Self-Supervised Learning of Visual Servoing for Low-Rigidity Robots Considering Temporal Body Changes

0

Sign in to get full access
Overview
- This paper presents a self-supervised learning approach for visual servoing of low-rigidity robots, which accounts for temporal changes in the robot's body structure.
- Visual servoing is the process of using visual feedback to control the motion of a robot, and it is particularly challenging for low-rigidity robots, which can undergo significant shape changes over time.
- The proposed method learns to predict the robot's future visual observations and uses this information to control the robot's movements, without requiring explicit knowledge of the robot's changing body structure.
Plain English Explanation
The paper discusses a new way for robots to learn how to control their own movements using visual feedback, even as the robot's body shape changes over time. This is an important challenge for "low-rigidity" robots, which can bend and deform, unlike more rigid, traditional robots.
The key idea is that the robot can learn to predict what its future visual observations will look like, based on its current state and actions. By learning this predictive model in a self-supervised way (without human labels), the robot can then use this information to control its movements and complete tasks, without needing to explicitly model the changing shape of its own body.
This approach is useful because low-rigidity robots can be more versatile and adaptable than traditional robots, but their changing shapes make them harder to control. By learning to predict its own visual observations, the robot can adapt to these changes and still accomplish its goals through visual feedback, without relying on a pre-designed model of its body.
Technical Explanation
The paper proposes a self-supervised learning framework for visual servoing of low-rigidity robots. The key components are:
- Temporal Body Modeling: The robot learns a predictive model that can forecast its future visual observations based on its current state and actions, accounting for changes in its body structure over time.
- Visual Servoing: Using the learned predictive model, the robot can then plan control actions that will drive the robot towards a desired visual goal, without needing an explicit model of its changing kinematics.
- Self-Supervision: The robot collects its own training data by executing random actions and observing the resulting visual changes, allowing it to learn the predictive model in a self-supervised manner.
The authors evaluate their approach on a simulated low-rigidity robot performing reach and push tasks, and show that it can outperform baselines that do not account for temporal body changes.
Critical Analysis
The paper presents a promising approach for visual servoing of low-rigidity robots, which addresses an important challenge in the field of robotics. By learning to predict the robot's future visual observations, the method can adapt to changes in the robot's body structure over time, without requiring explicit modeling of these changes.
However, the paper does not discuss the potential limitations of this approach. For example, it is unclear how well the method would scale to more complex low-rigidity robots with a larger number of degrees of freedom, or how sensitive the performance is to the quality and quantity of the self-supervised training data.
Additionally, the paper does not consider the challenges of grasping unknown objects with a low-rigidity robot, which may require further extensions to the proposed approach.
Overall, the paper makes an important contribution by demonstrating the feasibility of self-supervised visual servoing for low-rigidity robots, but more research is needed to fully understand the capabilities and limitations of this approach.
Conclusion
This paper presents a novel self-supervised learning framework for visual servoing of low-rigidity robots, which can account for temporal changes in the robot's body structure. By learning to predict the robot's future visual observations, the method can adapt to these changes and control the robot's movements without an explicit model of its kinematics.
The proposed approach represents a promising step towards more versatile and adaptable robotic systems, which can overcome the challenges posed by low-rigidity bodies. While the paper demonstrates the potential of this method, further research is needed to explore its scalability, robustness, and applicability to real-world scenarios involving unknown objects and complex kinematic constraints.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Learning of Visual Servoing for Low-Rigidity Robots Considering Temporal Body Changes
Kento Kawaharazuka, Naoaki Kanazawa, Kei Okada, Masayuki Inaba
In this study, we investigate object grasping by visual servoing in a low-rigidity robot. It is difficult for a low-rigidity robot to handle its own body as intended compared to a rigid robot, and calibration between vision and body takes some time. In addition, the robot must constantly adapt to changes in its body, such as the change in camera position and change in joints due to aging. Therefore, we develop a method for a low-rigidity robot to autonomously learn visual servoing of its body. We also develop a mechanism that can adaptively change its visual servoing according to temporal body changes. We apply our method to a low-rigidity 6-axis arm, MyCobot, and confirm its effectiveness by conducting object grasping experiments based on visual servoing.
Read more5/21/2024

0
Adaptive Whole-body Robotic Tool-use Learning on Low-rigidity Plastic-made Humanoids Using Vision and Tactile Sensors
Kento Kawaharazuka, Kei Okada, Masayuki Inaba
Various robots have been developed so far; however, we face challenges in modeling the low-rigidity bodies of some robots. In particular, the deflection of the body changes during tool-use due to object grasping, resulting in significant shifts in the tool-tip position and the body's center of gravity. Moreover, this deflection varies depending on the weight and length of the tool, making these models exceptionally complex. However, there is currently no control or learning method that takes all of these effects into account. In this study, we propose a method for constructing a neural network that describes the mutual relationship among joint angle, visual information, and tactile information from the feet. We aim to train this network using the actual robot data and utilize it for tool-tip control. Additionally, we employ Parametric Bias to capture changes in this mutual relationship caused by variations in the weight and length of tools, enabling us to understand the characteristics of the grasped tool from the current sensor information. We apply this approach to the whole-body tool-use on KXR, a low-rigidity plastic-made humanoid robot, to validate its effectiveness.
Read more5/9/2024

0
Robot Agnostic Visual Servoing considering kinematic constraints enabled by a decoupled network trajectory planner structure
Constantin Schempp, Christian Friedrich
We propose a visual servoing method consisting of a detection network and a velocity trajectory planner. First, the detection network estimates the objects position and orientation in the image space. Furthermore, these are normalized and filtered. The direction and orientation is then the input to the trajectory planner, which considers the kinematic constrains of the used robotic system. This allows safe and stable control, since the kinematic boundary values are taken into account in planning. Also, by having direction estimation and velocity planner separated, the learning part of the method does not directly influence the control value. This also enables the transfer of the method to different robotic systems without retraining, therefore being robot agnostic. We evaluate our method on different visual servoing tasks with and without clutter on two different robotic systems. Our method achieved mean absolute position errors of <0.5 mm and orientation errors of <1{deg}. Additionally, we transferred the method to a new system which differs in robot and camera, emphasizing robot agnostic capability of our method.
Read more5/14/2024
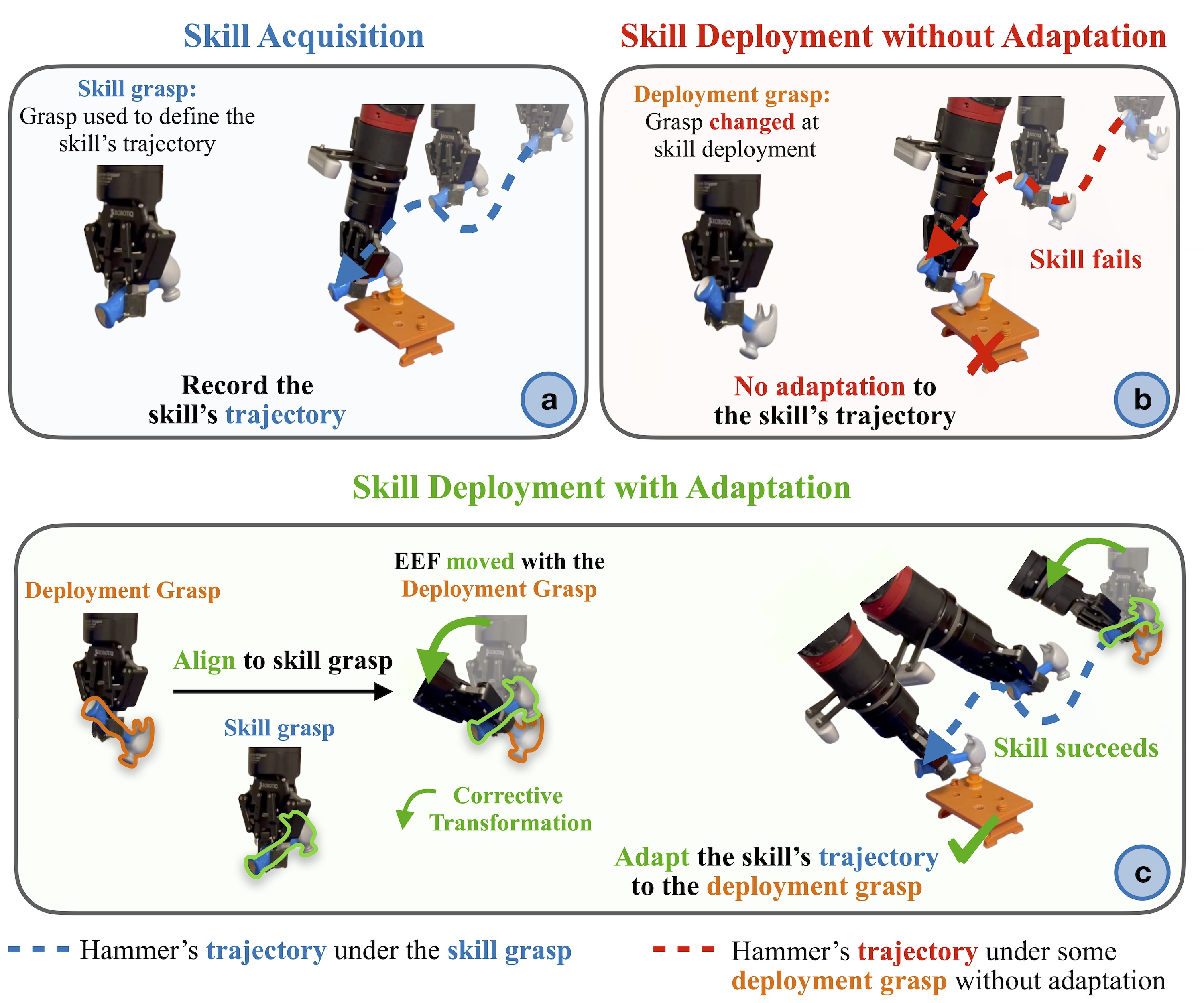
0
Adapting Skills to Novel Grasps: A Self-Supervised Approach
Georgios Papagiannis, Kamil Dreczkowski, Vitalis Vosylius, Edward Johns
In this paper, we study the problem of adapting manipulation trajectories involving grasped objects (e.g. tools) defined for a single grasp pose to novel grasp poses. A common approach to address this is to define a new trajectory for each possible grasp explicitly, but this is highly inefficient. Instead, we propose a method to adapt such trajectories directly while only requiring a period of self-supervised data collection, during which a camera observes the robot's end-effector moving with the object rigidly grasped. Importantly, our method requires no prior knowledge of the grasped object (such as a 3D CAD model), it can work with RGB images, depth images, or both, and it requires no camera calibration. Through a series of real-world experiments involving 1360 evaluations, we find that self-supervised RGB data consistently outperforms alternatives that rely on depth images including several state-of-the-art pose estimation methods. Compared to the best-performing baseline, our method results in an average of 28.5% higher success rate when adapting manipulation trajectories to novel grasps on several everyday tasks. Videos of the experiments are available on our webpage at https://www.robot-learning.uk/adapting-skills
Read more8/2/2024