Sequence Length Scaling in Vision Transformers for Scientific Images on Frontier

0
👀
Sign in to get full access
Overview
- Vision Transformers (ViTs) are crucial for foundational models in scientific imagery, including Earth science applications, due to their ability to process long sequences.
- While transformers for text have inspired scaling sequence lengths in ViTs, adapting these techniques introduces unique challenges.
- The researchers developed distributed sequence parallelism for ViTs, enabling them to handle up to 1 million tokens.
- Their approach, leveraging DeepSpeed-Ulysses and Long-Sequence-Segmentation with model sharding, is the first to apply sequence parallelism in ViT training.
- This achieved a 94% batch scaling efficiency on 2,048 AMD-MI250X GPUs.
Plain English Explanation
Vision Transformers (ViTs) are a type of artificial intelligence model that are particularly useful for working with large scientific images, such as those used in Earth science applications. This is because ViTs can process very long sequences of information, which is important for understanding the complex patterns and details in these types of images.
While the success of transformers in processing long text sequences has inspired similar approaches for ViTs, adapting these techniques presents unique challenges. The researchers in this study developed a new way to distribute the processing of these long sequences across multiple computers, or GPUs, in a parallel fashion. This allows ViTs to handle up to 1 million individual pieces of information, or "tokens," which is a massive increase in their capacity.
The researchers' approach, which builds on existing techniques like DeepSpeed-Ulysses and Long-Sequence-Segmentation with model sharding, is the first to apply this type of parallel sequence processing to ViT training. By leveraging 2,048 high-performance AMD-MI250X GPUs, they were able to achieve a remarkable 94% efficiency in scaling the batch size, meaning they could train their models very quickly and effectively.
Technical Explanation
The researchers addressed the challenge of scaling Vision Transformers (ViTs) to handle long sequence lengths, which is crucial for scientific imagery applications like climate modeling. While transformer models have been successful in processing long text sequences, adapting these techniques to ViTs introduces unique challenges.
To overcome this, the researchers developed a distributed sequence parallelism approach for ViTs, enabling them to process up to 1 million tokens. Their method, which leverages DeepSpeed-Ulysses and Long-Sequence-Segmentation with model sharding, is the first to apply sequence parallelism in ViT training. This allowed them to achieve a remarkable 94% batch scaling efficiency on 2,048 AMD-MI250X GPUs.
Evaluating sequence parallelism in ViTs, particularly in models up to 10 billion parameters, revealed substantial bottlenecks. To address these, the researchers employed a combination of strategies, including hybrid sequence, pipeline, tensor parallelism, and flash attention techniques. This enabled them to scale their models beyond the memory limits of a single GPU.
The researchers' approach significantly enhanced climate modeling accuracy by 20% in temperature predictions, marking the first training of a transformer model on a full-attention matrix over a sequence length of 188,000.
Critical Analysis
The researchers' work on scaling Vision Transformers (ViTs) to handle long sequence lengths is a significant advancement in the field of scientific imagery and foundational models. By developing a distributed sequence parallelism approach, they have enabled ViTs to process up to 1 million tokens, a massive increase in their capacity.
However, the researchers acknowledge that evaluating sequence parallelism in ViTs, particularly in large models up to 10 billion parameters, revealed substantial bottlenecks. While they were able to address these challenges through a combination of strategies, including hybrid sequence, pipeline, tensor parallelism, and flash attention techniques, it is possible that there are additional limitations or areas for further optimization that were not explored in this study.
Additionally, the researchers' focus on climate modeling accuracy and the use of a full-attention matrix over a sequence length of 188,000 is a significant achievement, but it is unclear how their approach would scale to other types of scientific imagery or applications. Further research may be needed to assess the generalizability of their techniques.
Overall, the researchers' work represents an important step forward in scaling ViTs for scientific imagery applications, but there may be opportunities for further refinement and exploration of the limitations and potential trade-offs of their approach.
Conclusion
The researchers have developed a novel distributed sequence parallelism approach for Vision Transformers (ViTs), enabling them to process up to 1 million tokens. This is a significant advancement for the use of ViTs in scientific imagery applications, such as climate modeling, where the ability to handle long sequence lengths is crucial.
By leveraging techniques like DeepSpeed-Ulysses, Long-Sequence-Segmentation, and flash attention, the researchers were able to achieve a remarkable 94% batch scaling efficiency on a large-scale GPU setup. This marks an important milestone in the development of scalable ViT models, with the potential to significantly impact a wide range of scientific and industrial applications.
While the researchers encountered some bottlenecks in their evaluation of large ViT models, their innovative use of hybrid parallelism strategies demonstrates their commitment to addressing the challenges of scaling these powerful models. As the field of artificial intelligence continues to advance, the researchers' work on scaling vision transformers and processing long sequences will undoubtedly pave the way for even more groundbreaking developments in scientific imagery and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Sequence Length Scaling in Vision Transformers for Scientific Images on Frontier
Aristeidis Tsaris, Chengming Zhang, Xiao Wang, Junqi Yin, Siyan Liu, Moetasim Ashfaq, Ming Fan, Jong Youl Choi, Mohamed Wahib, Dan Lu, Prasanna Balaprakash, Feiyi Wang
Vision Transformers (ViTs) are pivotal for foundational models in scientific imagery, including Earth science applications, due to their capability to process large sequence lengths. While transformers for text has inspired scaling sequence lengths in ViTs, yet adapting these for ViTs introduces unique challenges. We develop distributed sequence parallelism for ViTs, enabling them to handle up to 1M tokens. Our approach, leveraging DeepSpeed-Ulysses and Long-Sequence-Segmentation with model sharding, is the first to apply sequence parallelism in ViT training, achieving a 94% batch scaling efficiency on 2,048 AMD-MI250X GPUs. Evaluating sequence parallelism in ViTs, particularly in models up to 10B parameters, highlighted substantial bottlenecks. We countered these with hybrid sequence, pipeline, tensor parallelism, and flash attention strategies, to scale beyond single GPU memory limits. Our method significantly enhances climate modeling accuracy by 20% in temperature predictions, marking the first training of a transformer model on a full-attention matrix over 188K sequence length.
Read more5/28/2024
🎲
0
Perceiving Longer Sequences With Bi-Directional Cross-Attention Transformers
Markus Hiller, Krista A. Ehinger, Tom Drummond
We present a novel bi-directional Transformer architecture (BiXT) which scales linearly with input size in terms of computational cost and memory consumption, but does not suffer the drop in performance or limitation to only one input modality seen with other efficient Transformer-based approaches. BiXT is inspired by the Perceiver architectures but replaces iterative attention with an efficient bi-directional cross-attention module in which input tokens and latent variables attend to each other simultaneously, leveraging a naturally emerging attention-symmetry between the two. This approach unlocks a key bottleneck experienced by Perceiver-like architectures and enables the processing and interpretation of both semantics ('what') and location ('where') to develop alongside each other over multiple layers -- allowing its direct application to dense and instance-based tasks alike. By combining efficiency with the generality and performance of a full Transformer architecture, BiXT can process longer sequences like point clouds, text or images at higher feature resolutions and achieves competitive performance across a range of tasks like point cloud part segmentation, semantic image segmentation, image classification, hierarchical sequence modeling and document retrieval. Our experiments demonstrate that BiXT models outperform larger competitors by leveraging longer sequences more efficiently on vision tasks like classification and segmentation, and perform on par with full Transformer variants on sequence modeling and document retrieval -- but require $28%$ fewer FLOPs and are up to $8.4times$ faster.
Read more5/28/2024
0
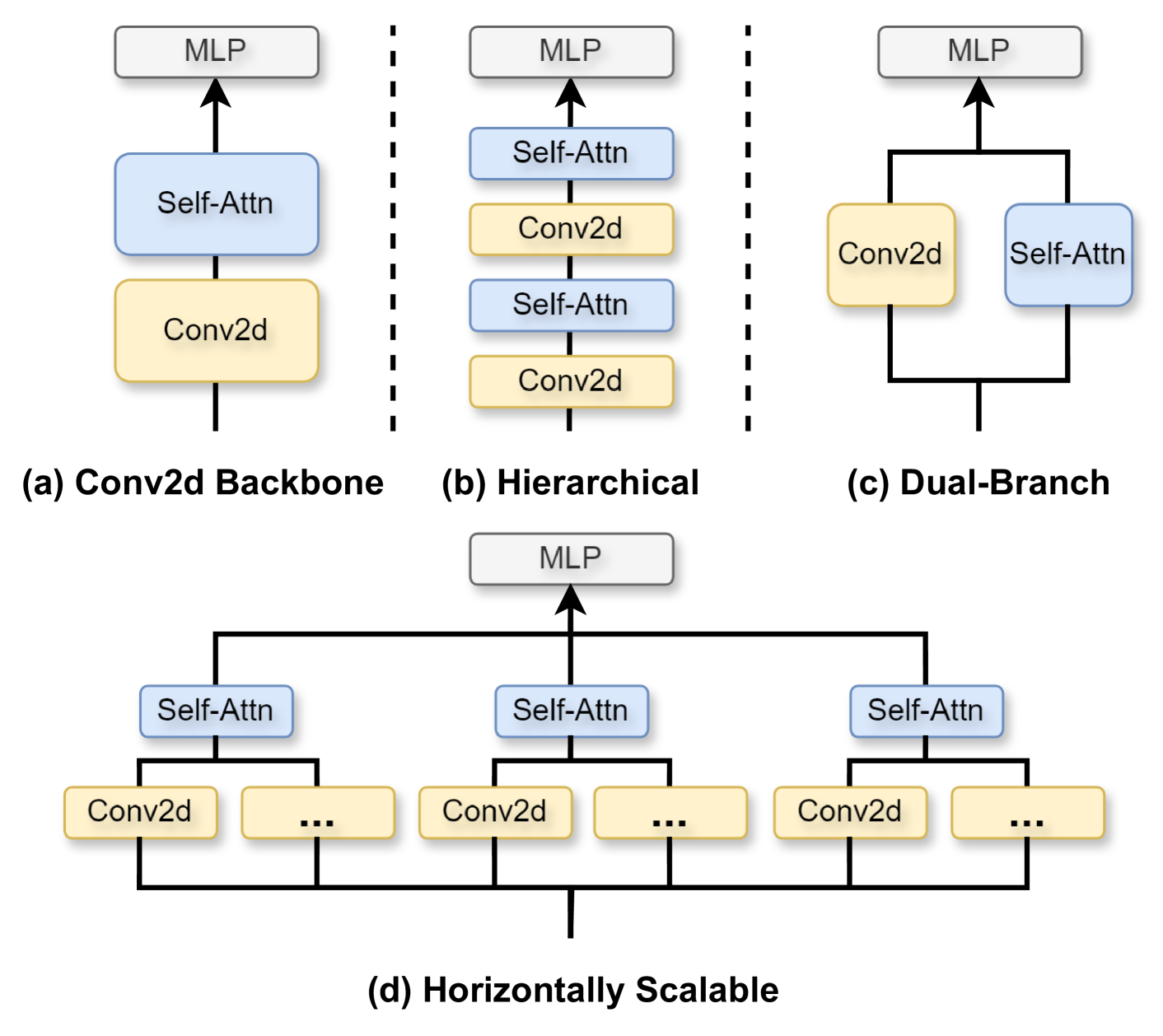
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
Due to its deficiency in prior knowledge (inductive bias), Vision Transformer (ViT) requires pre-training on large-scale datasets to perform well. Moreover, the growing layers and parameters in ViT models impede their applicability to devices with limited computing resources. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT) scheme. Specifically, a novel image-level feature embedding is introduced to ViT, where the preserved inductive bias allows the model to eliminate the need for pre-training while outperforming on small datasets. Besides, a novel horizontally scalable architecture is designed, facilitating collaborative model training and inference across multiple computing devices. The experimental results depict that, without pre-training, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes on small datasets, while providing existing CNN backbones up to 3.1% improvement in top-1 accuracy on ImageNet. The code is available at https://github.com/xuchenhao001/HSViT.
Read more7/17/2024
0
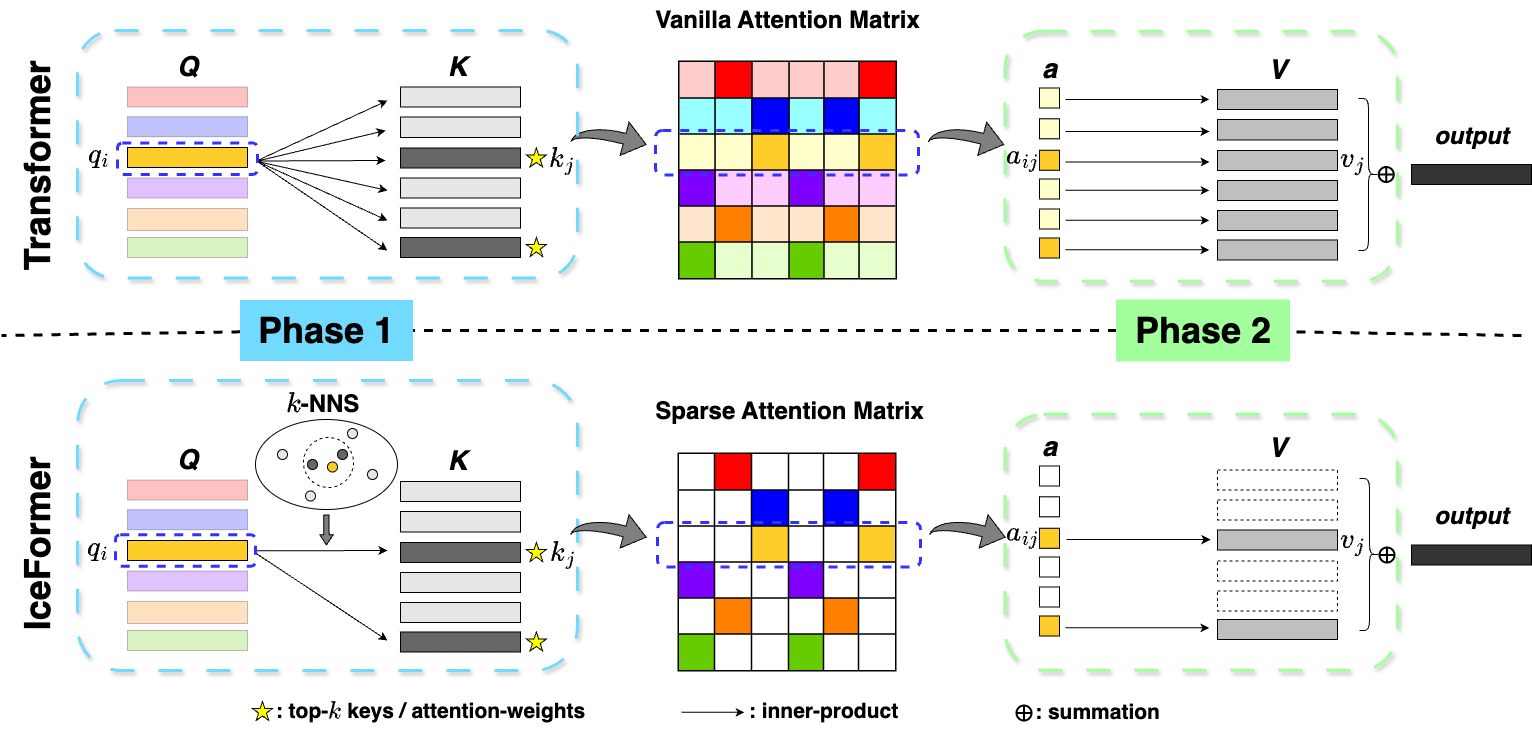
IceFormer: Accelerated Inference with Long-Sequence Transformers on CPUs
Yuzhen Mao, Martin Ester, Ke Li
One limitation of existing Transformer-based models is that they cannot handle very long sequences as input since their self-attention operations exhibit quadratic time and space complexity. This problem becomes especially acute when Transformers are deployed on hardware platforms equipped only with CPUs. To address this issue, we propose a novel method for accelerating self-attention at inference time that works with pretrained Transformer models out-of-the-box without requiring retraining. We experiment using our method to accelerate various long-sequence Transformers, including a leading LLaMA 2-based LLM, on various benchmarks and demonstrate a greater speedup of 2.73x - 7.63x while retaining 98.6% - 99.6% of the accuracy of the original pretrained models. The code is available on our project website at https://yuzhenmao.github.io/IceFormer/.
Read more5/7/2024