Semantic Skill Grounding for Embodied Instruction-Following in Cross-Domain Environments

0
Sign in to get full access
Overview
- The paper presents a semantic skill grounding approach for embodied instruction-following in cross-domain environments.
- It focuses on enabling robots to follow natural language instructions in unfamiliar environments by grounding the instructions to semantic skills.
- The approach aims to improve upon previous methods by allowing for more flexible and generalizable instruction-following.
Plain English Explanation
The paper describes a new way for robots to follow spoken or written instructions, even when they are in unfamiliar environments. Traditionally, robots have struggled to follow complex instructions in new situations, because they could only perform very specific pre-programmed actions.
The key innovation in this paper is semantic skill grounding. Instead of just trying to match instructions to predefined actions, the robot first tries to understand the underlying meaning or "semantics" of the instruction. It then figures out how to perform the appropriate high-level skills, like "open the door" or "put the object in the box", and then figures out the specific low-level movements needed to carry out those skills in the current environment.
This approach allows the robot to be more flexible and adaptable, since it can apply the same high-level skills in different settings, rather than being limited to a fixed set of pre-programmed responses. The robot can also ask clarifying questions or request additional information when needed, to ensure it properly understands the instruction.
Technical Explanation
The paper introduces a semantic skill grounding approach for embodied instruction-following. The key components are:
-
Skill Representation: The robot's skills are represented using a semantic hierarchy, with high-level skills (e.g. "open the door") linked to lower-level primitive actions (e.g. "grasp the doorknob", "pull the door").
-
Skill Recognition: When given a natural language instruction, the robot uses language understanding to map the instruction to the relevant high-level skills. It then reasons about how to decompose those skills into the necessary sequence of lower-level actions.
-
Skill Execution: The robot executes the plan of primitive actions to carry out the high-level skill, while also monitoring the environment and adapting its behavior as needed.
The system is evaluated on a range of instruction-following tasks across different environments, showing improved performance over prior methods that lacked the semantic grounding.
Critical Analysis
The paper presents a novel and promising approach to embodied instruction-following. Key strengths include:
- The semantic skill grounding allows for more flexible and generalizable instruction-following, compared to rigid, pre-programmed responses.
- The ability to reason about high-level skills and decompose them into lower-level actions is an important step towards more natural language interaction.
- The evaluation across diverse environments demonstrates the broad applicability of the approach.
However, some potential limitations and areas for further research include:
- The paper does not address how the robot's skill representations are acquired or learned, which is an important practical consideration.
- The experiments are still relatively constrained, and it's unclear how the system would scale to more complex, open-ended instructions or environments.
- There could be challenges in maintaining consistent semantic understanding across different contexts and modalities.
Overall, the semantic skill grounding approach represents an important step forward in embodied language understanding, but there is still significant room for further advancements in this area.
Conclusion
This paper presents a novel semantic skill grounding approach for improving the flexibility and generalization of embodied instruction-following. By reasoning about high-level skills and how to decompose them into low-level actions, the robot can better adapt to new environments and instructions.
While the current system shows promising results, there are still opportunities to further develop the underlying skill representations, learning mechanisms, and cross-modal reasoning capabilities. Continued progress in this area could lead to more natural and effective human-robot interaction in a wide range of real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Semantic Skill Grounding for Embodied Instruction-Following in Cross-Domain Environments
Sangwoo Shin, Seunghyun Kim, Youngsoo Jang, Moontae Lee, Honguk Woo
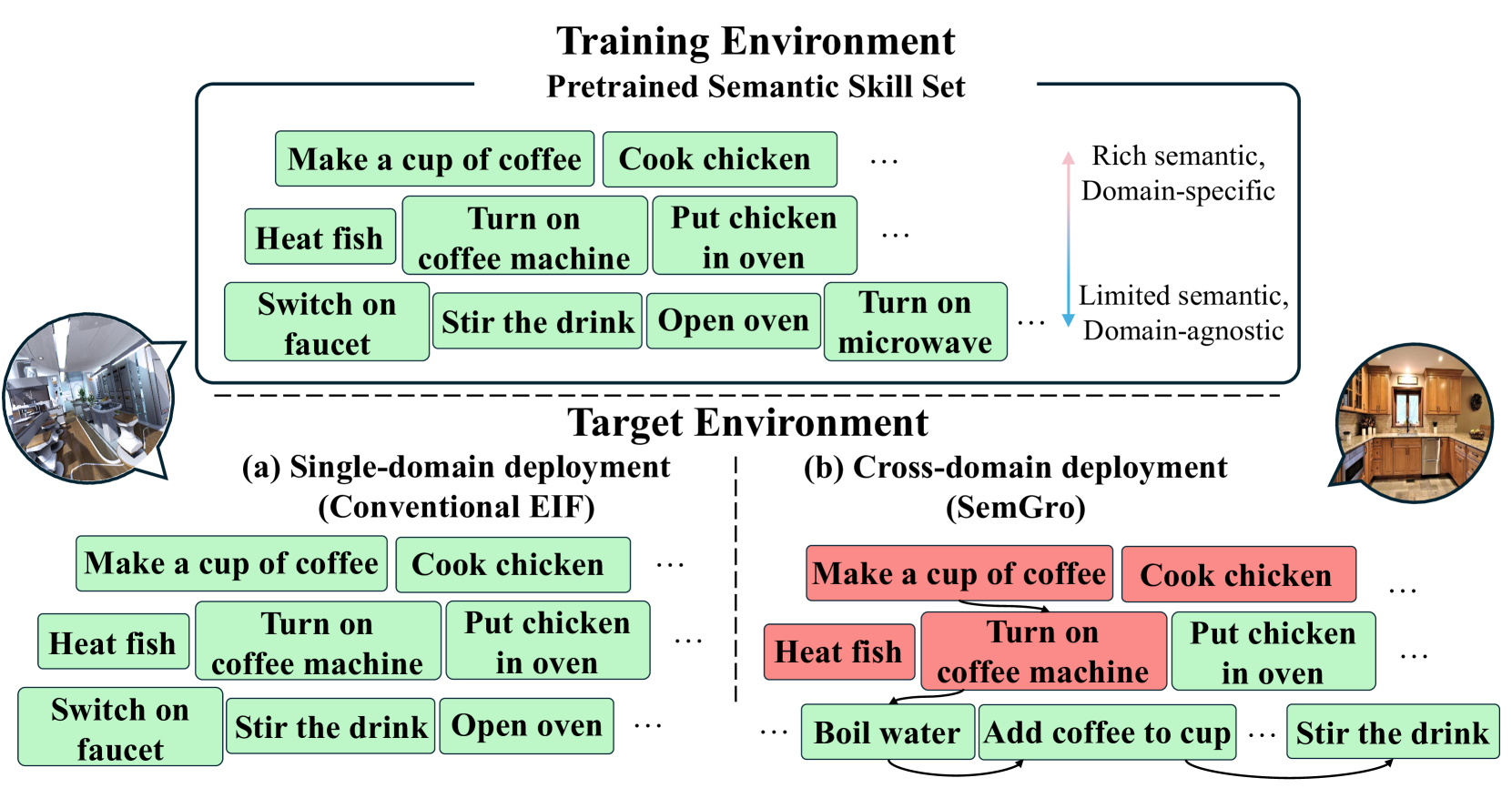
In embodied instruction-following (EIF), the integration of pretrained language models (LMs) as task planners emerges as a significant branch, where tasks are planned at the skill level by prompting LMs with pretrained skills and user instructions. However, grounding these pretrained skills in different domains remains challenging due to their intricate entanglement with the domain-specific knowledge. To address this challenge, we present a semantic skill grounding (SemGro) framework that leverages the hierarchical nature of semantic skills. SemGro recognizes the broad spectrum of these skills, ranging from short-horizon low-semantic skills that are universally applicable across domains to long-horizon rich-semantic skills that are highly specialized and tailored for particular domains. The framework employs an iterative skill decomposition approach, starting from the higher levels of semantic skill hierarchy and then moving downwards, so as to ground each planned skill to an executable level within the target domain. To do so, we use the reasoning capabilities of LMs for composing and decomposing semantic skills, as well as their multi-modal extension for assessing the skill feasibility in the target domain. Our experiments in the VirtualHome benchmark show the efficacy of SemGro in 300 cross-domain EIF scenarios.
Read more8/22/2024

0
Embodied Instruction Following in Unknown Environments
Zhenyu Wu, Ziwei Wang, Xiuwei Xu, Jiwen Lu, Haibin Yan
Enabling embodied agents to complete complex human instructions from natural language is crucial to autonomous systems in household services. Conventional methods can only accomplish human instructions in the known environment where all interactive objects are provided to the embodied agent, and directly deploying the existing approaches for the unknown environment usually generates infeasible plans that manipulate non-existing objects. On the contrary, we propose an embodied instruction following (EIF) method for complex tasks in the unknown environment, where the agent efficiently explores the unknown environment to generate feasible plans with existing objects to accomplish abstract instructions. Specifically, we build a hierarchical embodied instruction following framework including the high-level task planner and the low-level exploration controller with multimodal large language models. We then construct a semantic representation map of the scene with dynamic region attention to demonstrate the known visual clues, where the goal of task planning and scene exploration is aligned for human instruction. For the task planner, we generate the feasible step-by-step plans for human goal accomplishment according to the task completion process and the known visual clues. For the exploration controller, the optimal navigation or object interaction policy is predicted based on the generated step-wise plans and the known visual clues. The experimental results demonstrate that our method can achieve 45.09% success rate in 204 complex human instructions such as making breakfast and tidying rooms in large house-level scenes.
Read more6/18/2024
0
Language Guided Skill Discovery
Seungeun Rho, Laura Smith, Tianyu Li, Sergey Levine, Xue Bin Peng, Sehoon Ha
Skill discovery methods enable agents to learn diverse emergent behaviors without explicit rewards. To make learned skills useful for unknown downstream tasks, obtaining a semantically diverse repertoire of skills is essential. While some approaches introduce a discriminator to distinguish skills and others aim to increase state coverage, no existing work directly addresses the semantic diversity of skills. We hypothesize that leveraging the semantic knowledge of large language models (LLMs) can lead us to improve semantic diversity of resulting behaviors. In this sense, we introduce Language Guided Skill Discovery (LGSD), a skill discovery framework that aims to directly maximize the semantic diversity between skills. LGSD takes user prompts as input and outputs a set of semantically distinctive skills. The prompts serve as a means to constrain the search space into a semantically desired subspace, and the generated LLM outputs guide the agent to visit semantically diverse states within the subspace. We demonstrate that LGSD enables legged robots to visit different user-intended areas on a plane by simply changing the prompt. Furthermore, we show that language guidance aids in discovering more diverse skills compared to five existing skill discovery methods in robot-arm manipulation environments. Lastly, LGSD provides a simple way of utilizing learned skills via natural language.
Read more6/12/2024
👨🏫
0
Socratic Planner: Inquiry-Based Zero-Shot Planning for Embodied Instruction Following
Suyeon Shin, Sujin jeon, Junghyun Kim, Gi-Cheon Kang, Byoung-Tak Zhang
Embodied Instruction Following (EIF) is the task of executing natural language instructions by navigating and interacting with objects in 3D environments. One of the primary challenges in EIF is compositional task planning, which is often addressed with supervised or in-context learning with labeled data. To this end, we introduce the Socratic Planner, the first zero-shot planning method that infers without the need for any training data. Socratic Planner first decomposes the instructions into substructural information of the task through self-questioning and answering, translating it into a high-level plan, i.e., a sequence of subgoals. Subgoals are executed sequentially, with our visually grounded re-planning mechanism adjusting plans dynamically through a dense visual feedback. We also introduce an evaluation metric of high-level plans, RelaxedHLP, for a more comprehensive evaluation. Experiments demonstrate the effectiveness of the Socratic Planner, achieving competitive performance on both zero-shot and few-shot task planning in the ALFRED benchmark, particularly excelling in tasks requiring higher-dimensional inference. Additionally, a precise adjustments in the plan were achieved by incorporating environmental visual information.
Read more4/24/2024