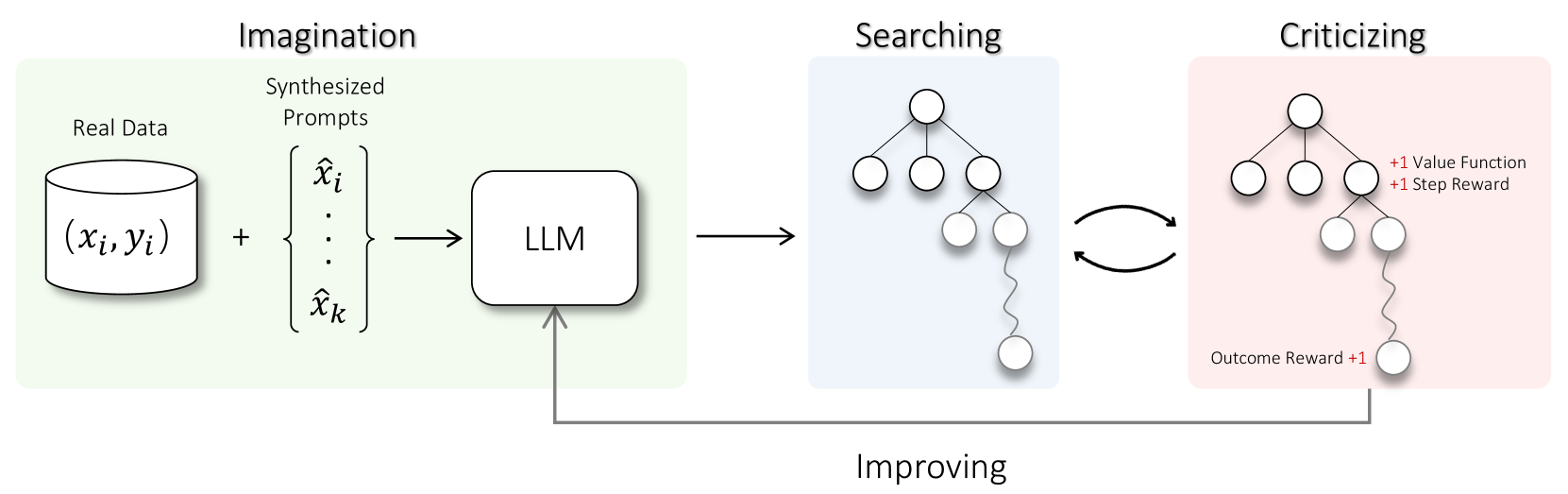
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
0
0
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
4/19/2024