Sharing Matters: Analysing Neurons Across Languages and Tasks in LLMs
2406.09265
0
0
Abstract
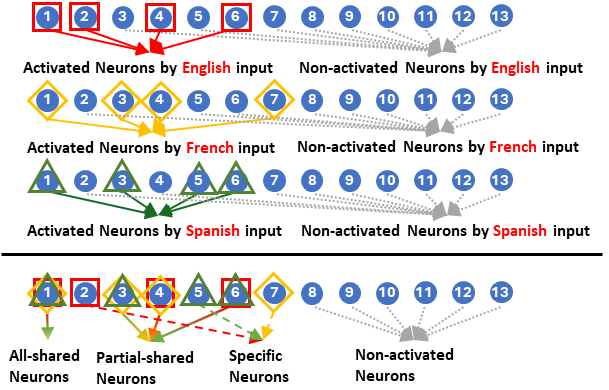
Multilingual large language models (LLMs) have greatly increased the ceiling of performance on non-English tasks. However the mechanisms behind multilingualism in these LLMs are poorly understood. Of particular interest is the degree to which internal representations are shared between languages. Recent work on neuron analysis of LLMs has focused on the monolingual case, and the limited work on the multilingual case has not considered the interaction between tasks and linguistic representations. In our work, we investigate how neuron activation is shared across languages by categorizing neurons into four distinct groups according to their responses across different languages for a particular input: all-shared, partial-shared, specific, and non-activated. This categorization is combined with a study of neuron attribution, i.e. the importance of a neuron w.r.t an output. Our analysis reveals the following insights: (i) the linguistic sharing patterns are strongly affected by the type of task, but neuron behaviour changes across different inputs even for the same task; (ii) all-shared neurons play a key role in generating correct responses; (iii) boosting multilingual alignment by increasing all-shared neurons can enhance accuracy on multilingual tasks. The code is available at https://github.com/weixuan-wang123/multilingual-neurons.
Create account to get full access
Overview
- This paper analyzes how neurons in large language models (LLMs) are shared across different languages and tasks.
- The researchers investigate the role of language-specific neurons in enabling multilingual capabilities in LLMs.
- They explore how vocabulary sharing facilitates multilingualism and how multimodal neurons can be identified and edited in pre-trained models.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have shown impressive multilingual abilities, allowing them to understand and generate text in multiple languages. But how do these models achieve this? The researchers in this paper dive into the inner workings of LLMs to understand the mechanisms behind their multilingual capabilities.
One key finding is the importance of "language-specific neurons." These are neurons in the model that specialize in processing information for a particular language. By analyzing the activations of these neurons, the researchers were able to understand how LLMs handle multilingualism.
The paper also explores how "vocabulary sharing" - the practice of using a shared vocabulary across languages - helps facilitate multilingual abilities in models like LLAMA. Additionally, the researchers discuss ways to identify and edit multimodal neurons in pre-trained models, which could be useful for fine-tuning these models for specific tasks.
Overall, this research provides valuable insights into the inner workings of multilingual LLMs, shedding light on how they are able to understand and generate text in multiple languages.
Technical Explanation
The researchers first investigate the role of "language-specific neurons" in enabling multilingual capabilities in LLMs. They analyze the neuron activations of several pre-trained models, including BERT and GPT-3, and find that certain neurons specialize in processing information for particular languages. By understanding the behavior of these language-specific neurons, the researchers are able to explain how LLMs handle multilingualism.
Next, the paper explores the role of "vocabulary sharing" in facilitating multilingual abilities. The researchers investigate models like LLAMA, which use a shared vocabulary across languages, and demonstrate how this approach can enhance a model's multilingual performance.
Finally, the researchers discuss methods for identifying and editing multimodal neurons in pre-trained models. This could be useful for fine-tuning LLMs for specific tasks or applications, as it allows for targeted modifications of the model's internal representations.
Critical Analysis
The paper provides valuable insights into the inner workings of multilingual LLMs, but it's important to note that the findings are based on a limited set of models and tasks. The researchers acknowledge that further research is needed to understand the generalizability of their results across a wider range of LLMs and language domains.
Additionally, while the methods for identifying and editing multimodal neurons are interesting, it's unclear how practical or scalable these techniques are for real-world applications. Editing individual neurons in large, complex models may be challenging and time-consuming, and the researchers don't fully address the potential risks or unintended consequences of such interventions.
Overall, this paper represents an important step forward in understanding the mechanisms behind multilingual capabilities in LLMs, but more work is needed to fully explore the implications and practical applications of this research.
Conclusion
This paper provides valuable insights into the inner workings of multilingual large language models (LLMs). By analyzing the role of language-specific neurons, vocabulary sharing, and multimodal neuron identification, the researchers shed light on how LLMs are able to understand and generate text in multiple languages.
The findings have important implications for the development of more robust and adaptable multilingual AI systems. Understanding the mechanisms behind LLMs' multilingual capabilities could lead to improvements in machine translation, cross-lingual information retrieval, and other multilingual applications.
While the paper offers promising avenues for further research, it also highlights the need for continued exploration of the limitations and potential risks associated with these techniques. As the field of multilingual AI continues to evolve, this work represents an important step towards unlocking the full potential of large language models and their applications across diverse linguistic domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Language-Specific Neurons: The Key to Multilingual Capabilities in Large Language Models
Tianyi Tang, Wenyang Luo, Haoyang Huang, Dongdong Zhang, Xiaolei Wang, Xin Zhao, Furu Wei, Ji-Rong Wen
0
0
Large language models (LLMs) demonstrate remarkable multilingual capabilities without being pre-trained on specially curated multilingual parallel corpora. It remains a challenging problem to explain the underlying mechanisms by which LLMs process multilingual texts. In this paper, we delve into the composition of Transformer architectures in LLMs to pinpoint language-specific regions. Specially, we propose a novel detection method, language activation probability entropy (LAPE), to identify language-specific neurons within LLMs. Based on LAPE, we conduct comprehensive experiments on several representative LLMs, such as LLaMA-2, BLOOM, and Mistral. Our findings indicate that LLMs' proficiency in processing a particular language is predominantly due to a small subset of neurons, primarily situated in the models' top and bottom layers. Furthermore, we showcase the feasibility to steer the output language of LLMs by selectively activating or deactivating language-specific neurons. Our research provides important evidence to the understanding and exploration of the multilingual capabilities of LLMs.
6/7/2024
How do Large Language Models Handle Multilingualism?
Yiran Zhao, Wenxuan Zhang, Guizhen Chen, Kenji Kawaguchi, Lidong Bing
0
0
Large language models (LLMs) have demonstrated impressive capabilities across diverse languages. This study explores how LLMs handle multilingualism. Based on observed language ratio shifts among layers and the relationships between network structures and certain capabilities, we hypothesize the LLM's multilingual workflow ($texttt{MWork}$): LLMs initially understand the query, converting multilingual inputs into English for task-solving. In the intermediate layers, they employ English for thinking and incorporate multilingual knowledge with self-attention and feed-forward structures, respectively. In the final layers, LLMs generate responses aligned with the original language of the query. To verify $texttt{MWork}$, we introduce Parallel Language-specific Neuron Detection ($texttt{PLND}$) to identify activated neurons for inputs in different languages without any labeled data. Using $texttt{PLND}$, we validate $texttt{MWork}$ through extensive experiments involving the deactivation of language-specific neurons across various layers and structures. Moreover, $texttt{MWork}$ allows fine-tuning of language-specific neurons with a small dataset, enhancing multilingual abilities in a specific language without compromising others. This approach results in an average improvement of $3.6%$ for high-resource languages and $2.3%$ for low-resource languages across all tasks with just $400$ documents.
5/27/2024

MMNeuron: Discovering Neuron-Level Domain-Specific Interpretation in Multimodal Large Language Model
Jiahao Huo, Yibo Yan, Boren Hu, Yutao Yue, Xuming Hu
0
0
Projecting visual features into word embedding space has become a significant fusion strategy adopted by Multimodal Large Language Models (MLLMs). However, its internal mechanisms have yet to be explored. Inspired by multilingual research, we identify domain-specific neurons in multimodal large language models. Specifically, we investigate the distribution of domain-specific neurons and the mechanism of how MLLMs process features from diverse domains. Furthermore, we propose a three-stage framework for language model modules in MLLMs when handling projected image features, and verify this hypothesis using logit lens. Extensive experiments indicate that while current MLLMs exhibit Visual Question Answering (VQA) capability, they may not fully utilize domain-specific information. Manipulating domain-specific neurons properly will result in a 10% change of accuracy at most, shedding light on the development of cross-domain, all-encompassing MLLMs in the future. Our code will be released upon paper notification.
6/18/2024

Unraveling Babel: Exploring Multilingual Activation Patterns of LLMs and Their Applications
Weize Liu, Yinlong Xu, Hongxia Xu, Jintai Chen, Xuming Hu, Jian Wu
0
0
Recently, large language models (LLMs) have achieved tremendous breakthroughs in the field of NLP, but still lack understanding of their internal activities when processing different languages. We designed a method to convert dense LLMs into fine-grained MoE architectures, and then visually studied the multilingual activation patterns of LLMs through expert activation frequency heatmaps. Through comprehensive experiments on different model families, different model sizes, and different variants, we analyzed the distribution of high-frequency activated experts, multilingual shared experts, whether the activation patterns of different languages are related to language families, and the impact of instruction tuning on activation patterns. We further explored leveraging the discovered differences in expert activation frequencies to guide unstructured pruning in two different ways. Experimental results demonstrated that our method significantly outperformed random expert pruning and even exceeded the performance of the original unpruned models in some languages. Additionally, we found that configuring different pruning rates for different layers based on activation level differences could achieve better results. Our findings reveal the multilingual processing mechanisms within LLMs and utilize these insights to offer new perspectives for applications such as model pruning.
6/19/2024