Semi-supervised Concept Bottleneck Models
2406.18992
0
0

Abstract
Concept Bottleneck Models (CBMs) have garnered increasing attention due to their ability to provide concept-based explanations for black-box deep learning models while achieving high final prediction accuracy using human-like concepts. However, the training of current CBMs heavily relies on the accuracy and richness of annotated concepts in the dataset. These concept labels are typically provided by experts, which can be costly and require significant resources and effort. Additionally, concept saliency maps frequently misalign with input saliency maps, causing concept predictions to correspond to irrelevant input features - an issue related to annotation alignment. To address these limitations, we propose a new framework called SSCBM (Semi-supervised Concept Bottleneck Model). Our SSCBM is suitable for practical situations where annotated data is scarce. By leveraging joint training on both labeled and unlabeled data and aligning the unlabeled data at the concept level, we effectively solve these issues. We proposed a strategy to generate pseudo labels and an alignment loss. Experiments demonstrate that our SSCBM is both effective and efficient. With only 20% labeled data, we achieved 93.19% (96.39% in a fully supervised setting) concept accuracy and 75.51% (79.82% in a fully supervised setting) prediction accuracy.
Create account to get full access
Overview
- This paper introduces Semi-supervised Concept Bottleneck Models (SCBMs), a novel approach to leveraging concept-level annotations to improve machine learning model performance in a semi-supervised setting.
- SCBMs build on the concept bottleneck model framework, which uses an intermediate concept representation to improve model interpretability and sample efficiency.
- The key innovation of SCBMs is their ability to effectively utilize both labeled and unlabeled data by incorporating semi-supervised learning techniques.
Plain English Explanation
Machine learning models are often trained on large datasets, but acquiring high-quality labeled data can be time-consuming and expensive. Semi-supervised Concept Bottleneck Models (SCBMs) provide a way to improve model performance by leveraging both labeled and unlabeled data.
The core idea behind SCBMs is to use an intermediate "concept" layer in the model architecture. This concept layer represents high-level attributes or features of the input data, which can be more easily annotated by humans than the final task labels. By incorporating these concept-level annotations, even for a small subset of the data, the model can learn more effective representations and generalize better to new examples.
The semi-supervised aspect of SCBMs means that the model can also utilize unlabeled data during training. This is accomplished by incorporating techniques like self-supervised learning and consistency regularization, which allow the model to learn from the unlabeled examples without relying on task-specific labels.
By combining the advantages of concept bottleneck models and semi-supervised learning, SCBMs can achieve improved performance on a wide range of tasks, especially when labeled data is scarce. This can be particularly useful in domains where obtaining high-quality labeled data is challenging, such as medical imaging or environmental monitoring.
Technical Explanation
The Semi-supervised Concept Bottleneck Model (SCBM) architecture consists of three main components:
- Encoder: A neural network that maps the input data (e.g., images, text) to a high-dimensional latent representation.
- Concept Prediction Head: A neural network that predicts the concept-level annotations from the latent representation.
- Task Prediction Head: A neural network that predicts the final task labels (e.g., classification, regression) from the latent representation.
During training, the model optimizes two objectives:
- Concept Prediction: The concept prediction head is trained to accurately predict the concept-level annotations for the labeled data.
- Task Prediction: The task prediction head is trained to accurately predict the task labels for the labeled data.
Additionally, the authors introduce several semi-supervised learning techniques to leverage the unlabeled data:
- Self-supervised Pretraining: The encoder is first pretrained on a self-supervised task, such as contrastive learning or masked image modeling, to learn useful representations from the unlabeled data.
- Consistency Regularization: The model is trained to make consistent predictions for the same input under different augmentations or perturbations, encouraging the latent representations to be robust to minor changes in the input.
- Concept Alignment: The model is trained to align the concept-level representations between labeled and unlabeled data, leveraging the concept-level annotations as a form of weak supervision.
The authors evaluate SCBMs on several benchmark datasets and demonstrate significant performance improvements over both fully-supervised and semi-supervised baselines, especially when labeled data is scarce.
Critical Analysis
The Semi-supervised Concept Bottleneck Model (SCBM) approach offers a promising way to leverage concept-level annotations and unlabeled data to improve model performance. The key strengths of this approach include:
- Improved Sample Efficiency: By incorporating concept-level annotations, SCBMs can learn more effective representations from fewer labeled examples, making them particularly useful in data-scarce scenarios.
- Enhanced Interpretability: The concept layer provides a more interpretable intermediate representation, which can help users understand the model's decision-making process.
- Robustness to Distribution Shift: The semi-supervised learning techniques, such as consistency regularization, can make the learned representations more robust to changes in the data distribution.
However, some potential limitations and areas for further research include:
- Annotation Burden: While concept-level annotations may be easier to obtain than task-level labels, the annotation process can still be time-consuming and requires domain expertise.
- Scalability to Complex Tasks: The performance of SCBMs may be limited when applied to highly complex tasks with many possible concepts or when the concept-task alignment is not straightforward.
- Sensitivity to Concept Quality: The effectiveness of SCBMs is dependent on the quality and relevance of the concept-level annotations. Poorly defined or irrelevant concepts could negatively impact model performance.
Future research could explore ways to further reduce the annotation burden, such as automated concept discovery or interactive concept editing. Additionally, investigating techniques to handle complex, high-dimensional concept spaces could expand the applicability of SCBMs to a wider range of tasks.
Conclusion
The Semi-supervised Concept Bottleneck Model (SCBM) is a novel and promising approach that combines the strengths of concept bottleneck models and semi-supervised learning. By leveraging both labeled and unlabeled data, as well as concept-level annotations, SCBMs can achieve improved performance on a variety of tasks, especially when labeled data is scarce.
The ability to learn more effective and interpretable representations while utilizing unlabeled data makes SCBMs a valuable tool for advancing machine learning in data-limited domains. As the research in this area continues to evolve, SCBMs could have far-reaching implications for improving the sample efficiency, interpretability, and robustness of AI systems across a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Stochastic Concept Bottleneck Models
Moritz Vandenhirtz, Sonia Laguna, Riv{c}ards Marcinkeviv{c}s, Julia E. Vogt
0
0
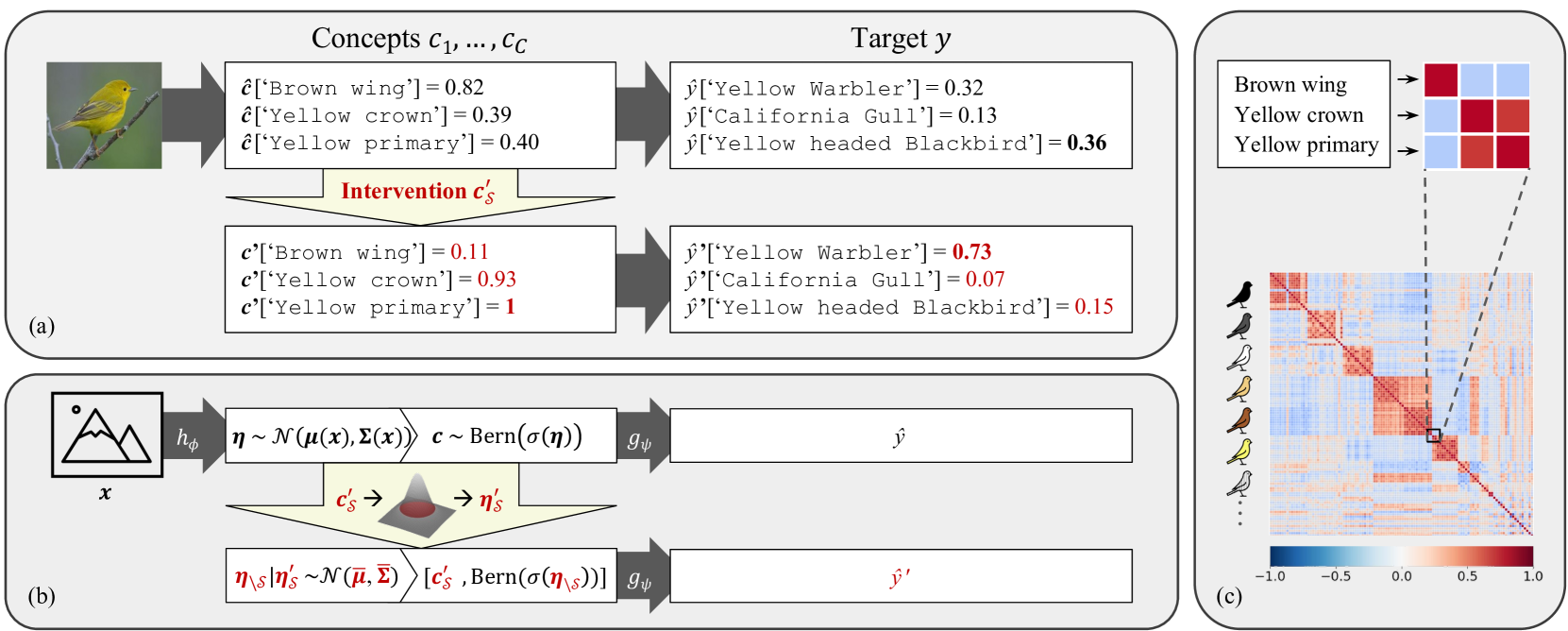
Concept Bottleneck Models (CBMs) have emerged as a promising interpretable method whose final prediction is based on intermediate, human-understandable concepts rather than the raw input. Through time-consuming manual interventions, a user can correct wrongly predicted concept values to enhance the model's downstream performance. We propose Stochastic Concept Bottleneck Models (SCBMs), a novel approach that models concept dependencies. In SCBMs, a single-concept intervention affects all correlated concepts, thereby improving intervention effectiveness. Unlike previous approaches that model the concept relations via an autoregressive structure, we introduce an explicit, distributional parameterization that allows SCBMs to retain the CBMs' efficient training and inference procedure. Additionally, we leverage the parameterization to derive an effective intervention strategy based on the confidence region. We show empirically on synthetic tabular and natural image datasets that our approach improves intervention effectiveness significantly. Notably, we showcase the versatility and usability of SCBMs by examining a setting with CLIP-inferred concepts, alleviating the need for manual concept annotations.
6/28/2024

Editable Concept Bottleneck Models
Lijie Hu, Chenyang Ren, Zhengyu Hu, Cheng-Long Wang, Di Wang
0
0
Concept Bottleneck Models (CBMs) have garnered much attention for their ability to elucidate the prediction process through a human-understandable concept layer. However, most previous studies focused on cases where the data, including concepts, are clean. In many scenarios, we always need to remove/insert some training data or new concepts from trained CBMs due to different reasons, such as privacy concerns, data mislabelling, spurious concepts, and concept annotation errors. Thus, the challenge of deriving efficient editable CBMs without retraining from scratch persists, particularly in large-scale applications. To address these challenges, we propose Editable Concept Bottleneck Models (ECBMs). Specifically, ECBMs support three different levels of data removal: concept-label-level, concept-level, and data-level. ECBMs enjoy mathematically rigorous closed-form approximations derived from influence functions that obviate the need for re-training. Experimental results demonstrate the efficiency and effectiveness of our ECBMs, affirming their adaptability within the realm of CBMs.
5/27/2024
Incremental Residual Concept Bottleneck Models
Chenming Shang, Shiji Zhou, Yujiu Yang, Hengyuan Zhang, Xinzhe Ni, Yuwang Wang
0
0
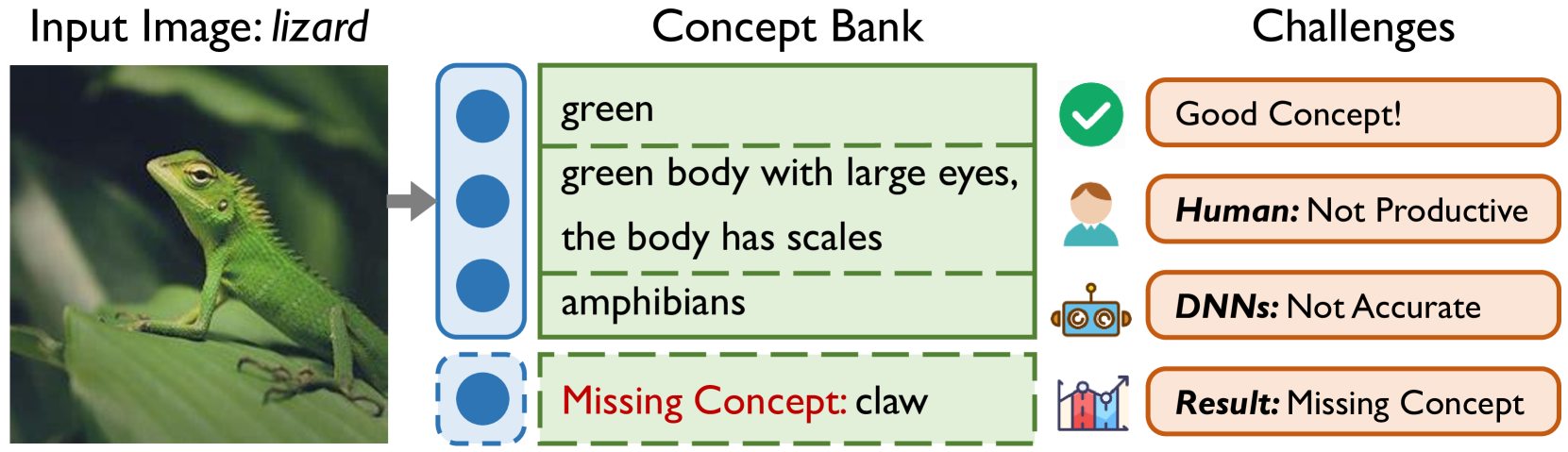
Concept Bottleneck Models (CBMs) map the black-box visual representations extracted by deep neural networks onto a set of interpretable concepts and use the concepts to make predictions, enhancing the transparency of the decision-making process. Multimodal pre-trained models can match visual representations with textual concept embeddings, allowing for obtaining the interpretable concept bottleneck without the expertise concept annotations. Recent research has focused on the concept bank establishment and the high-quality concept selection. However, it is challenging to construct a comprehensive concept bank through humans or large language models, which severely limits the performance of CBMs. In this work, we propose the Incremental Residual Concept Bottleneck Model (Res-CBM) to address the challenge of concept completeness. Specifically, the residual concept bottleneck model employs a set of optimizable vectors to complete missing concepts, then the incremental concept discovery module converts the complemented vectors with unclear meanings into potential concepts in the candidate concept bank. Our approach can be applied to any user-defined concept bank, as a post-hoc processing method to enhance the performance of any CBMs. Furthermore, to measure the descriptive efficiency of CBMs, the Concept Utilization Efficiency (CUE) metric is proposed. Experiments show that the Res-CBM outperforms the current state-of-the-art methods in terms of both accuracy and efficiency and achieves comparable performance to black-box models across multiple datasets.
4/16/2024
Improving Concept Alignment in Vision-Language Concept Bottleneck Models
Nithish Muthuchamy Selvaraj, Xiaobao Guo, Bingquan Shen, Adams Wai-Kin Kong, Alex Kot
0
0
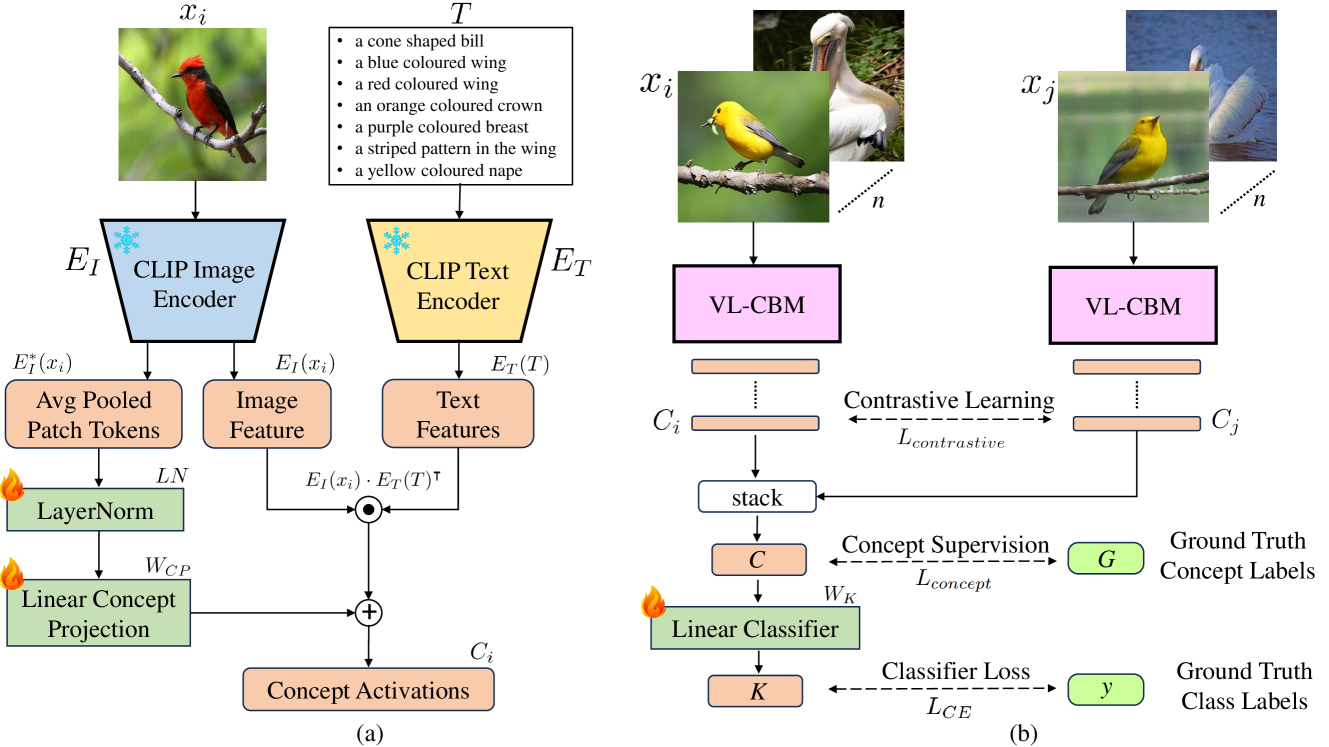
Concept Bottleneck Models (CBM) map the input image to a high-level human-understandable concept space and then make class predictions based on these concepts. Recent approaches automate the construction of CBM by prompting Large Language Models (LLM) to generate text concepts and then use Vision Language Models (VLM) to obtain concept scores to train a CBM. However, it is desired to build CBMs with concepts defined by human experts instead of LLM generated concepts to make them more trustworthy. In this work, we take a closer inspection on the faithfulness of VLM concept scores for such expert-defined concepts in domains like fine-grain bird species classification and animal classification. Our investigations reveal that frozen VLMs, like CLIP, struggle to correctly associate a concept to the corresponding visual input despite achieving a high classification performance. To address this, we propose a novel Contrastive Semi-Supervised (CSS) learning method which uses a few labeled concept examples to improve concept alignment (activate truthful visual concepts) in CLIP model. Extensive experiments on three benchmark datasets show that our approach substantially increases the concept accuracy and classification accuracy, yet requires only a fraction of the human-annotated concept labels. To further improve the classification performance, we also introduce a new class-level intervention procedure for fine-grain classification problems that identifies the confounding classes and intervenes their concept space to reduce errors.
5/6/2024