Self-Supervised Skeleton Action Representation Learning: A Benchmark and Beyond

0

Sign in to get full access
Overview
- This paper introduces a self-supervised learning approach for skeleton-based action representation learning.
- The authors propose several self-supervised pretext tasks, including contrastive learning and masked skeleton modeling, to learn robust and generalizable skeletal representations.
- The paper also establishes a new benchmark dataset and evaluation protocol for this task, providing a comprehensive assessment of the proposed methods.
Plain English Explanation
The researchers in this paper have developed a new way to train artificial intelligence (AI) systems to understand human actions and movements. Traditional approaches often require a lot of labeled data, which can be time-consuming and expensive to collect. Instead, the researchers used a technique called "self-supervised learning," where the AI system learns to extract useful information from the data itself, without needing explicit labels.
Specifically, the researchers focused on using skeletal data - the positions of the major joints in the body - to understand human actions. They proposed several self-supervised "pretext tasks" that the AI system can learn to solve, such as predicting missing joint positions or distinguishing between similar actions. By learning to excel at these pretext tasks, the AI system can develop a robust and generalizable understanding of human movements, which can then be applied to more practical tasks like action recognition or human-computer interaction.
To test their approach, the researchers also created a new benchmark dataset and evaluation protocol. This provides a standardized way to compare different self-supervised learning methods for skeleton-based action understanding, helping to advance the field as a whole.
Technical Explanation
The paper proposes a self-supervised learning framework for skeleton-based action representation learning. The core idea is to define a set of pretext tasks that can be solved without any labeled data, but which nonetheless require the model to learn meaningful representations of the underlying skeletal dynamics.
Two key pretext tasks are explored:
-
Contrastive learning: The model is trained to distinguish between pairs of skeleton sequences that correspond to the same action (positive pairs) versus different actions (negative pairs). This encourages the model to learn representations that capture the distinctive features of each action.
-
Masked skeleton modeling: The model is trained to predict the missing joint positions in a partially occluded skeleton sequence. This requires the model to learn a deep understanding of the underlying skeletal dynamics and how the different joints relate to one another.
The paper also introduces a new benchmark dataset and evaluation protocol for this task, comprising a large-scale collection of 3D skeleton sequences from various action recognition datasets. This provides a standardized way to assess the performance of different self-supervised learning approaches.
Experimental results demonstrate that the proposed self-supervised pretext tasks lead to significantly improved performance on downstream action recognition tasks, compared to both supervised and other self-supervised baselines. The learned representations also exhibit strong generalization capabilities, transferring effectively to new datasets and tasks.
Critical Analysis
The paper makes a strong contribution to the field of self-supervised learning for skeleton-based action understanding. The proposed pretext tasks are well-designed and build on established techniques like contrastive learning and masked modeling, which have been successful in other domains.
However, the paper does not address some potential limitations and areas for further research. For example, it is unclear how the self-supervised representations would perform in a true zero-shot or low-data setting, where the target task is completely different from the pretext tasks. The paper also does not explore the probabilistic foundations of self-supervised learning, which could provide deeper insights into the learning process.
Additionally, the paper focuses solely on skeletal data and does not consider multimodal approaches that could integrate visual, auditory, or other contextual information to further improve action understanding. A more comprehensive survey of the state-of-the-art in self-supervised learning for action recognition could also help situate this work within the broader field.
Conclusion
This paper presents a novel self-supervised learning framework for skeleton-based action representation learning. By introducing effective pretext tasks like contrastive learning and masked skeleton modeling, the researchers have demonstrated how to train AI systems to understand human movements and actions without the need for large amounts of labeled data.
The new benchmark dataset and evaluation protocol established in this work provide a valuable resource for the research community, helping to advance the field of self-supervised learning for action understanding. While the paper has some limitations, it represents an important step forward in developing more efficient and generalizable approaches for this crucial task, with potential applications in areas like human-computer interaction, robotics, and healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Self-Supervised Skeleton Action Representation Learning: A Benchmark and Beyond
Jiahang Zhang, Lilang Lin, Shuai Yang, Jiaying Liu
Self-supervised learning (SSL), which aims to learn meaningful prior representations from unlabeled data, has been proven effective for skeleton-based action understanding. Different from the image domain, skeleton data possesses sparser spatial structures and diverse representation forms, with the absence of background clues and the additional temporal dimension, presenting new challenges for spatial-temporal motion pretext task design. Recently, many endeavors have been made for skeleton-based SSL, achieving remarkable progress. However, a systematic and thorough review is still lacking. In this paper, we conduct, for the first time, a comprehensive survey on self-supervised skeleton-based action representation learning. Following the taxonomy of context-based, generative learning, and contrastive learning approaches, we make a thorough review and benchmark of existing works and shed light on the future possible directions. Remarkably, our investigation demonstrates that most SSL works rely on the single paradigm, learning representations of a single level, and are evaluated on the action recognition task solely, which leaves the generalization power of skeleton SSL models under-explored. To this end, a novel and effective SSL method for skeleton is further proposed, which integrates versatile representation learning objectives of different granularity, substantially boosting the generalization capacity for multiple skeleton downstream tasks. Extensive experiments under three large-scale datasets demonstrate our method achieves superior generalization performance on various downstream tasks, including recognition, retrieval, detection, and few-shot learning.
Read more8/27/2024
0
A Closer Look at Benchmarking Self-Supervised Pre-training with Image Classification
Markus Marks, Manuel Knott, Neehar Kondapaneni, Elijah Cole, Thijs Defraeye, Fernando Perez-Cruz, Pietro Perona
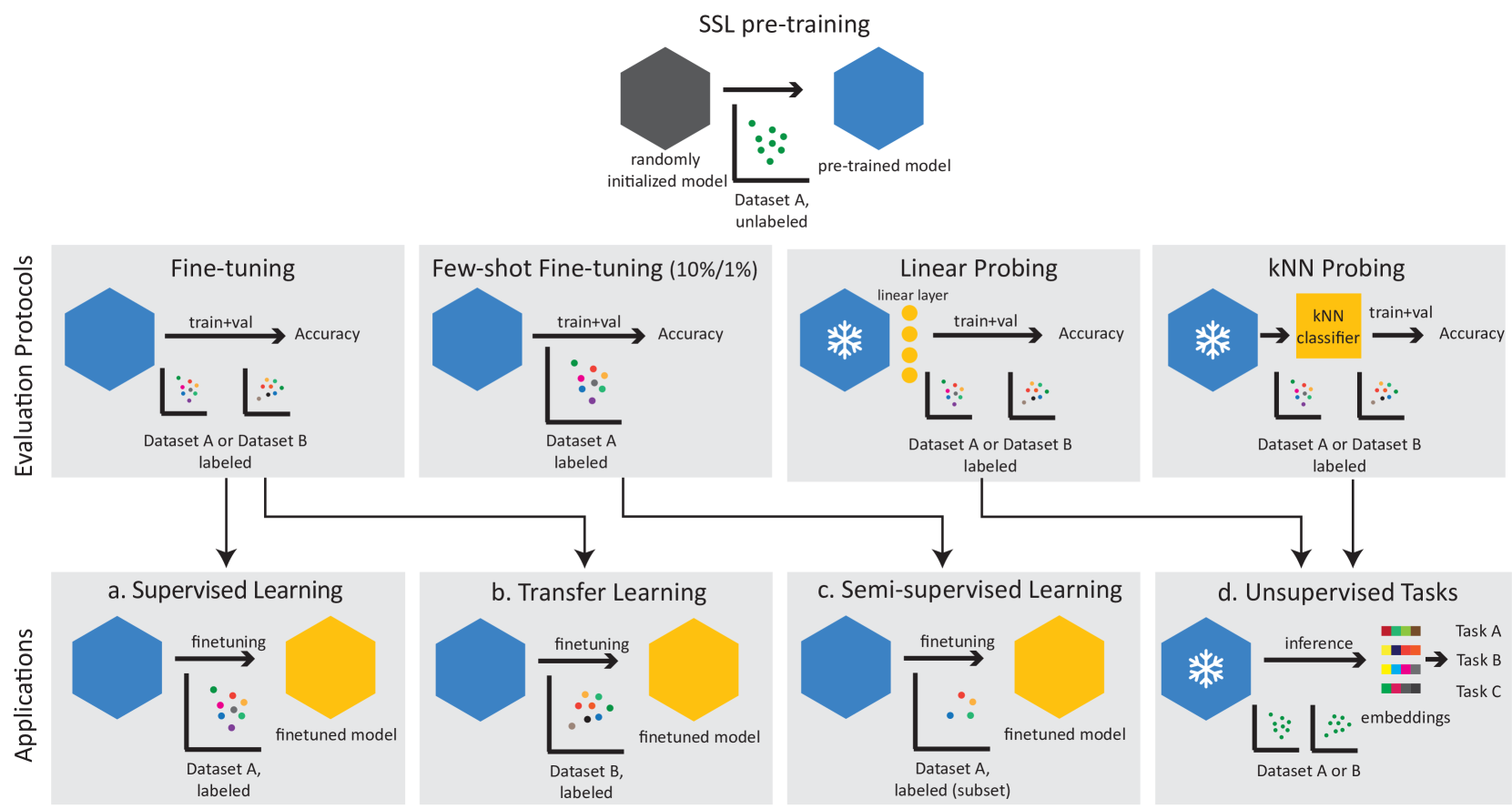
Self-supervised learning (SSL) is a machine learning approach where the data itself provides supervision, eliminating the need for external labels. The model is forced to learn about the data structure or context by solving a pretext task. With SSL, models can learn from abundant and cheap unlabeled data, significantly reducing the cost of training models where labels are expensive or inaccessible. In Computer Vision, SSL is widely used as pre-training followed by a downstream task, such as supervised transfer, few-shot learning on smaller labeled data sets, and/or unsupervised clustering. Unfortunately, it is infeasible to evaluate SSL methods on all possible downstream tasks and objectively measure the quality of the learned representation. Instead, SSL methods are evaluated using in-domain evaluation protocols, such as fine-tuning, linear probing, and k-nearest neighbors (kNN). However, it is not well understood how well these evaluation protocols estimate the representation quality of a pre-trained model for different downstream tasks under different conditions, such as dataset, metric, and model architecture. We study how classification-based evaluation protocols for SSL correlate and how well they predict downstream performance on different dataset types. Our study includes eleven common image datasets and 26 models that were pre-trained with different SSL methods or have different model backbones. We find that in-domain linear/kNN probing protocols are, on average, the best general predictors for out-of-domain performance. We further investigate the importance of batch normalization and evaluate how robust correlations are for different kinds of dataset domain shifts. We challenge assumptions about the relationship between discriminative and generative self-supervised methods, finding that most of their performance differences can be explained by changes to model backbones.
Read more7/19/2024

0
Self-supervised visual learning in the low-data regime: a comparative evaluation
Sotirios Konstantakos, Despina Ioanna Chalkiadaki, Ioannis Mademlis, Yuki M. Asano, Efstratios Gavves, Georgios Th. Papadopoulos
Self-Supervised Learning (SSL) is a valuable and robust training methodology for contemporary Deep Neural Networks (DNNs), enabling unsupervised pretraining on a `pretext task' that does not require ground-truth labels/annotation. This allows efficient representation learning from massive amounts of unlabeled training data, which in turn leads to increased accuracy in a `downstream task' by exploiting supervised transfer learning. Despite the relatively straightforward conceptualization and applicability of SSL, it is not always feasible to collect and/or to utilize very large pretraining datasets, especially when it comes to real-world application settings. In particular, in cases of specialized and domain-specific application scenarios, it may not be achievable or practical to assemble a relevant image pretraining dataset in the order of millions of instances or it could be computationally infeasible to pretrain at this scale. This motivates an investigation on the effectiveness of common SSL pretext tasks, when the pretraining dataset is of relatively limited/constrained size. In this context, this work introduces a taxonomy of modern visual SSL methods, accompanied by detailed explanations and insights regarding the main categories of approaches, and, subsequently, conducts a thorough comparative experimental evaluation in the low-data regime, targeting to identify: a) what is learnt via low-data SSL pretraining, and b) how do different SSL categories behave in such training scenarios. Interestingly, for domain-specific downstream tasks, in-domain low-data SSL pretraining outperforms the common approach of large-scale pretraining on general datasets. Grounded on the obtained results, valuable insights are highlighted regarding the performance of each category of SSL methods, which in turn suggest straightforward future research directions in the field.
Read more4/29/2024

0
Vision-Language Meets the Skeleton: Progressively Distillation with Cross-Modal Knowledge for 3D Action Representation Learning
Yang Chen, Tian He, Junfeng Fu, Ling Wang, Jingcai Guo, Ting Hu, Hong Cheng
Skeleton-based action representation learning aims to interpret and understand human behaviors by encoding the skeleton sequences, which can be categorized into two primary training paradigms: supervised learning and self-supervised learning. However, the former one-hot classification requires labor-intensive predefined action categories annotations, while the latter involves skeleton transformations (e.g., cropping) in the pretext tasks that may impair the skeleton structure. To address these challenges, we introduce a novel skeleton-based training framework (C$^2$VL) based on Cross-modal Contrastive learning that uses the progressive distillation to learn task-agnostic human skeleton action representation from the Vision-Language knowledge prompts. Specifically, we establish the vision-language action concept space through vision-language knowledge prompts generated by pre-trained large multimodal models (LMMs), which enrich the fine-grained details that the skeleton action space lacks. Moreover, we propose the intra-modal self-similarity and inter-modal cross-consistency softened targets in the cross-modal representation learning process to progressively control and guide the degree of pulling vision-language knowledge prompts and corresponding skeletons closer. These soft instance discrimination and self-knowledge distillation strategies contribute to the learning of better skeleton-based action representations from the noisy skeleton-vision-language pairs. During the inference phase, our method requires only the skeleton data as the input for action recognition and no longer for vision-language prompts. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets demonstrate that our method outperforms the previous methods and achieves state-of-the-art results. Code is available at: https://github.com/cseeyangchen/C2VL.
Read more9/17/2024