SIT: Fine-tuning Large Language Models with Sequential Instructions

0
Sign in to get full access
Overview
- This paper explores a novel technique called "Phased Instruction Fine-Tuning" for improving the performance of large language models on sequential instruction tasks.
- The authors demonstrate that by fine-tuning language models on a sequence of instructions, rather than a single instruction, model performance can be significantly enhanced.
- The paper also discusses the potential benefits of this approach, including improved generalization, robustness, and the ability to handle more complex, multi-step tasks.
Plain English Explanation
The researchers in this study looked at a new way to train large language models, which are AI systems that can understand and generate human-like text. Typically, these models are trained on a huge amount of text data from the internet, which allows them to learn the patterns and structure of language.
However, the researchers found that when these models are then asked to perform specific tasks, like following a set of instructions, they may not perform as well as desired. To address this, the researchers developed a new training approach called "Phased Instruction Fine-Tuning."
The key idea is to train the language model not on a single instruction, but on a sequence of instructions. This helps the model better understand how to follow a series of steps to complete a task, rather than just responding to a single command. The researchers found that this approach led to significant improvements in the model's ability to follow instructions accurately and complete more complex, multi-step tasks.
This is an important development because it can help make these powerful language models more useful for real-world applications, where being able to understand and follow instructions is crucial. By improving the models' performance on sequential instruction tasks, the researchers have taken a step towards making AI systems that can better assist humans with a wide range of tasks.
Technical Explanation
The paper proposes a novel technique called "Phased Instruction Fine-Tuning" (PIFT) for improving the performance of large language models on sequential instruction tasks. The key idea is to fine-tune the language model not on a single instruction, but on a sequence of instructions.
Typically, when fine-tuning a language model for a specific task, the model is trained on a dataset of input-output pairs, where the input is a single instruction and the output is the desired response. In contrast, the PIFT approach involves presenting the model with a sequence of instructions, where each instruction builds upon the previous ones.
The authors hypothesize that this phased approach to fine-tuning can help the model better understand the structure and flow of multi-step tasks, leading to improved performance and generalization. To validate this, the researchers conduct experiments on several benchmark instruction-following datasets, comparing the PIFT approach to more traditional fine-tuning methods.
The results show that the PIFT approach leads to significant improvements in the model's ability to follow instructions accurately and complete more complex, multi-step tasks. The authors attribute this to the model's enhanced understanding of the sequential nature of the instructions and the relationships between the individual steps.
The paper also discusses the potential benefits of the PIFT approach, including improved robustness to novel instructions and the ability to handle more complex, open-ended tasks. The authors suggest that this technique could have wide-ranging applications in areas such as task automation, personal assistants, and interactive problem-solving systems.
Critical Analysis
The paper presents a novel and promising approach to improving the performance of large language models on sequential instruction tasks. The authors make a compelling case for the benefits of the PIFT approach, and the experimental results provide strong evidence to support their claims.
One potential limitation of the study is the relatively narrow scope of the evaluated tasks, which primarily involve following step-by-step instructions. While this is an important domain, it would be valuable to see how the PIFT approach performs on more open-ended, multi-step tasks that require higher-level reasoning and planning.
Additionally, the paper does not delve into the underlying mechanisms by which the PIFT approach improves model performance. A deeper exploration of the model's internal representations and decision-making processes could provide valuable insights into the strengths and limitations of this technique.
It would also be interesting to see how the PIFT approach compares to other instruction-tuning methods, such as Towards Robust Instruction Tuning, Contrastive Instruction Tuning, and Instruction Tuning Loss over Instructions. A more comprehensive comparison could help identify the unique strengths and weaknesses of each approach.
Finally, the potential impact of the PIFT technique on real-world applications, such as BioInstructGPT, is an important area for further research and exploration.
Conclusion
The "Phased Instruction Fine-Tuning" approach presented in this paper represents a significant advancement in the field of language model fine-tuning. By training models on sequences of instructions rather than single instructions, the researchers have demonstrated substantial improvements in the models' ability to follow instructions accurately and complete more complex, multi-step tasks.
This technique has the potential to enhance the utility of large language models in a wide range of applications, from task automation and personal assistants to interactive problem-solving systems. As the field of AI continues to evolve, innovative approaches like PIFT will be crucial for unlocking the full potential of these powerful language models and making them more useful and accessible to everyone.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SIT: Fine-tuning Large Language Models with Sequential Instructions
Hanxu Hu, Simon Yu, Pinzhen Chen, Edoardo M. Ponti
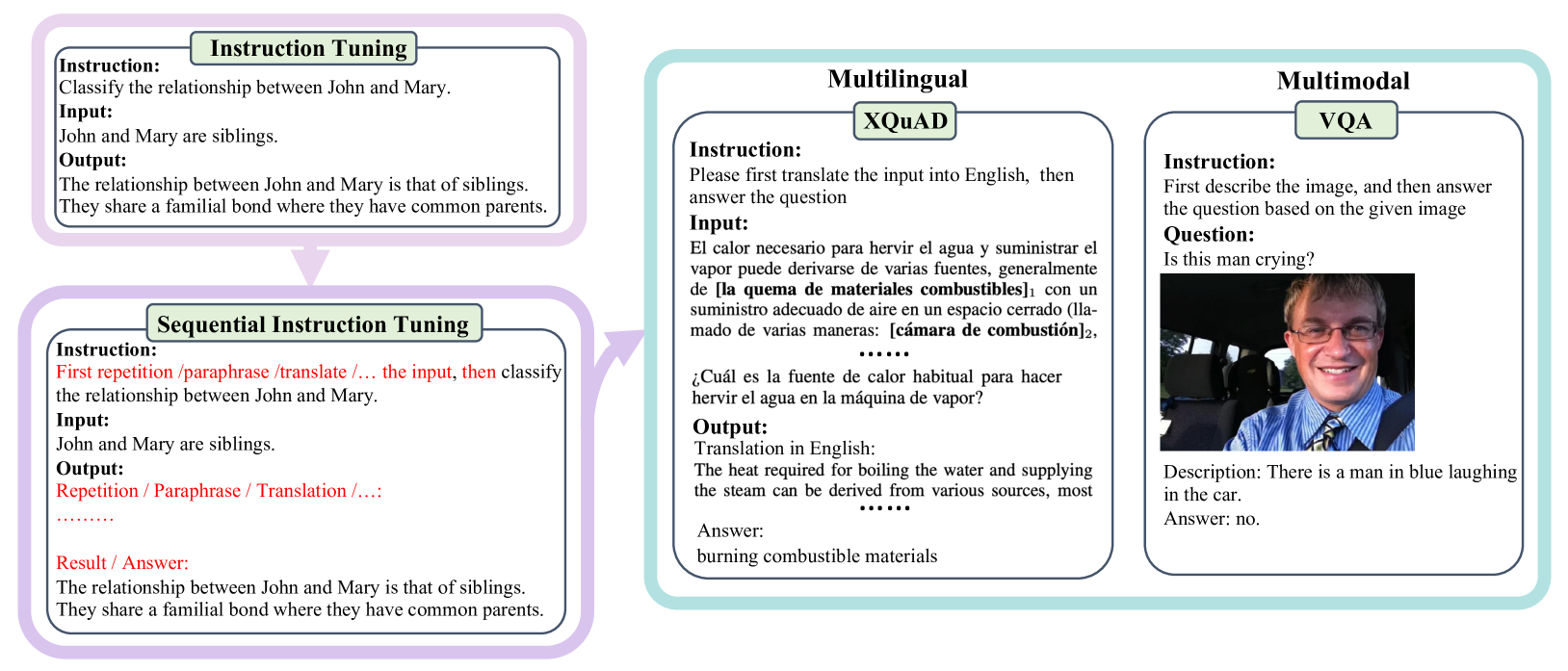
Despite the success of existing instruction-tuned models, we find that they usually struggle to respond to queries with multiple instructions. This impairs their performance in complex problems whose solution consists of multiple intermediate tasks. Thus, we contend that part of the fine-tuning data mixture should be sequential--containing a chain of interrelated tasks. We first approach sequential instruction tuning from a task-driven perspective, manually creating interpretable intermediate tasks for multilingual and visual question answering: namely translate then predict and caption then answer. Next, we automate this process by turning instructions in existing datasets (e.g., Alpaca and FlanCoT) into diverse and complex sequential instructions, making our method general-purpose. Models that underwent our sequential instruction tuning show improved results in coding, maths, and open-ended generation. Moreover, we put forward a new benchmark named SeqEval to evaluate a model's ability to follow all the instructions in a sequence, which further corroborates the benefits of our fine-tuning method. We hope that our endeavours will open new research avenues on instruction tuning for complex tasks.
Read more7/4/2024

0
Phased Instruction Fine-Tuning for Large Language Models
Wei Pang, Chuan Zhou, Xiao-Hua Zhou, Xiaojie Wang
Instruction Fine-Tuning enhances pre-trained language models from basic next-word prediction to complex instruction-following. However, existing One-off Instruction Fine-Tuning (One-off IFT) method, applied on a diverse instruction, may not effectively boost models' adherence to instructions due to the simultaneous handling of varying instruction complexities. To improve this, Phased Instruction Fine-Tuning (Phased IFT) is proposed, based on the idea that learning to follow instructions is a gradual process. It assesses instruction difficulty using GPT-4, divides the instruction data into subsets of increasing difficulty, and uptrains the model sequentially on these subsets. Experiments with Llama-2 7B/13B/70B, Llama3 8/70B and Mistral-7B models using Alpaca data show that Phased IFT significantly outperforms One-off IFT, supporting the progressive alignment hypothesis and providing a simple and efficient way to enhance large language models. Codes and datasets from our experiments are freely available at https://github.com/xubuvd/PhasedSFT.
Read more6/18/2024

0
Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
Read more6/17/2024

0
Instruction Mining: Instruction Data Selection for Tuning Large Language Models
Yihan Cao, Yanbin Kang, Chi Wang, Lichao Sun
Large language models (LLMs) are initially pretrained for broad capabilities and then finetuned with instruction-following datasets to improve their performance in interacting with humans. Despite advances in finetuning, a standardized guideline for selecting high-quality datasets to optimize this process remains elusive. In this paper, we first propose InstructMining, an innovative method designed for automatically selecting premium instruction-following data for finetuning LLMs. Specifically, InstructMining utilizes natural language indicators as a measure of data quality, applying them to evaluate unseen datasets. During experimentation, we discover that double descent phenomenon exists in large language model finetuning. Based on this observation, we further leverage BlendSearch to help find the best subset among the entire dataset (i.e., 2,532 out of 100,000). Experiment results show that InstructMining-7B achieves state-of-the-art performance on two of the most popular benchmarks: LLM-as-a-judge and Huggingface OpenLLM leaderboard.
Read more7/30/2024