Shoulders of Giants: A Look at the Degree and Utility of Openness in NLP Research

0

Sign in to get full access
Overview
- This paper investigates the degree of openness in natural language processing (NLP) research and its utility for advancing the field.
- It analyzes various aspects of openness, including data, models, and code, and their impact on research progress and reproducibility.
- The paper provides insights into the current state of openness in NLP and offers recommendations for promoting a more open and collaborative research environment.
Plain English Explanation
The paper examines how open and accessible the research in natural language processing (NLP) is. Openness in research refers to making data, models, and code publicly available so that other researchers can build on the work and verify the findings.
The researchers analyzed different aspects of openness, such as how much data, models, and code are shared by NLP researchers, and how this openness affects the progress and reproducibility of the field. They wanted to understand the current state of openness in NLP and find ways to encourage more open and collaborative research.
The paper provides insights into the current level of openness in NLP and offers suggestions for how to make the field more open and accessible to researchers around the world. By promoting openness, the researchers believe NLP can advance more quickly and produce more reliable and impactful results.
Technical Explanation
The paper examines the degree and utility of openness in natural language processing (NLP) research. It analyzes various aspects of openness, including data, models, and code, and their impact on research progress and reproducibility.
The researchers collected data from 1,500 NLP papers published at major conferences and journals. They categorized the papers based on the level of openness across different dimensions, such as whether the data, models, and code were publicly available. They then analyzed how openness correlated with factors like research impact, diversity of applications, and ease of replicability.
The results show that while openness has increased over time, there is still significant room for improvement. Papers with more open data, models, and code tended to have a greater research impact and broader applications. The paper also identified barriers to openness, such as computational resource constraints and concerns about privacy and intellectual property.
Based on their findings, the authors propose a framework for promoting openness in NLP research, which includes guidelines for designing NLP systems that are more adaptable and open-source in nature.
Critical Analysis
The paper provides a comprehensive and well-designed study on the state of openness in NLP research. The authors acknowledge several limitations, such as the potential bias in the paper selection process and the difficulty in fully capturing all aspects of openness.
One potential issue is that the paper focuses primarily on openness at the individual paper level, rather than addressing broader systemic barriers to openness in the NLP community. Factors like funding structures, academic incentives, and cultural norms may also play a significant role in shaping the level of openness in the field.
Additionally, the paper does not delve deeply into the ethical considerations surrounding openness, such as the potential risks of making sensitive data or models publicly available. Further research could explore the tradeoffs between openness and responsible data and model governance.
Overall, the paper offers valuable insights and a thoughtful framework for promoting openness in NLP research. However, continued discussion and collaboration within the community will be necessary to address the complex challenges and fully realize the benefits of increased openness.
Conclusion
This paper provides a comprehensive analysis of the degree and utility of openness in natural language processing (NLP) research. By examining various aspects of openness, including data, models, and code, the authors have shed light on the current state of openness in the field and its impact on research progress and reproducibility.
The findings suggest that increased openness can lead to greater research impact and broader applications, but significant barriers still exist. The authors propose a framework for promoting openness in NLP, which includes guidelines for designing more adaptable and open-source systems.
The insights from this paper have important implications for the NLP research community, as well as the broader field of artificial intelligence. By fostering a more open and collaborative research environment, the NLP field can accelerate progress, ensure the reliability of its findings, and unlock new opportunities for innovation and societal impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Shoulders of Giants: A Look at the Degree and Utility of Openness in NLP Research
Surangika Ranathunga, Nisansa de Silva, Dilith Jayakody, Aloka Fernando
We analysed a sample of NLP research papers archived in ACL Anthology as an attempt to quantify the degree of openness and the benefit of such an open culture in the NLP community. We observe that papers published in different NLP venues show different patterns related to artefact reuse. We also note that more than 30% of the papers we analysed do not release their artefacts publicly, despite promising to do so. Further, we observe a wide language-wise disparity in publicly available NLP-related artefacts.
Read more6/11/2024

0
Collaboration or Corporate Capture? Quantifying NLP's Reliance on Industry Artifacts and Contributions
Will Aitken, Mohamed Abdalla, Karen Rudie, Catherine Stinson
Impressive performance of pre-trained models has garnered public attention and made news headlines in recent years. Almost always, these models are produced by or in collaboration with industry. Using them is critical for competing on natural language processing (NLP) benchmarks and correspondingly to stay relevant in NLP research. We surveyed 100 papers published at EMNLP 2022 to determine the degree to which researchers rely on industry models, other artifacts, and contributions to publish in prestigious NLP venues and found that the ratio of their citation is at least three times greater than what would be expected. Our work serves as a scaffold to enable future researchers to more accurately address whether: 1) Collaboration with industry is still collaboration in the absence of an alternative or 2) if NLP inquiry has been captured by the motivations and research direction of private corporations.
Read more6/26/2024
🎲
0
Towards a Framework for Openness in Foundation Models: Proceedings from the Columbia Convening on Openness in Artificial Intelligence
Adrien Basdevant, Camille Franc{c}ois, Victor Storchan, Kevin Bankston, Ayah Bdeir, Brian Behlendorf, Merouane Debbah, Sayash Kapoor, Yann LeCun, Mark Surman, Helen King-Turvey, Nathan Lambert, Stefano Maffulli, Nik Marda, Govind Shivkumar, Justine Tunney
Over the past year, there has been a robust debate about the benefits and risks of open sourcing foundation models. However, this discussion has often taken place at a high level of generality or with a narrow focus on specific technical attributes. In part, this is because defining open source for foundation models has proven tricky, given its significant differences from traditional software development. In order to inform more practical and nuanced decisions about opening AI systems, including foundation models, this paper presents a framework for grappling with openness across the AI stack. It summarizes previous work on this topic, analyzes the various potential reasons to pursue openness, and outlines how openness varies in different parts of the AI stack, both at the model and at the system level. In doing so, its authors hope to provide a common descriptive framework to deepen a nuanced and rigorous understanding of openness in AI and enable further work around definitions of openness and safety in AI.
Read more5/28/2024
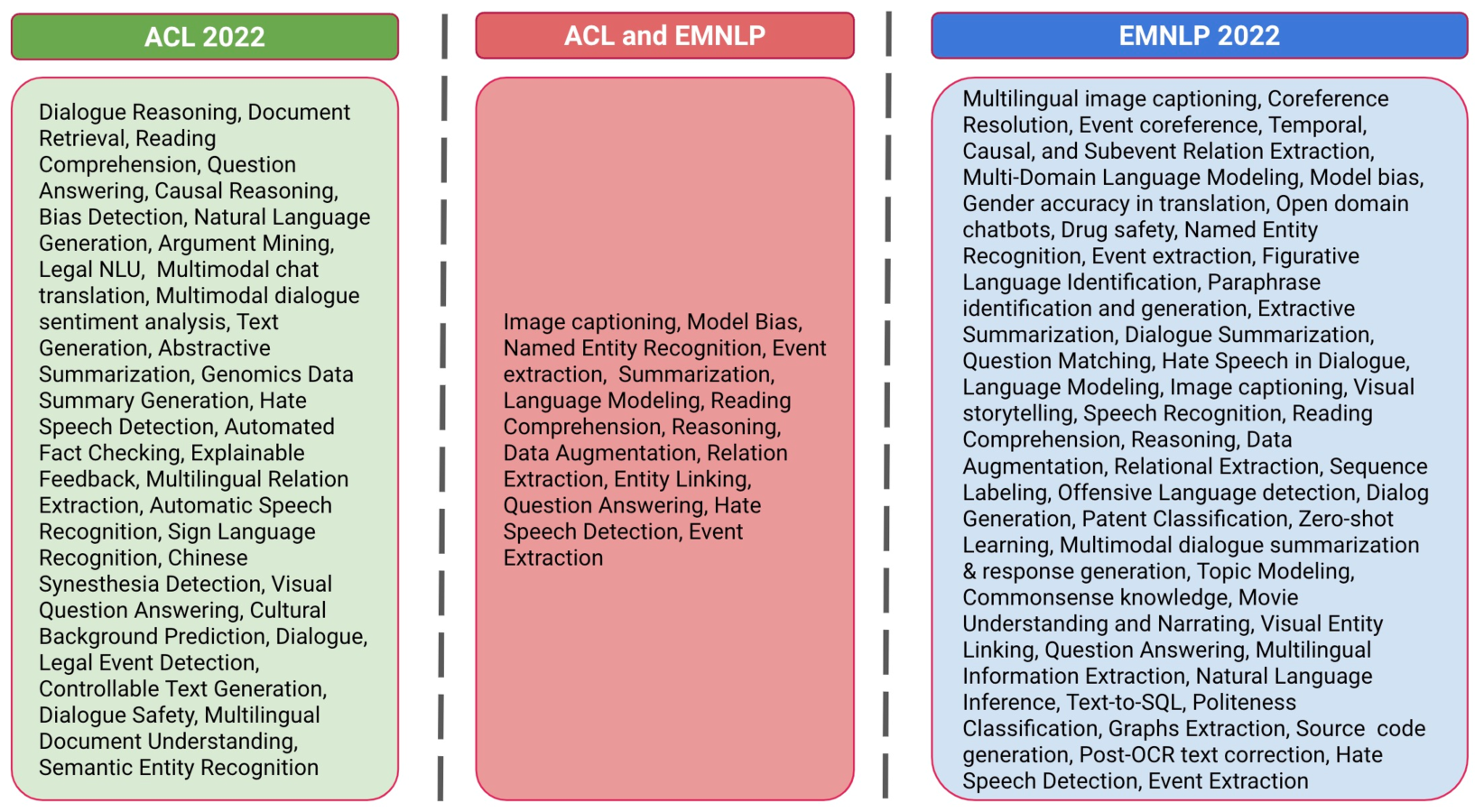
0
Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
Jesse Atuhurra, Hidetaka Kamigaito
Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
Read more7/16/2024