Sequential Contrastive Audio-Visual Learning

0

Sign in to get full access
Overview
- This paper explores a novel approach to audio-visual learning called Sequential Contrastive Audio-Visual Learning (SCAV).
- SCAV aims to learn joint audio-visual representations by leveraging the temporal structure of audio and video data.
- The key idea is to use contrastive learning to align audio and video features across time, capturing the dynamic relationship between the two modalities.
Plain English Explanation
SCAV is a technique for teaching machines to understand the connection between what they see and what they hear. When we watch a video, the sights and sounds are linked together in a specific way over time. SCAV tries to capture this temporal relationship by comparing the audio and visual features at different time points, rewarding the model when it correctly aligns them.
This is valuable because it allows the model to learn a deeper, more holistic understanding of the audio-visual world. Instead of just recognizing individual objects or sounds, the model can grasp how they fit together and evolve over time. This could enable more natural interactions between machines and the real world, improving applications like video understanding, audio-visual speech recognition, and even robotics.
Technical Explanation
The core idea of SCAV is to train a model to embed audio and visual features in a shared latent space, where temporally aligned features are pulled together while non-aligned features are pushed apart. This is achieved through a contrastive learning objective that compares audio-visual pairs at different time steps.
Specifically, the model takes in a video clip and the corresponding audio track. It extracts visual and audio features at each time step using separate encoder networks. Then, it computes the cosine similarity between the audio and visual features at the same time step (the "positive" pair) and compares this to the similarity between the audio features and visual features at different time steps (the "negative" pairs). The model is trained to maximize the similarity of the positive pairs while minimizing the similarity of the negative pairs.
Through this sequential contrastive learning, the model learns to align the audio and visual representations in a way that captures the temporal dynamics of the input. The authors demonstrate the effectiveness of this approach on several audio-visual tasks, including action recognition, audio-visual correspondence, and video classification.
Critical Analysis
The SCAV approach is a promising step towards more robust and generalizable audio-visual representation learning. By explicitly modeling the temporal relationships between the two modalities, the model can capture more nuanced and informative features that are difficult to learn from static or unaligned data.
However, the paper does not fully address the potential limitations of this approach. For example, the contrastive objective may be sensitive to the choice of negative samples, and the model's performance may degrade on data with complex or asynchronous audio-visual relationships. Additionally, the computational cost of the sequential contrastive learning process could be prohibitive for real-time applications.
Further research is needed to explore the scalability and robustness of SCAV, as well as its applicability to more diverse audio-visual domains beyond the specific tasks covered in this paper. Incorporating additional inductive biases or architectural choices, such as those explored in EquiAV and Contrastive Learning from Synthetic Audio Doppelgangers, could also help improve the model's performance and generalization capabilities.
Conclusion
The SCAV approach presented in this paper represents an exciting advancement in the field of audio-visual learning. By leveraging the temporal structure of audio and video data, the model can learn more meaningful and dynamic representations that capture the rich interplay between the two modalities.
This work has the potential to enable a wide range of applications, from enhanced video understanding to more natural audio-visual interactions in robotics and speech recognition. As the field of audio-visual learning continues to evolve, techniques like SCAV will likely play an increasingly important role in bridging the gap between machine perception and the rich, multisensory world we inhabit.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Sequential Contrastive Audio-Visual Learning
Ioannis Tsiamas, Santiago Pascual, Chunghsin Yeh, Joan Serr`a
Contrastive learning has emerged as a powerful technique in audio-visual representation learning, leveraging the natural co-occurrence of audio and visual modalities in extensive web-scale video datasets to achieve significant advancements. However, conventional contrastive audio-visual learning methodologies often rely on aggregated representations derived through temporal aggregation, which neglects the intrinsic sequential nature of the data. This oversight raises concerns regarding the ability of standard approaches to capture and utilize fine-grained information within sequences, information that is vital for distinguishing between semantically similar yet distinct examples. In response to this limitation, we propose sequential contrastive audio-visual learning (SCAV), which contrasts examples based on their non-aggregated representation space using sequential distances. Retrieval experiments with the VGGSound and Music datasets demonstrate the effectiveness of SCAV, showing 2-3x relative improvements against traditional aggregation-based contrastive learning and other methods from the literature. We also show that models trained with SCAV exhibit a high degree of flexibility regarding the metric employed for retrieval, allowing them to operate on a spectrum of efficiency-accuracy trade-offs, potentially making them applicable in multiple scenarios, from small- to large-scale retrieval.
Read more7/9/2024
🏅
0
Looking Similar, Sounding Different: Leveraging Counterfactual Cross-Modal Pairs for Audiovisual Representation Learning
Nikhil Singh, Chih-Wei Wu, Iroro Orife, Mahdi Kalayeh
Audiovisual representation learning typically relies on the correspondence between sight and sound. However, there are often multiple audio tracks that can correspond with a visual scene. Consider, for example, different conversations on the same crowded street. The effect of such counterfactual pairs on audiovisual representation learning has not been previously explored. To investigate this, we use dubbed versions of movies and television shows to augment cross-modal contrastive learning. Our approach learns to represent alternate audio tracks, differing only in speech, similarly to the same video. Our results, from a comprehensive set of experiments investigating different training strategies, show this general approach improves performance on a range of downstream auditory and audiovisual tasks, without majorly affecting linguistic task performance overall. These findings highlight the importance of considering speech variation when learning scene-level audiovisual correspondences and suggest that dubbed audio can be a useful augmentation technique for training audiovisual models toward more robust performance on diverse downstream tasks.
Read more6/11/2024
0
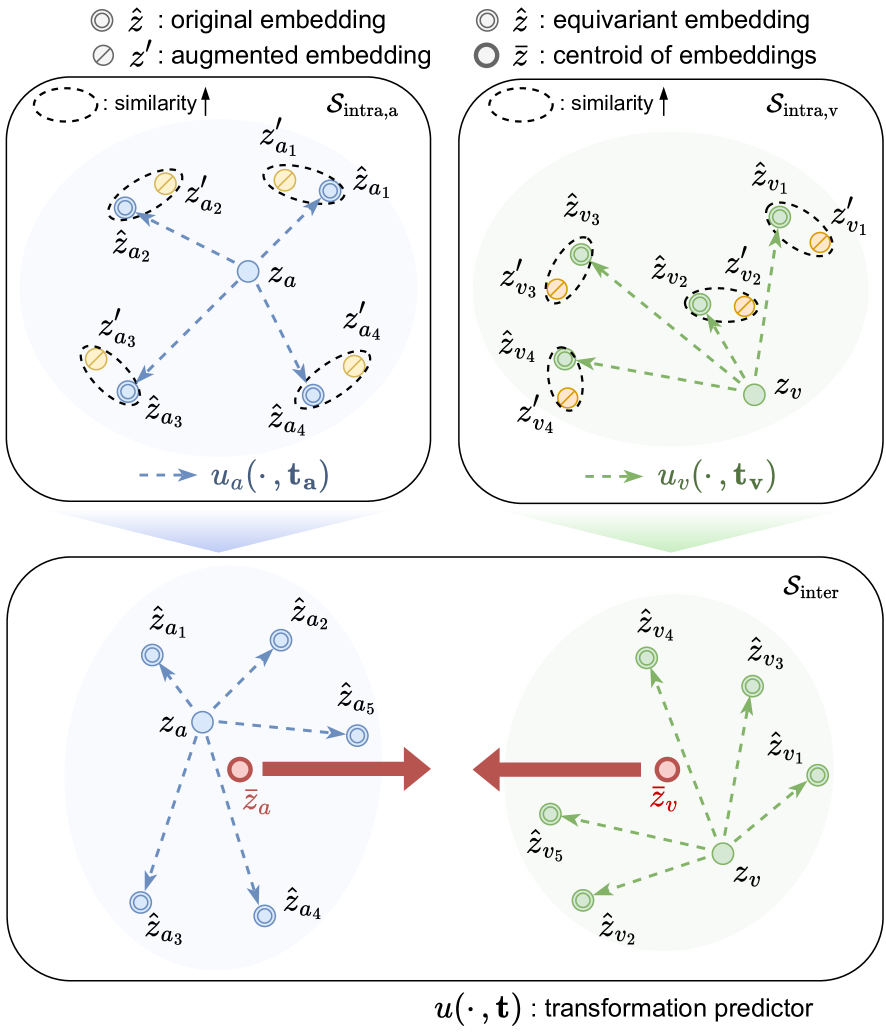
EquiAV: Leveraging Equivariance for Audio-Visual Contrastive Learning
Jongsuk Kim, Hyeongkeun Lee, Kyeongha Rho, Junmo Kim, Joon Son Chung
Recent advancements in self-supervised audio-visual representation learning have demonstrated its potential to capture rich and comprehensive representations. However, despite the advantages of data augmentation verified in many learning methods, audio-visual learning has struggled to fully harness these benefits, as augmentations can easily disrupt the correspondence between input pairs. To address this limitation, we introduce EquiAV, a novel framework that leverages equivariance for audio-visual contrastive learning. Our approach begins with extending equivariance to audio-visual learning, facilitated by a shared attention-based transformation predictor. It enables the aggregation of features from diverse augmentations into a representative embedding, providing robust supervision. Notably, this is achieved with minimal computational overhead. Extensive ablation studies and qualitative results verify the effectiveness of our method. EquiAV outperforms previous works across various audio-visual benchmarks. The code is available on https://github.com/JongSuk1/EquiAV.
Read more6/21/2024
0
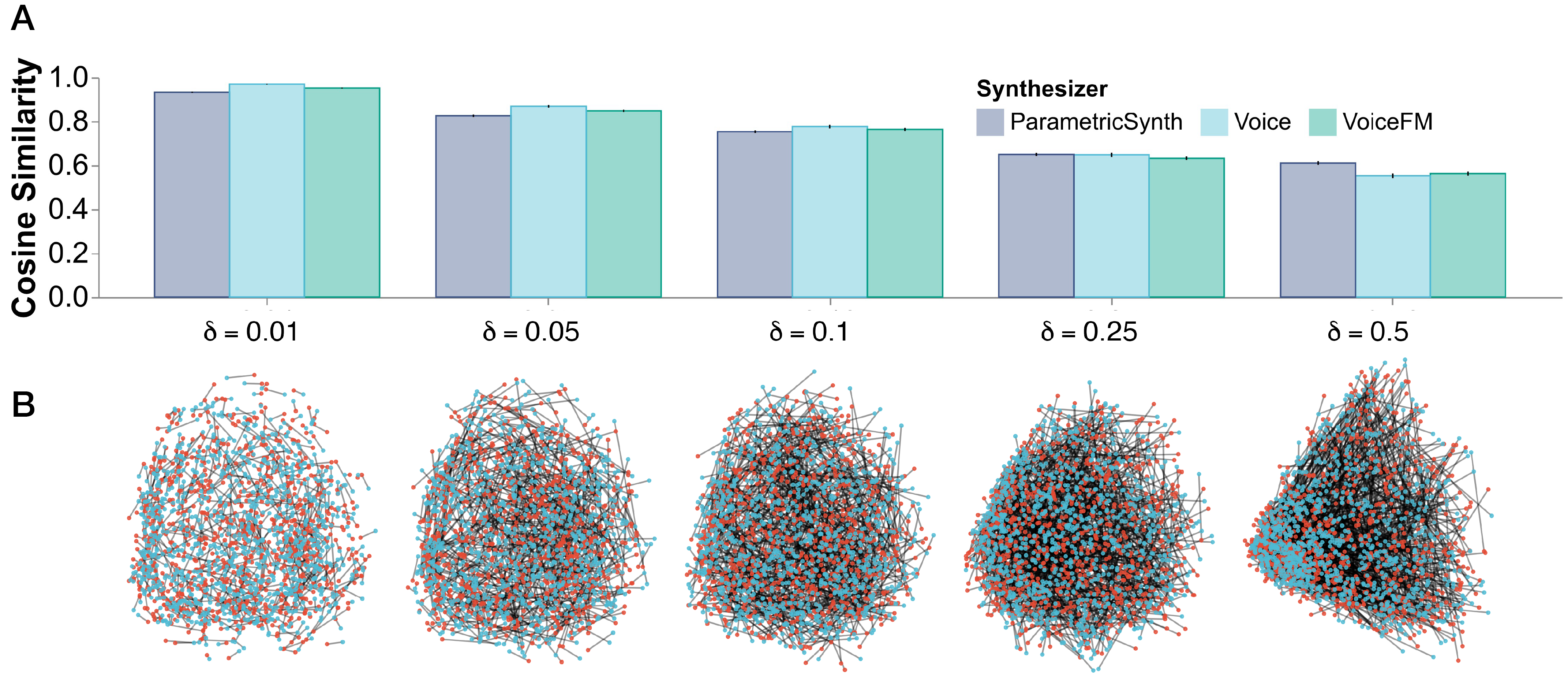
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
Read more6/11/2024