SHIELD: Evaluation and Defense Strategies for Copyright Compliance in LLM Text Generation

0

Sign in to get full access
Overview
- This paper presents SHIELD, a framework for evaluating and defending against copyright infringement in large language model (LLM) text generation.
- The researchers propose techniques to detect and mitigate the risk of LLMs generating text that violates copyrights, while preserving the models' utility.
- Key aspects include developing robust copyright evaluation metrics, training LLMs to avoid copying protected text, and providing self-defense strategies for LLMs to detect and avoid copyright infringement.
Plain English Explanation
The paper introduces a framework called SHIELD that aims to help ensure large language models (LLMs) - powerful AI systems that can generate human-like text - don't copy or reproduce copyrighted material. This is an important issue, as LLMs are becoming increasingly sophisticated and could potentially be used to generate text that infringes on someone else's intellectual property.
The SHIELD framework includes several components to address this challenge. First, it proposes new ways to evaluate LLMs to detect if they are copying protected text. This builds on previous research on LLM memorization and copyright compliance. Second, it explores techniques to train LLMs to avoid generating text that violates copyrights, drawing on work on real-time safeguards for text generation and cross-task defense through instruction tuning. Finally, the paper proposes "self-defense" strategies that would allow LLMs to detect and avoid generating infringing content on their own. This builds on research into LLM self-examination for defense.
The goal is to develop approaches that can help ensure LLMs respect copyrights while still preserving their usefulness for tasks like text generation, summarization, and answering questions. This is important as LLMs become more prevalent and powerful.
Technical Explanation
The paper first reviews related work on detecting and mitigating copyright infringement in text generated by LLMs. This includes research on evaluating LLM memorization and copyright compliance, developing real-time safeguards for text generation, and enabling LLMs to self-examine for potential infringing content.
The core of the SHIELD framework has three main components:
-
Copyright evaluation metrics: The researchers propose new ways to assess whether LLM-generated text violates copyrights, going beyond simply detecting verbatim copying.
-
Copyright-aware training: Techniques are explored to train LLMs to avoid generating text that infringes on copyrights, such as by incorporating copyright compliance into the training objective.
-
LLM self-defense: The paper examines methods that would allow LLMs to independently detect and avoid generating text that violates copyrights, without relying solely on external evaluation.
Through extensive experiments, the authors demonstrate the effectiveness of the SHIELD framework in detecting and mitigating copyright infringement risks in LLM text generation, while preserving the models' utility for downstream applications.
Critical Analysis
The paper makes a strong case for the importance of addressing copyright compliance in LLM text generation, as the proliferation of these powerful AI systems increases the potential for inadvertent or malicious generation of protected content. The proposed SHIELD framework represents a comprehensive approach to tackle this challenge.
One potential limitation is that the copyright evaluation metrics, while more robust than simple verbatim matching, may still struggle to detect more subtle forms of copying or paraphrasing. As language models become more sophisticated, the ability to identify infringement could become more challenging.
Additionally, while the self-defense strategies for LLMs are promising, their effectiveness may depend on the models' ability to accurately self-assess the originality of their generated text. Further research may be needed to ensure these techniques are reliable and do not overly constrain the models' capabilities.
Ongoing work on text generation detection and the necessity of new methods highlights the evolving nature of this challenge and the need for continued innovation in this area.
Conclusion
The SHIELD framework proposed in this paper represents an important step towards ensuring copyright compliance in LLM text generation. By developing robust evaluation metrics, copyright-aware training techniques, and self-defense strategies for LLMs, the researchers aim to mitigate the risk of inadvertent or malicious generation of protected content while preserving the utility of these powerful AI systems.
As LLMs continue to advance and become more widely adopted, addressing issues of copyright infringement will be crucial to maintain the integrity and trustworthiness of text generation. The SHIELD framework provides a solid foundation for further research and development in this critical area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SHIELD: Evaluation and Defense Strategies for Copyright Compliance in LLM Text Generation
Xiaoze Liu, Ting Sun, Tianyang Xu, Feijie Wu, Cunxiang Wang, Xiaoqian Wang, Jing Gao
Large Language Models (LLMs) have transformed machine learning but raised significant legal concerns due to their potential to produce text that infringes on copyrights, resulting in several high-profile lawsuits. The legal landscape is struggling to keep pace with these rapid advancements, with ongoing debates about whether generated text might plagiarize copyrighted materials. Current LLMs may infringe on copyrights or overly restrict non-copyrighted texts, leading to these challenges: (i) the need for a comprehensive evaluation benchmark to assess copyright compliance from multiple aspects; (ii) evaluating robustness against safeguard bypassing attacks; and (iii) developing effective defense targeted against the generation of copyrighted text. To tackle these challenges, we introduce a curated dataset to evaluate methods, test attack strategies, and propose lightweight, real-time defense to prevent the generation of copyrighted text, ensuring the safe and lawful use of LLMs. Our experiments demonstrate that current LLMs frequently output copyrighted text, and that jailbreaking attacks can significantly increase the volume of copyrighted output. Our proposed defense mechanism significantly reduces the volume of copyrighted text generated by LLMs by effectively refusing malicious requests. Code is publicly available at https://github.com/xz-liu/SHIELD
Read more8/22/2024
🧠
0
LLMs and Memorization: On Quality and Specificity of Copyright Compliance
Felix B Mueller, Rebekka Gorge, Anna K Bernzen, Janna C Pirk, Maximilian Poretschkin
Memorization in large language models (LLMs) is a growing concern. LLMs have been shown to easily reproduce parts of their training data, including copyrighted work. This is an important problem to solve, as it may violate existing copyright laws as well as the European AI Act. In this work, we propose a systematic analysis to quantify the extent of potential copyright infringements in LLMs using European law as an example. Unlike previous work, we evaluate instruction-finetuned models in a realistic end-user scenario. Our analysis builds on a proposed threshold of 160 characters, which we borrow from the German Copyright Service Provider Act and a fuzzy text matching algorithm to identify potentially copyright-infringing textual reproductions. The specificity of countermeasures against copyright infringement is analyzed by comparing model behavior on copyrighted and public domain data. We investigate what behaviors models show instead of producing protected text (such as refusal or hallucination) and provide a first legal assessment of these behaviors. We find that there are huge differences in copyright compliance, specificity, and appropriate refusal among popular LLMs. Alpaca, GPT 4, GPT 3.5, and Luminous perform best in our comparison, with OpenGPT-X, Alpaca, and Luminous producing a particularly low absolute number of potential copyright violations. Code will be published soon.
Read more7/1/2024
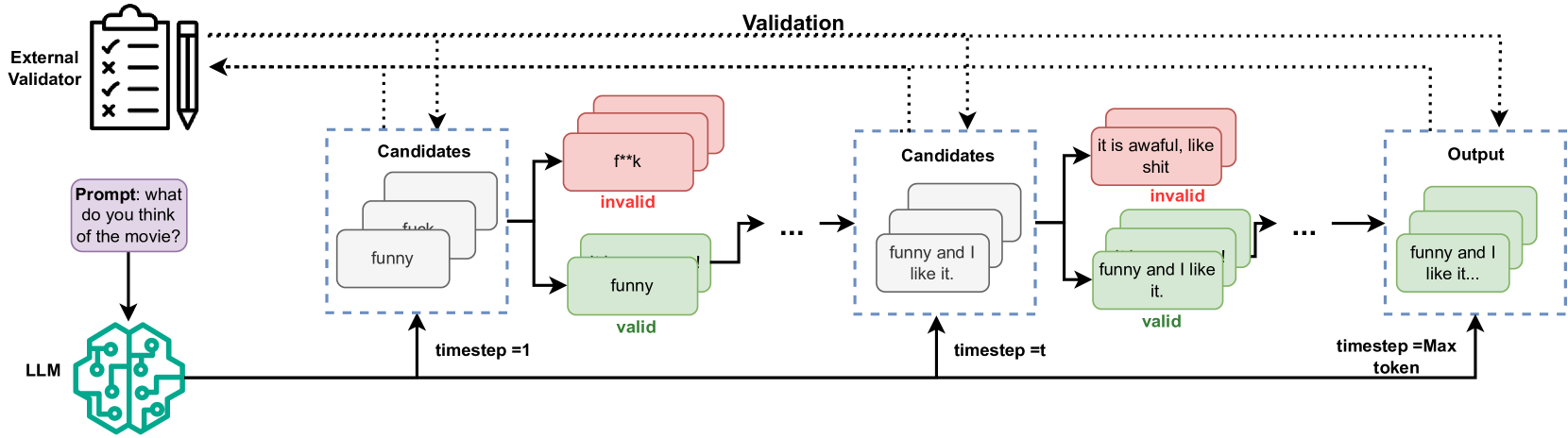
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024

0
Measuring Copyright Risks of Large Language Model via Partial Information Probing
Weijie Zhao, Huajie Shao, Zhaozhuo Xu, Suzhen Duan, Denghui Zhang
Exploring the data sources used to train Large Language Models (LLMs) is a crucial direction in investigating potential copyright infringement by these models. While this approach can identify the possible use of copyrighted materials in training data, it does not directly measure infringing risks. Recent research has shifted towards testing whether LLMs can directly output copyrighted content. Addressing this direction, we investigate and assess LLMs' capacity to generate infringing content by providing them with partial information from copyrighted materials, and try to use iterative prompting to get LLMs to generate more infringing content. Specifically, we input a portion of a copyrighted text into LLMs, prompt them to complete it, and then analyze the overlap between the generated content and the original copyrighted material. Our findings demonstrate that LLMs can indeed generate content highly overlapping with copyrighted materials based on these partial inputs.
Read more9/24/2024