Collaboration or Corporate Capture? Quantifying NLP's Reliance on Industry Artifacts and Contributions

0

Sign in to get full access
Overview
- This paper investigates the reliance of natural language processing (NLP) research on industry-provided data and resources.
- The researchers quantify the extent to which NLP research is dependent on artifacts and contributions from industry.
- They analyze citations, dataset usage, and author affiliations in NLP papers to understand the degree of industry influence.
Plain English Explanation
The paper looks at how much the field of natural language processing (NLP) relies on resources and data provided by companies and tech giants. NLP is the branch of artificial intelligence that focuses on understanding and generating human language. The researchers wanted to see how much NLP research depends on information and tools created by industry, rather than academia.
To do this, they analyzed citations, the datasets used in studies, and the affiliations of the authors in NLP research papers. This allows them to quantify the degree of industry influence on the field. They found that a significant portion of NLP work relies on industry-provided artifacts like datasets, software libraries, and expert contributions.
This raises questions about whether the growth of NLP is being driven more by collaboration or corporate capture. On one hand, the involvement of industry can accelerate progress by providing valuable resources. But it also means the research agenda may be shaped more by commercial interests than pure scientific inquiry. The paper highlights the need to understand the limitations and biases that can come from industry's outsized role in NLP.
Technical Explanation
The researchers conducted a comprehensive analysis of citations, dataset usage, and author affiliations in NLP publications to quantify the field's reliance on industry-provided artifacts and contributions. They examined over 23,000 NLP papers from major conferences like ACL and EMNLP.
The citation analysis revealed that a substantial proportion of NLP papers cite works from industry authors or affiliations. They also found a high rate of citation for industry-provided datasets, which are commonly used in benchmark tasks.
Analysis of author affiliations showed that industry researchers make up a significant and growing portion of the NLP community, often collaborating with academics. This suggests increasing integration between academia and industry in the field.
Overall, the findings indicate that NLP research is heavily dependent on resources, data, and expertise originating from technology companies and other industry sources. This raises questions about the potential skewing of research priorities and the risk of "computational job market analysis" favoring commercial applications over basic scientific understanding.
Critical Analysis
The paper provides valuable insights into the complex relationship between industry and academia in the NLP field. However, it is important to note some potential limitations and areas for further research:
The analysis focuses on citations, datasets, and author affiliations, but may not capture other forms of industry influence, such as funding, collaboration on specific projects, or less visible contributions. Examining the "topics, authors, and institutions" involved in large language model research could offer additional perspectives.
The study does not delve into the nuances of how industry involvement can both enable and constrain NLP research. In some cases, industry resources may accelerate progress, while in others, they may lead to a narrowing of research focus or the exclusion of certain lines of inquiry.
Further research could explore the specific mechanisms and incentives driving industry's participation in NLP, as well as the potential implications for the field's long-term trajectory and societal impact. Understanding the dynamics of "when not to trust language models" is also crucial.
Conclusion
This paper sheds light on the significant and growing influence of industry in the field of natural language processing. By quantifying the reliance on industry-provided data, tools, and expert contributions, the researchers highlight the complex, and potentially problematic, relationship between academia and the private sector in this important area of AI research.
The findings raise important questions about the potential trade-offs between the benefits of industry collaboration and the risks of "corporate capture" of the NLP research agenda. As the field continues to evolve, it will be crucial to carefully examine the implications of this industry-academia dynamic and strive for a balance that serves the broader interests of scientific progress and societal wellbeing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Collaboration or Corporate Capture? Quantifying NLP's Reliance on Industry Artifacts and Contributions
Will Aitken, Mohamed Abdalla, Karen Rudie, Catherine Stinson
Impressive performance of pre-trained models has garnered public attention and made news headlines in recent years. Almost always, these models are produced by or in collaboration with industry. Using them is critical for competing on natural language processing (NLP) benchmarks and correspondingly to stay relevant in NLP research. We surveyed 100 papers published at EMNLP 2022 to determine the degree to which researchers rely on industry models, other artifacts, and contributions to publish in prestigious NLP venues and found that the ratio of their citation is at least three times greater than what would be expected. Our work serves as a scaffold to enable future researchers to more accurately address whether: 1) Collaboration with industry is still collaboration in the absence of an alternative or 2) if NLP inquiry has been captured by the motivations and research direction of private corporations.
Read more6/26/2024
🌿
0
The Elephant in the Room: Analyzing the Presence of Big Tech in Natural Language Processing Research
Mohamed Abdalla, Jan Philip Wahle, Terry Ruas, Aur'elie N'ev'eol, Fanny Ducel, Saif M. Mohammad, Karen Fort
Recent advances in deep learning methods for natural language processing (NLP) have created new business opportunities and made NLP research critical for industry development. As one of the big players in the field of NLP, together with governments and universities, it is important to track the influence of industry on research. In this study, we seek to quantify and characterize industry presence in the NLP community over time. Using a corpus with comprehensive metadata of 78,187 NLP publications and 701 resumes of NLP publication authors, we explore the industry presence in the field since the early 90s. We find that industry presence among NLP authors has been steady before a steep increase over the past five years (180% growth from 2017 to 2022). A few companies account for most of the publications and provide funding to academic researchers through grants and internships. Our study shows that the presence and impact of the industry on natural language processing research are significant and fast-growing. This work calls for increased transparency of industry influence in the field.
Read more7/17/2024
🌿
0
We are Who We Cite: Bridges of Influence Between Natural Language Processing and Other Academic Fields
Jan Philip Wahle, Terry Ruas, Mohamed Abdalla, Bela Gipp, Saif M. Mohammad
Natural Language Processing (NLP) is poised to substantially influence the world. However, significant progress comes hand-in-hand with substantial risks. Addressing them requires broad engagement with various fields of study. Yet, little empirical work examines the state of such engagement (past or current). In this paper, we quantify the degree of influence between 23 fields of study and NLP (on each other). We analyzed ~77k NLP papers, ~3.1m citations from NLP papers to other papers, and ~1.8m citations from other papers to NLP papers. We show that, unlike most fields, the cross-field engagement of NLP, measured by our proposed Citation Field Diversity Index (CFDI), has declined from 0.58 in 1980 to 0.31 in 2022 (an all-time low). In addition, we find that NLP has grown more insular -- citing increasingly more NLP papers and having fewer papers that act as bridges between fields. NLP citations are dominated by computer science; Less than 8% of NLP citations are to linguistics, and less than 3% are to math and psychology. These findings underscore NLP's urgent need to reflect on its engagement with various fields.
Read more7/17/2024
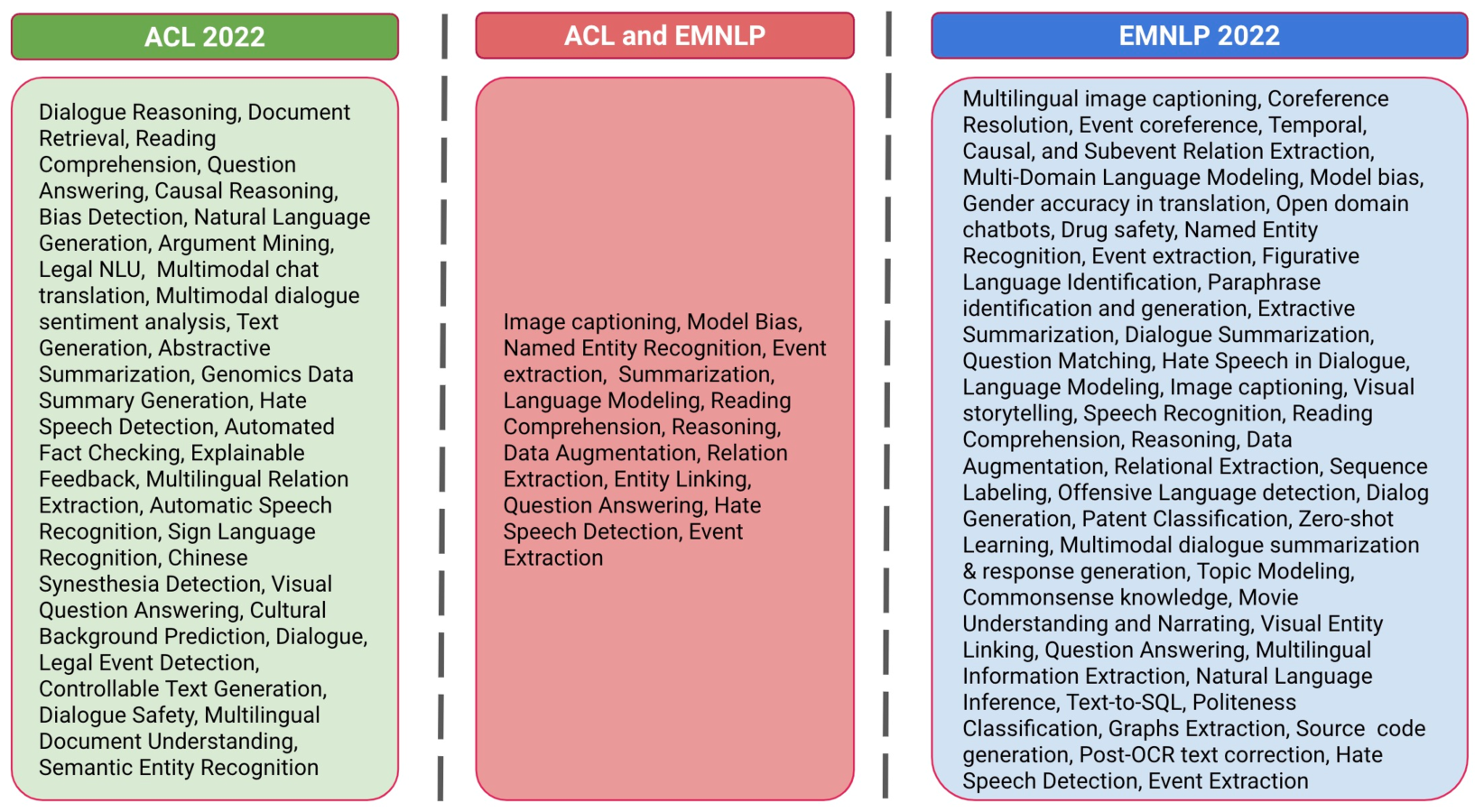
0
Revealing Trends in Datasets from the 2022 ACL and EMNLP Conferences
Jesse Atuhurra, Hidetaka Kamigaito
Natural language processing (NLP) has grown significantly since the advent of the Transformer architecture. Transformers have given birth to pre-trained large language models (PLMs). There has been tremendous improvement in the performance of NLP systems across several tasks. NLP systems are on par or, in some cases, better than humans at accomplishing specific tasks. However, it remains the norm that emph{better quality datasets at the time of pretraining enable PLMs to achieve better performance, regardless of the task.} The need to have quality datasets has prompted NLP researchers to continue creating new datasets to satisfy particular needs. For example, the two top NLP conferences, ACL and EMNLP, accepted ninety-two papers in 2022, introducing new datasets. This work aims to uncover the trends and insights mined within these datasets. Moreover, we provide valuable suggestions to researchers interested in curating datasets in the future.
Read more7/16/2024