A Survey on Self-play Methods in Reinforcement Learning

0

Sign in to get full access
Overview
- Provides a comprehensive survey of self-play methods in reinforcement learning
- Discusses the core ideas, key components, and applications of self-play techniques
- Analyzes the benefits, challenges, and future research directions in this field
Plain English Explanation
Self-play is a technique used in reinforcement learning where an agent learns by playing against itself. This allows the agent to explore different strategies and improve its skills over time without the need for external feedback or supervision.
The paper provides a thorough overview of self-play methods, explaining how they work and their various applications. Self-play can be particularly useful for training agents in complex, dynamic environments where traditional learning methods may struggle.
By playing against itself, the agent can develop a deeper understanding of the problem domain and discover novel solutions. This can lead to more robust and versatile AI systems that can adapt to changing conditions and handle a wider range of tasks.
The paper also discusses the potential challenges and limitations of self-play, such as the risk of the agent converging to suboptimal strategies or exhibiting undesirable behaviors. Addressing these issues is an important area of ongoing research in the field.
Technical Explanation
The paper starts by providing an overview of reinforcement learning and the concept of self-play. It then delves into the key components of self-play methods, including the training algorithm, the environment setup, and the reward shaping.
The authors discuss various self-play approaches, such as opponent modeling, population-based training, and multi-agent learning. They analyze the strengths and weaknesses of each approach, as well as their applications in different domains, such as game-playing, robotics, and language modeling.
The paper also explores the theoretical underpinnings of self-play, drawing connections to concepts like Nash equilibria and multi-agent learning. It provides insights into the convergence properties and stability of self-play algorithms, as well as the role of exploration and exploitation in the learning process.
Critical Analysis
The paper provides a comprehensive and well-structured overview of self-play methods in reinforcement learning. The authors have done an excellent job of highlighting the core ideas, key components, and diverse applications of this technique.
One potential limitation of the survey is that it does not delve deeply into the specific challenges and limitations of self-play. While the authors do mention some of the potential issues, such as the risk of converging to suboptimal strategies, a more thorough discussion of these challenges and potential solutions would have been valuable.
Additionally, the paper could have explored the ethical considerations and potential societal implications of self-play methods, particularly as they relate to the development of more powerful and autonomous AI systems. This is an important aspect that deserves careful attention as the field of reinforcement learning continues to advance.
Conclusion
This survey paper offers a detailed and insightful exploration of self-play methods in reinforcement learning. By providing a comprehensive overview of the core concepts, key components, and various applications of this technique, the authors have made a valuable contribution to the understanding and advancement of this field.
The insights and discussions presented in the paper can serve as a valuable resource for researchers, practitioners, and anyone interested in the development of more capable and adaptable AI systems. As the field continues to evolve, the lessons and perspectives shared in this survey will be crucial in guiding future research and shaping the future of reinforcement learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Survey on Self-play Methods in Reinforcement Learning
Ruize Zhang, Zelai Xu, Chengdong Ma, Chao Yu, Wei-Wei Tu, Shiyu Huang, Deheng Ye, Wenbo Ding, Yaodong Yang, Yu Wang
Self-play, characterized by agents' interactions with copies or past versions of itself, has recently gained prominence in reinforcement learning. This paper first clarifies the preliminaries of self-play, including the multi-agent reinforcement learning framework and basic game theory concepts. Then it provides a unified framework and classifies existing self-play algorithms within this framework. Moreover, the paper bridges the gap between the algorithms and their practical implications by illustrating the role of self-play in different scenarios. Finally, the survey highlights open challenges and future research directions in self-play. This paper is an essential guide map for understanding the multifaceted landscape of self-play in RL.
Read more8/6/2024
0
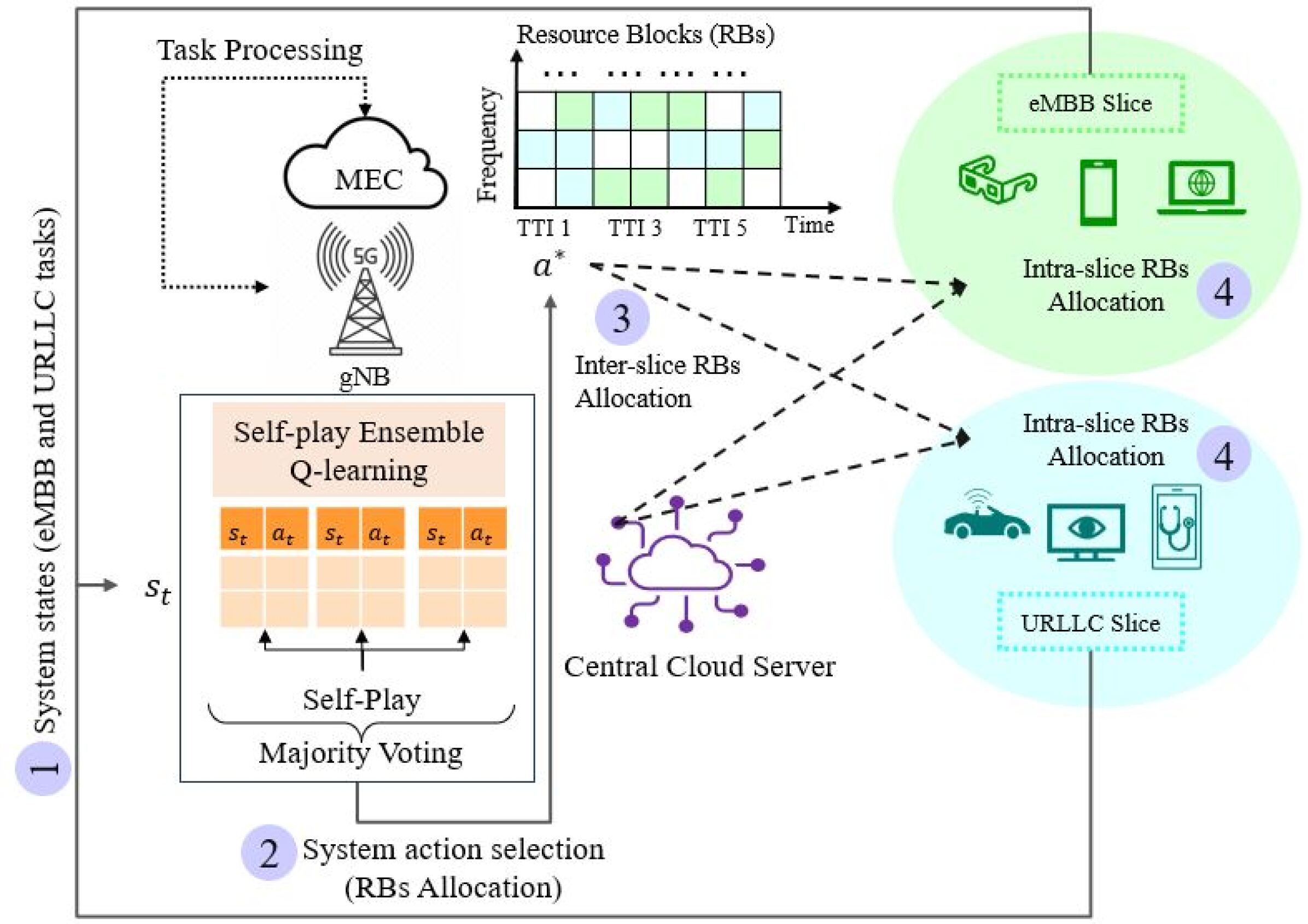
Self-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing
Shavbo Salehi, Pedro Enrique Iturria-Rivera, Medhat Elsayed, Majid Bavand, Raimundas Gaigalas, Yigit Ozcan, Melike Erol-Kantarci
In 5G networks, network slicing has emerged as a pivotal paradigm to address diverse user demands and service requirements. To meet the requirements, reinforcement learning (RL) algorithms have been utilized widely, but this method has the problem of overestimation and exploration-exploitation trade-offs. To tackle these problems, this paper explores the application of self-play ensemble Q-learning, an extended version of the RL-based technique. Self-play ensemble Q-learning utilizes multiple Q-tables with various exploration-exploitation rates leading to different observations for choosing the most suitable action for each state. Moreover, through self-play, each model endeavors to enhance its performance compared to its previous iterations, boosting system efficiency, and decreasing the effect of overestimation. For performance evaluation, we consider three RL-based algorithms; self-play ensemble Q-learning, double Q-learning, and Q-learning, and compare their performance under different network traffic. Through simulations, we demonstrate the effectiveness of self-play ensemble Q-learning in meeting the diverse demands within 21.92% in latency, 24.22% in throughput, and 23.63% in packet drop rate in comparison with the baseline methods. Furthermore, we evaluate the robustness of self-play ensemble Q-learning and double Q-learning in situations where one of the Q-tables is affected by a malicious user. Our results depicted that the self-play ensemble Q-learning method is more robust against adversarial users and prevents a noticeable drop in system performance, mitigating the impact of users manipulating policies.
Read more8/21/2024
🏅
0
A Review of Safe Reinforcement Learning: Methods, Theory and Applications
Shangding Gu, Long Yang, Yali Du, Guang Chen, Florian Walter, Jun Wang, Alois Knoll
Reinforcement Learning (RL) has achieved tremendous success in many complex decision-making tasks. However, safety concerns are raised during deploying RL in real-world applications, leading to a growing demand for safe RL algorithms, such as in autonomous driving and robotics scenarios. While safe control has a long history, the study of safe RL algorithms is still in the early stages. To establish a good foundation for future safe RL research, in this paper, we provide a review of safe RL from the perspectives of methods, theories, and applications. Firstly, we review the progress of safe RL from five dimensions and come up with five crucial problems for safe RL being deployed in real-world applications, coined as 2H3W. Secondly, we analyze the algorithm and theory progress from the perspectives of answering the 2H3W problems. Particularly, the sample complexity of safe RL algorithms is reviewed and discussed, followed by an introduction to the applications and benchmarks of safe RL algorithms. Finally, we open the discussion of the challenging problems in safe RL, hoping to inspire future research on this thread. To advance the study of safe RL algorithms, we release an open-sourced repository containing the implementations of major safe RL algorithms at the link: https://github.com/chauncygu/Safe-Reinforcement-Learning-Baselines.git.
Read more5/28/2024

0
Multi-Agent Reinforcement Learning for Autonomous Driving: A Survey
Ruiqi Zhang, Jing Hou, Florian Walter, Shangding Gu, Jiayi Guan, Florian Rohrbein, Yali Du, Panpan Cai, Guang Chen, Alois Knoll
Reinforcement Learning (RL) is a potent tool for sequential decision-making and has achieved performance surpassing human capabilities across many challenging real-world tasks. As the extension of RL in the multi-agent system domain, multi-agent RL (MARL) not only need to learn the control policy but also requires consideration regarding interactions with all other agents in the environment, mutual influences among different system components, and the distribution of computational resources. This augments the complexity of algorithmic design and poses higher requirements on computational resources. Simultaneously, simulators are crucial to obtain realistic data, which is the fundamentals of RL. In this paper, we first propose a series of metrics of simulators and summarize the features of existing benchmarks. Second, to ease comprehension, we recall the foundational knowledge and then synthesize the recently advanced studies of MARL-related autonomous driving and intelligent transportation systems. Specifically, we examine their environmental modeling, state representation, perception units, and algorithm design. Conclusively, we discuss open challenges as well as prospects and opportunities. We hope this paper can help the researchers integrate MARL technologies and trigger more insightful ideas toward the intelligent and autonomous driving.
Read more8/20/2024