The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models

0

Sign in to get full access
Overview
- The SIFo benchmark investigates the sequential instruction following ability of large language models.
- It provides a comprehensive evaluation of how well these models can understand and execute step-by-step instructions.
- The benchmark covers a diverse set of tasks ranging from simple to complex, testing the models' reasoning and task-execution capabilities.
Plain English Explanation
The research paper focuses on evaluating the ability of large language models, such as GPT-3, to follow sequential instructions. In other words, it examines how well these models can understand and execute step-by-step tasks or procedures.
The researchers developed the SIFo (Sequential Instruction Following) benchmark, which consists of a variety of tasks that test the models' understanding and execution of instructions. These tasks range from simple, straightforward instructions to more complex, multi-step procedures. The goal is to assess the models' reasoning abilities, their capacity to follow instructions accurately, and their overall performance in task execution.
By using this benchmark, the researchers can gain insights into the current state of large language models' instruction following capabilities. This information can be valuable for developers and researchers working on language models, as it helps identify areas for improvement and informs the design of more effective and capable AI systems.
Technical Explanation
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models presents a comprehensive evaluation of the sequential instruction following capabilities of large language models.
The researchers developed the SIFo benchmark, which consists of a diverse set of tasks that test the models' ability to understand and execute step-by-step instructions. These tasks cover a wide range of complexity, from simple, single-step instructions to more complex, multi-step procedures. The benchmark includes tasks in various domains, such as cooking, DIY, and task planning, to assess the models' generalization capabilities.
The researchers evaluated the performance of several large language models, including GPT-3, on the SIFo benchmark. The models were required to complete the tasks by generating step-by-step responses, which were then assessed for accuracy and task completion. The results revealed significant variations in the models' instruction following abilities, with some models performing better on simpler tasks, while others exhibited stronger performance on more complex procedures.
The findings from this study provide valuable insights into the current state of large language models' instruction following capabilities. They highlight the need for further advancements in areas such as reasoning, task planning, and multi-step execution to improve the models' ability to follow instructions accurately and effectively.
Critical Analysis
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models presents a comprehensive and well-designed evaluation of large language models' instruction following abilities. However, the paper also acknowledges several limitations and areas for further research.
One potential limitation is the scope of the benchmark tasks. While the researchers have included a diverse set of tasks, there may be additional types of instructions or procedures that could be explored to further stress-test the models' capabilities. For example, the inclusion of more open-ended or ambiguous instructions could provide additional insights into the models' reasoning and language understanding.
Additionally, the paper does not delve deeply into the differences in performance between the various large language models evaluated. A more detailed analysis of the specific strengths, weaknesses, and architectural differences that may contribute to the models' varying instruction following abilities could provide valuable insights for future model development.
Furthermore, the paper does not extensively discuss the potential real-world implications and applications of the research findings. Exploring how the instruction following capabilities of these models could be leveraged in practical scenarios, such as in robotics, task automation, or human-AI collaboration, could enhance the impact and relevance of this work.
Overall, the SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models represents an important step forward in evaluating the instruction following capabilities of large language models. The insights gained from this research can inform the development of more capable and reliable AI systems that can effectively interact with and assist humans in a wide range of tasks.
Conclusion
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models presents a comprehensive evaluation of the instruction following capabilities of large language models. The SIFo benchmark provides a diverse set of tasks that test the models' understanding and execution of step-by-step instructions, revealing significant variations in their performance.
The findings from this research highlight the current limitations and areas for improvement in the instruction following abilities of large language models. By identifying these gaps, the study can inform the development of more capable and reliable AI systems that can effectively interact with and assist humans in a wide range of tasks, from simple to complex procedures.
As language models continue to advance, the insights gained from the SIFo benchmark and similar evaluations will be crucial in shaping the future of human-AI interaction and collaboration, ultimately leading to more effective and trustworthy AI-powered applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The SIFo Benchmark: Investigating the Sequential Instruction Following Ability of Large Language Models
Xinyi Chen, Baohao Liao, Jirui Qi, Panagiotis Eustratiadis, Christof Monz, Arianna Bisazza, Maarten de Rijke
Following multiple instructions is a crucial ability for large language models (LLMs). Evaluating this ability comes with significant challenges: (i) limited coherence between multiple instructions, (ii) positional bias where the order of instructions affects model performance, and (iii) a lack of objectively verifiable tasks. To address these issues, we introduce a benchmark designed to evaluate models' abilities to follow multiple instructions through sequential instruction following (SIFo) tasks. In SIFo, the successful completion of multiple instructions is verifiable by examining only the final instruction. Our benchmark evaluates instruction following using four tasks (text modification, question answering, mathematics, and security rule following), each assessing different aspects of sequential instruction following. Our evaluation of popular LLMs, both closed-source and open-source, shows that more recent and larger models significantly outperform their older and smaller counterparts on the SIFo tasks, validating the benchmark's effectiveness. All models struggle with following sequences of instructions, hinting at an important lack of robustness of today's language models.
Read more7/1/2024

0
Beyond Instruction Following: Evaluating Rule Following of Large Language Models
Wangtao Sun, Chenxiang Zhang, Xueyou Zhang, Ziyang Huang, Haotian Xu, Pei Chen, Shizhu He, Jun Zhao, Kang Liu
Although Large Language Models (LLMs) have demonstrated strong instruction-following ability, they are further supposed to be controlled and guided by rules in real-world scenarios to be safe, accurate, and intelligent. This demands the possession of inferential rule-following capability of LLMs. However, few works have made a clear evaluation of the inferential rule-following capability of LLMs. Previous studies that try to evaluate the inferential rule-following capability of LLMs fail to distinguish the inferential rule-following scenarios from the instruction-following scenarios. Therefore, this paper first clarifies the concept of inferential rule-following and proposes a comprehensive benchmark, RuleBench, to evaluate a diversified range of inferential rule-following abilities. Our experimental results on a variety of LLMs show that they are still limited in following rules. Our analysis based on the evaluation results provides insights into the improvements for LLMs toward a better inferential rule-following intelligent agent. We further propose Inferential Rule-Following Tuning (IRFT), which outperforms IFT in helping LLMs solve RuleBench. The data and code can be found at: https://anonymous.4open.science/r/llm-rule-following-B3E3/
Read more8/20/2024
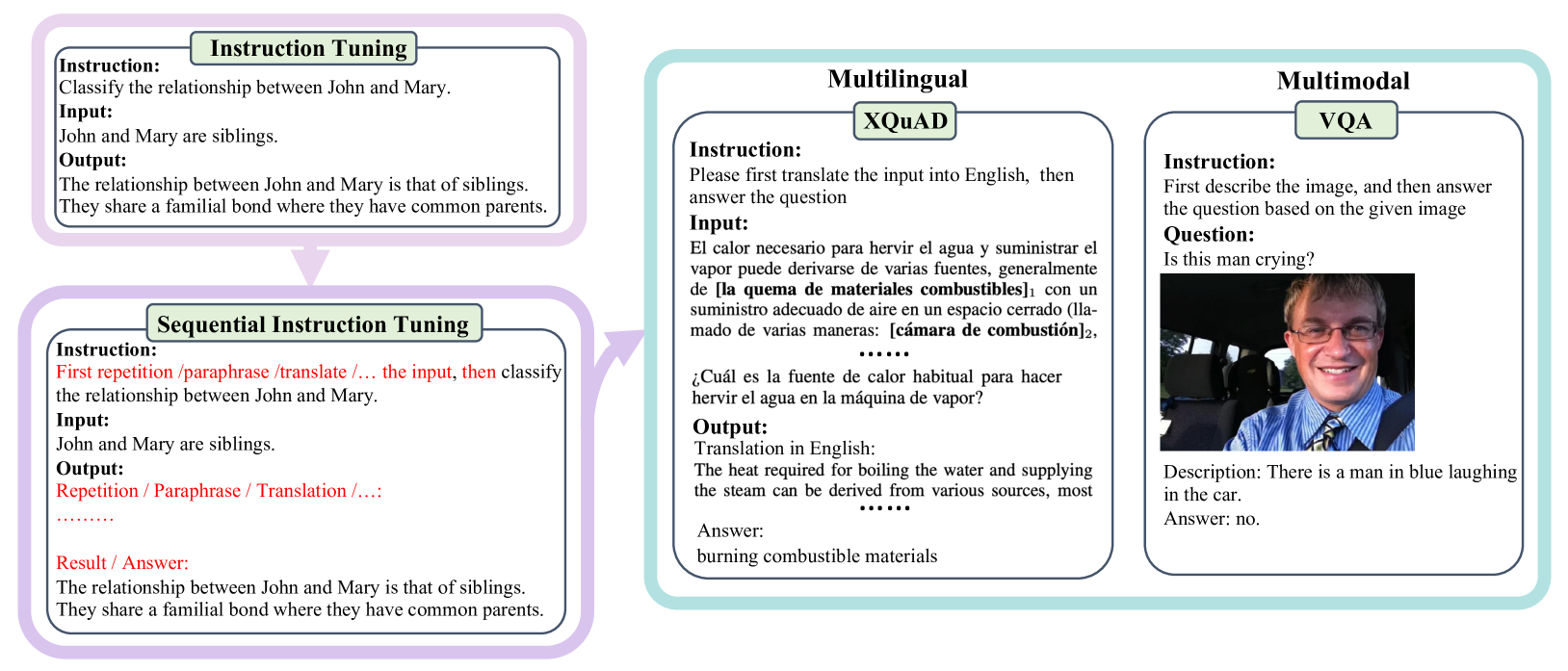
0
SIT: Fine-tuning Large Language Models with Sequential Instructions
Hanxu Hu, Simon Yu, Pinzhen Chen, Edoardo M. Ponti
Despite the success of existing instruction-tuned models, we find that they usually struggle to respond to queries with multiple instructions. This impairs their performance in complex problems whose solution consists of multiple intermediate tasks. Thus, we contend that part of the fine-tuning data mixture should be sequential--containing a chain of interrelated tasks. We first approach sequential instruction tuning from a task-driven perspective, manually creating interpretable intermediate tasks for multilingual and visual question answering: namely translate then predict and caption then answer. Next, we automate this process by turning instructions in existing datasets (e.g., Alpaca and FlanCoT) into diverse and complex sequential instructions, making our method general-purpose. Models that underwent our sequential instruction tuning show improved results in coding, maths, and open-ended generation. Moreover, we put forward a new benchmark named SeqEval to evaluate a model's ability to follow all the instructions in a sequence, which further corroborates the benefits of our fine-tuning method. We hope that our endeavours will open new research avenues on instruction tuning for complex tasks.
Read more7/4/2024

0
FollowIR: Evaluating and Teaching Information Retrieval Models to Follow Instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, Luca Soldaini
Modern Language Models (LMs) are capable of following long and complex instructions that enable a large and diverse set of user requests. While Information Retrieval (IR) models use these LMs as the backbone of their architectures, virtually none of them allow users to provide detailed instructions alongside queries, thus limiting their ability to satisfy complex information needs. In this work, we study the use of instructions in IR systems. First, we introduce our dataset FollowIR, which contains a rigorous instruction evaluation benchmark as well as a training set for helping IR models learn to better follow real-world instructions. FollowIR repurposes detailed instructions -- also known as narratives -- developed for professional assessors to evaluate retrieval systems. In particular, we build our benchmark from three collections curated for shared tasks at the Text REtrieval Conference (TREC). These collections contains hundreds to thousands of labeled documents per query, making them suitable for our exploration. Through this process, we can measure how well IR models follow instructions, through a new pairwise evaluation framework. Our results indicate that existing retrieval models fail to correctly use instructions, using them for basic keywords and struggling to understand long-form information. However, we show that it is possible for IR models to learn to follow complex instructions: our new FollowIR-7B model has significant improvements after fine-tuning on our training set.
Read more5/8/2024