Smart Sampling: Self-Attention and Bootstrapping for Improved Ensembled Q-Learning

0
🔄
Sign in to get full access
Overview
- The researchers present a new method to improve the sample efficiency of ensemble Q-learning, a reinforcement learning technique.
- Their approach integrates multi-head self-attention into the ensemble of Q-networks and bootstraps the state-action pairs used by the ensemble.
- This leads to performance improvements over previous methods like REDQ and DroQ, and also reduces the bias and variance within the Q-function ensemble.
- The method works well even with a low update-to-data ratio, and is straightforward to implement with minimal changes to the base model.
Plain English Explanation
The paper describes a novel way to make reinforcement learning techniques more efficient at learning from a limited amount of data. The key idea is to use an "ensemble" of neural networks, each of which is trying to learn the optimal actions to take in different situations.
To improve this ensemble approach, the researchers integrate a technique called "multi-head self-attention" link. This helps the ensemble better understand the relationships between different situations and actions. They also "bootstrap" the data used to train each network in the ensemble, which means reusing and recombining the data in smart ways.
These innovations lead to the ensemble making better predictions of the optimal actions, with less bias and variability between the different networks. Importantly, this method works well even when there is a limited amount of training data available, which is a common challenge in reinforcement learning link.
Overall, this research advances the state-of-the-art in reinforcement learning by making the techniques more sample-efficient and robust, with the potential to enable better real-world applications link link.
Technical Explanation
The paper presents a novel approach called "Attention-Bootstrapped Ensemble Q-Learning" (ABEQ) that builds on the REDQ and DroQ methods for ensemble-based reinforcement learning.
The key innovations are:
-
Integrating multi-head self-attention into the ensembled Q-networks. This allows the ensemble to better capture relationships between different states and actions.
-
Bootstrapping the state-action pairs used to train each network in the ensemble. This reuses and recombines the data in strategic ways to improve sample efficiency.
The researchers evaluate ABEQ on several benchmark reinforcement learning tasks and compare it to the previous REDQ and DroQ methods. They show that ABEQ achieves superior performance, with lower average normalized bias and standard deviation of normalized bias within the Q-function ensemble.
Importantly, ABEQ maintains strong performance even in scenarios with a low update-to-data (UTD) ratio, indicating its robustness to limited data availability link link.
Critical Analysis
The paper provides a thorough evaluation of the ABEQ method and highlights its advantages over prior ensemble Q-learning approaches. However, the authors acknowledge some limitations:
- The experiments were conducted on a relatively small set of benchmark tasks, so further validation on a wider range of environments would be beneficial.
- The computational and memory overhead of the multi-head self-attention mechanism is not discussed in depth, which could be an important practical consideration.
- While the method performs well with low UTD ratios, the specific factors that contribute to this robustness are not fully explored.
Additionally, one could question whether the improvements offered by ABEQ justify the added complexity, compared to simpler ensemble methods. Further research may be needed to assess the tradeoffs and determine the most appropriate use cases.
Overall, this work represents a valuable contribution to the field of reinforcement learning, but as with any research, there is room for continued refinement and exploration of the ideas presented.
Conclusion
The researchers have developed a novel ensemble Q-learning method called ABEQ that enhances sample efficiency through the integration of multi-head self-attention and data bootstrapping. This approach outperforms previous ensemble techniques like REDQ and DroQ, while also reducing bias and variance within the Q-function ensemble.
Importantly, ABEQ maintains strong performance even in low data availability scenarios, suggesting its potential for real-world applications where sample efficiency is critical. The straightforward implementation and minimal changes required to the base model further contribute to the practicality of this method.
While the paper identifies some limitations, the core ideas presented here represent an important advancement in reinforcement learning and could inspire future research to push the boundaries of sample-efficient and robust decision-making systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Smart Sampling: Self-Attention and Bootstrapping for Improved Ensembled Q-Learning
Muhammad Junaid Khan, Syed Hammad Ahmed, Gita Sukthankar
We present a novel method aimed at enhancing the sample efficiency of ensemble Q learning. Our proposed approach integrates multi-head self-attention into the ensembled Q networks while bootstrapping the state-action pairs ingested by the ensemble. This not only results in performance improvements over the original REDQ (Chen et al. 2021) and its variant DroQ (Hi-raoka et al. 2022), thereby enhancing Q predictions, but also effectively reduces both the average normalized bias and standard deviation of normalized bias within Q-function ensembles. Importantly, our method also performs well even in scenarios with a low update-to-data (UTD) ratio. Notably, the implementation of our proposed method is straightforward, requiring minimal modifications to the base model.
Read more5/15/2024
0
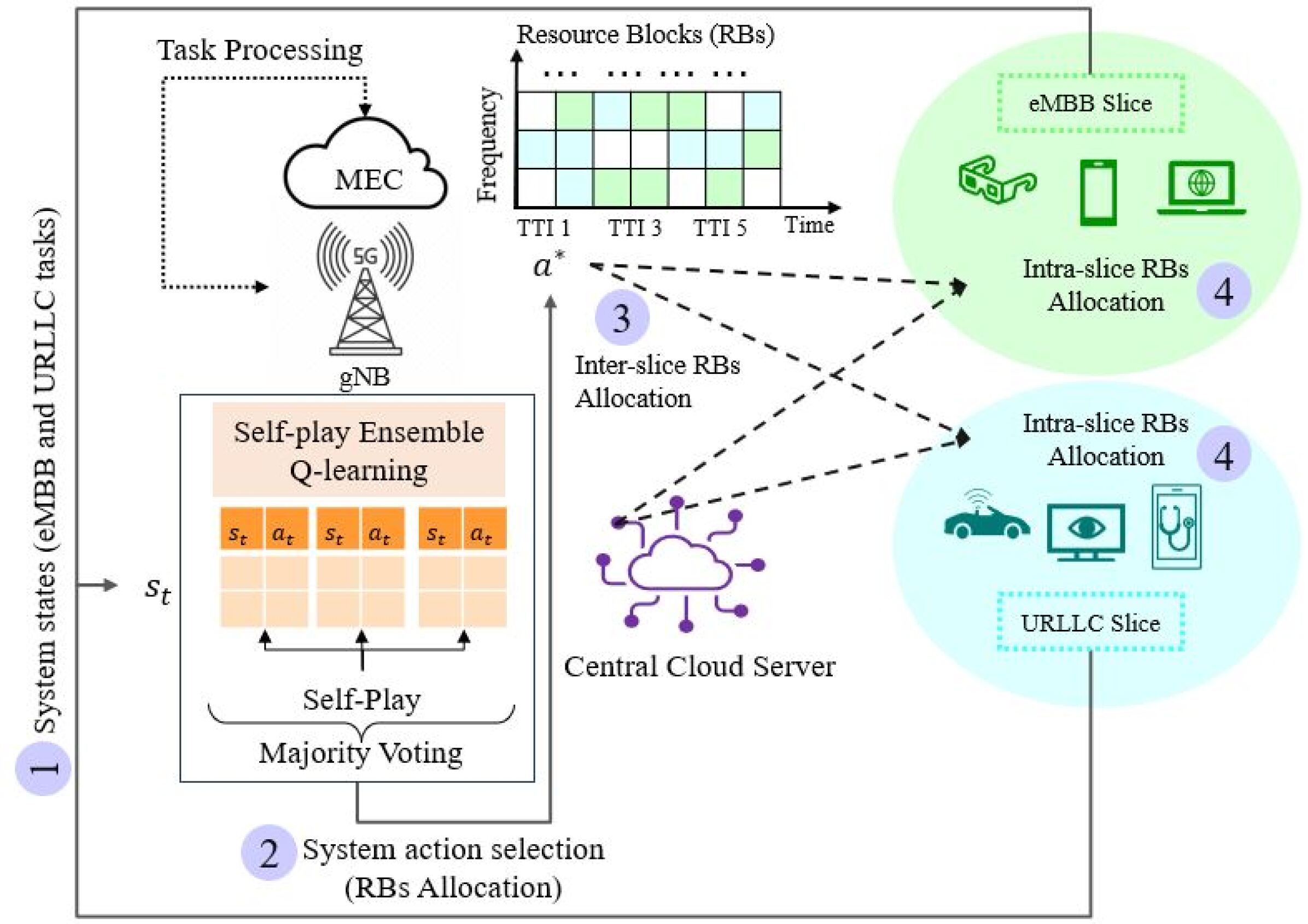
Self-Play Ensemble Q-learning enabled Resource Allocation for Network Slicing
Shavbo Salehi, Pedro Enrique Iturria-Rivera, Medhat Elsayed, Majid Bavand, Raimundas Gaigalas, Yigit Ozcan, Melike Erol-Kantarci
In 5G networks, network slicing has emerged as a pivotal paradigm to address diverse user demands and service requirements. To meet the requirements, reinforcement learning (RL) algorithms have been utilized widely, but this method has the problem of overestimation and exploration-exploitation trade-offs. To tackle these problems, this paper explores the application of self-play ensemble Q-learning, an extended version of the RL-based technique. Self-play ensemble Q-learning utilizes multiple Q-tables with various exploration-exploitation rates leading to different observations for choosing the most suitable action for each state. Moreover, through self-play, each model endeavors to enhance its performance compared to its previous iterations, boosting system efficiency, and decreasing the effect of overestimation. For performance evaluation, we consider three RL-based algorithms; self-play ensemble Q-learning, double Q-learning, and Q-learning, and compare their performance under different network traffic. Through simulations, we demonstrate the effectiveness of self-play ensemble Q-learning in meeting the diverse demands within 21.92% in latency, 24.22% in throughput, and 23.63% in packet drop rate in comparison with the baseline methods. Furthermore, we evaluate the robustness of self-play ensemble Q-learning and double Q-learning in situations where one of the Q-tables is affected by a malicious user. Our results depicted that the self-play ensemble Q-learning method is more robust against adversarial users and prevents a noticeable drop in system performance, mitigating the impact of users manipulating policies.
Read more8/21/2024
0
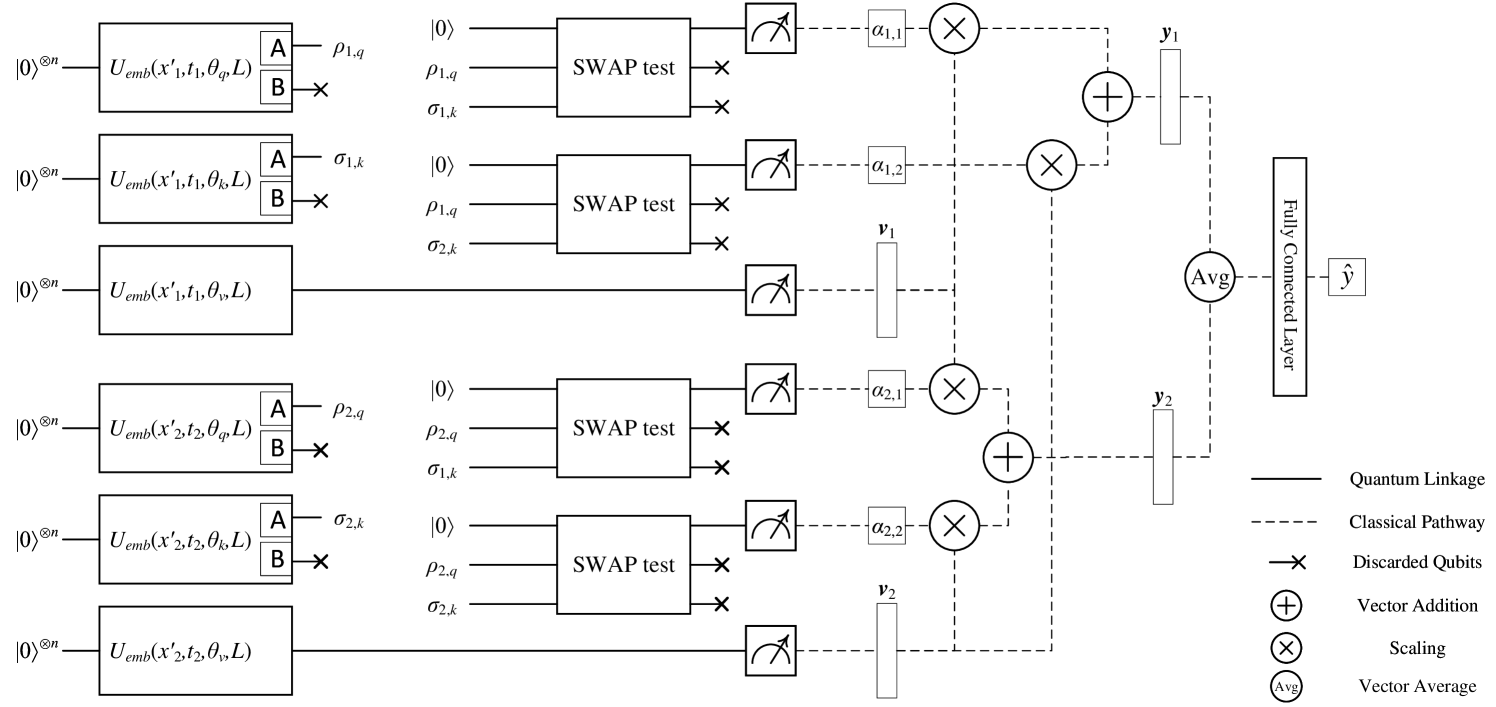
Quantum Mixed-State Self-Attention Network
Fu Chen, Qinglin Zhao, Li Feng, Chuangtao Chen, Yangbin Lin, Jianhong Lin
The rapid advancement of quantum computing has increasingly highlighted its potential in the realm of machine learning, particularly in the context of natural language processing (NLP) tasks. Quantum machine learning (QML) leverages the unique capabilities of quantum computing to offer novel perspectives and methodologies for complex data processing and pattern recognition challenges. This paper introduces a novel Quantum Mixed-State Attention Network (QMSAN), which integrates the principles of quantum computing with classical machine learning algorithms, especially self-attention networks, to enhance the efficiency and effectiveness in handling NLP tasks. QMSAN model employs a quantum attention mechanism based on mixed states, enabling efficient direct estimation of similarity between queries and keys within the quantum domain, leading to more effective attention weight acquisition. Additionally, we propose an innovative quantum positional encoding scheme, implemented through fixed quantum gates within the quantum circuit, to enhance the model's accuracy. Experimental validation on various datasets demonstrates that QMSAN model outperforms existing quantum and classical models in text classification, achieving significant performance improvements. QMSAN model not only significantly reduces the number of parameters but also exceeds classical self-attention networks in performance, showcasing its strong capability in data representation and information extraction. Furthermore, our study investigates the model's robustness in different quantum noise environments, showing that QMSAN possesses commendable robustness to low noise.
Read more6/11/2024
0
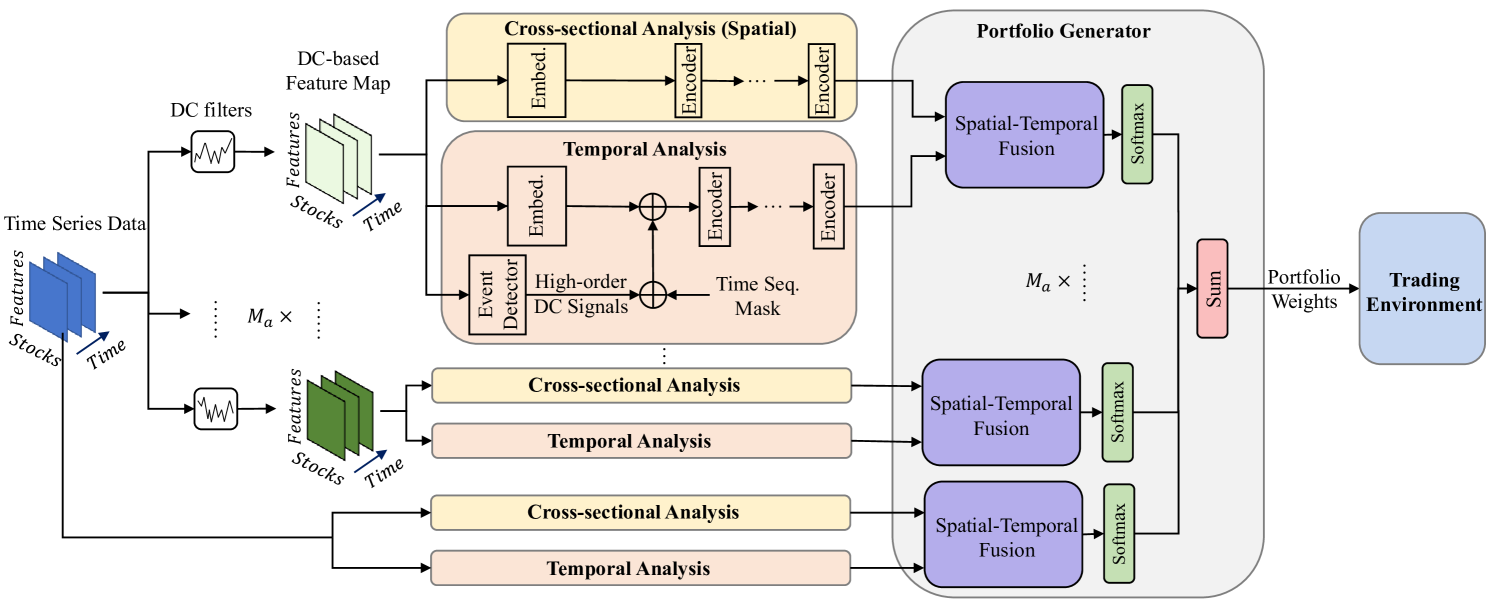
Developing An Attention-Based Ensemble Learning Framework for Financial Portfolio Optimisation
Zhenglong Li, Vincent Tam
In recent years, deep or reinforcement learning approaches have been applied to optimise investment portfolios through learning the spatial and temporal information under the dynamic financial market. Yet in most cases, the existing approaches may produce biased trading signals based on the conventional price data due to a lot of market noises, which possibly fails to balance the investment returns and risks. Accordingly, a multi-agent and self-adaptive portfolio optimisation framework integrated with attention mechanisms and time series, namely the MASAAT, is proposed in this work in which multiple trading agents are created to observe and analyse the price series and directional change data that recognises the significant changes of asset prices at different levels of granularity for enhancing the signal-to-noise ratio of price series. Afterwards, by reconstructing the tokens of financial data in a sequence, the attention-based cross-sectional analysis module and temporal analysis module of each agent can effectively capture the correlations between assets and the dependencies between time points. Besides, a portfolio generator is integrated into the proposed framework to fuse the spatial-temporal information and then summarise the portfolios suggested by all trading agents to produce a newly ensemble portfolio for reducing biased trading actions and balancing the overall returns and risks. The experimental results clearly demonstrate that the MASAAT framework achieves impressive enhancement when compared with many well-known portfolio optimsation approaches on three challenging data sets of DJIA, S&P 500 and CSI 300. More importantly, our proposal has potential strengths in many possible applications for future study.
Read more4/16/2024