A Simple Mixture Policy Parameterization for Improving Sample Efficiency of CVaR Optimization
2403.11062
0
0
Abstract
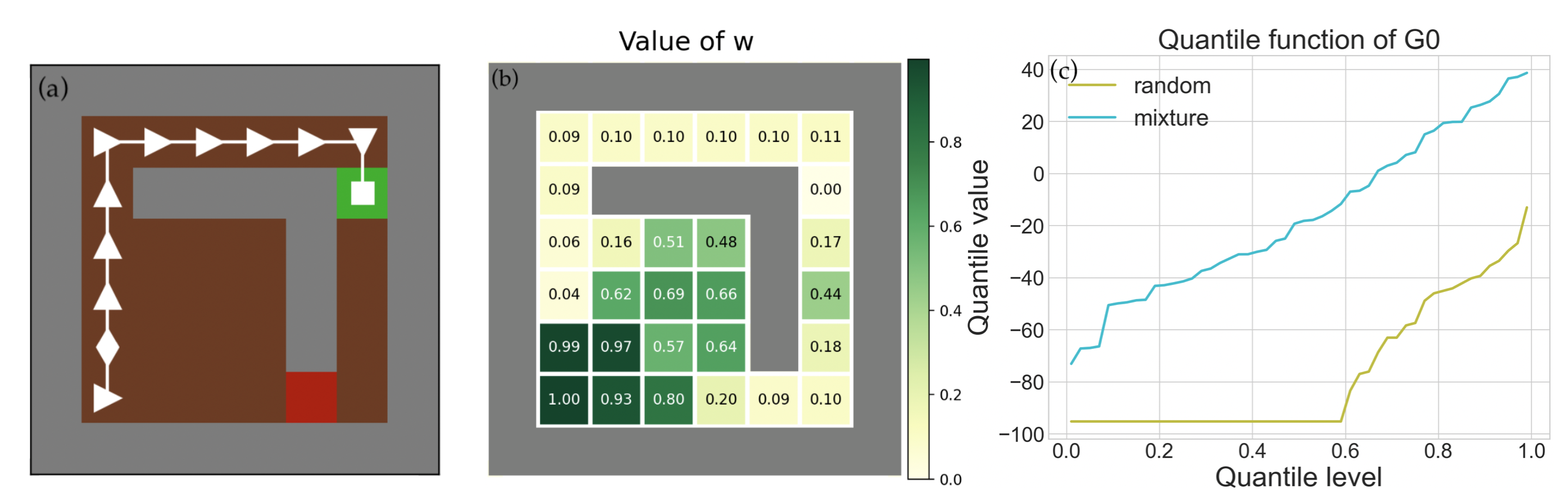
Reinforcement learning algorithms utilizing policy gradients (PG) to optimize Conditional Value at Risk (CVaR) face significant challenges with sample inefficiency, hindering their practical applications. This inefficiency stems from two main facts: a focus on tail-end performance that overlooks many sampled trajectories, and the potential of gradient vanishing when the lower tail of the return distribution is overly flat. To address these challenges, we propose a simple mixture policy parameterization. This method integrates a risk-neutral policy with an adjustable policy to form a risk-averse policy. By employing this strategy, all collected trajectories can be utilized for policy updating, and the issue of vanishing gradients is counteracted by stimulating higher returns through the risk-neutral component, thus lifting the tail and preventing flatness. Our empirical study reveals that this mixture parameterization is uniquely effective across a variety of benchmark domains. Specifically, it excels in identifying risk-averse CVaR policies in some Mujoco environments where the traditional CVaR-PG fails to learn a reasonable policy.
Create account to get full access
Overview
- This paper introduces a simple mixture policy parameterization to improve the sample efficiency of Conditional Value-at-Risk (CVaR) optimization in reinforcement learning.
- The proposed approach combines a risk-neutral policy with a risk-averse policy, allowing the agent to effectively explore the environment while still optimizing for risk-sensitive objectives.
- The authors demonstrate the effectiveness of their method on several benchmark tasks, showing improved performance compared to existing risk-averse reinforcement learning algorithms.
Plain English Explanation
In reinforcement learning, agents often need to balance exploration (trying new things) and exploitation (using what they've learned) to achieve their goals. When the agent's goal is to minimize risk, rather than just maximize reward, this becomes even more challenging.
The authors of this paper propose a new way to parameterize the agent's policy that can help with this. Their approach combines a "risk-neutral" policy, which explores the environment more freely, with a "risk-averse" policy, which is more cautious and tries to avoid bad outcomes. By blending these two policies together, the agent can effectively explore the environment while still optimizing for a risk-sensitive objective, like Conditional Value-at-Risk.
The key advantage of this mixture policy parameterization is that it can improve the sample efficiency of the learning process - the agent can learn more effectively from the experiences it gathers, compared to other risk-averse reinforcement learning methods. The authors demonstrate this by testing their approach on several benchmark tasks, where it outperforms existing algorithms.
Technical Explanation
The paper formulates the reinforcement learning problem as a risk-sensitive Markov Decision Process (MDP), where the agent's goal is to optimize for Conditional Value-at-Risk (CVaR) instead of just maximizing expected reward. To address the challenges of this risk-sensitive setting, the authors propose a simple mixture policy parameterization.
The agent's policy is represented as a convex combination of a "risk-neutral" policy and a "risk-averse" policy. The risk-neutral policy is optimized to maximize expected reward, while the risk-averse policy is optimized to minimize CVaR. By adjusting the mixing weight between these two policies, the agent can effectively explore the environment while still optimizing for the risk-sensitive CVaR objective.
The authors develop an algorithm to jointly optimize the mixing weight and the two underlying policies. They demonstrate the effectiveness of their approach on several benchmark tasks, including robotic control and financial portfolio optimization. The results show that their mixture policy parameterization can significantly improve sample efficiency compared to existing risk-averse reinforcement learning methods.
Critical Analysis
The paper presents a novel and promising approach to improving the sample efficiency of risk-sensitive reinforcement learning. The mixture policy parameterization is a simple yet effective way to balance exploration and risk-averse optimization, which is a key challenge in this domain.
One potential limitation of the approach is that the mixing weight between the risk-neutral and risk-averse policies is a hyperparameter that needs to be tuned. The authors mention that this could be challenging in some environments, and it would be valuable to explore methods for automatically adjusting the mixing weight during the learning process.
Additionally, the paper focuses on the CVaR objective, but there may be other risk-sensitive objectives (e.g., minimax regret) that could also benefit from this mixture policy parameterization. Investigating the generalizability of the approach to other risk-sensitive settings would be an interesting direction for future research.
Conclusion
This paper presents a simple yet effective mixture policy parameterization to improve the sample efficiency of risk-sensitive reinforcement learning. By combining a risk-neutral policy and a risk-averse policy, the agent can effectively explore the environment while still optimizing for a risk-sensitive objective like Conditional Value-at-Risk.
The authors demonstrate the effectiveness of their approach on several benchmark tasks, showing significant performance improvements over existing risk-averse reinforcement learning algorithms. This work represents an important step forward in developing more efficient and practical risk-sensitive reinforcement learning methods, which have the potential to unlock new applications in areas like robotics, finance, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
➖
Variance Reduction based Experience Replay for Policy Optimization
Hua Zheng, Wei Xie, M. Ben Feng
0
0
For reinforcement learning on complex stochastic systems, it is desirable to effectively leverage the information from historical samples collected in previous iterations to accelerate policy optimization. Classical experience replay, while effective, treats all observations uniformly, neglecting their relative importance. To address this limitation, we introduce a novel Variance Reduction Experience Replay (VRER) framework, enabling the selective reuse of relevant samples to improve policy gradient estimation. VRER, as an adaptable method that can seamlessly integrate with different policy optimization algorithms, forms the foundation of our sample efficient off-policy learning algorithm known as Policy Gradient with VRER (PG-VRER). Furthermore, the lack of a rigorous understanding of the experience replay approach in the literature motivates us to introduce a novel theoretical framework that accounts for sample dependencies induced by Markovian noise and behavior policy interdependencies. This framework is then employed to analyze the finite-time convergence of the proposed PG-VRER algorithm, revealing a crucial bias-variance trade-off in policy gradient estimation: the reuse of older experience tends to introduce a larger bias while simultaneously reducing gradient estimation variance. Extensive experiments have shown that VRER offers a notable and consistent acceleration in learning optimal policies and enhances the performance of state-of-the-art (SOTA) policy optimization approaches.
4/16/2024
Robust Risk-Sensitive Reinforcement Learning with Conditional Value-at-Risk
Xinyi Ni, Lifeng Lai
0
0
Robust Markov Decision Processes (RMDPs) have received significant research interest, offering an alternative to standard Markov Decision Processes (MDPs) that often assume fixed transition probabilities. RMDPs address this by optimizing for the worst-case scenarios within ambiguity sets. While earlier studies on RMDPs have largely centered on risk-neutral reinforcement learning (RL), with the goal of minimizing expected total discounted costs, in this paper, we analyze the robustness of CVaR-based risk-sensitive RL under RMDP. Firstly, we consider predetermined ambiguity sets. Based on the coherency of CVaR, we establish a connection between robustness and risk sensitivity, thus, techniques in risk-sensitive RL can be adopted to solve the proposed problem. Furthermore, motivated by the existence of decision-dependent uncertainty in real-world problems, we study problems with state-action-dependent ambiguity sets. To solve this, we define a new risk measure named NCVaR and build the equivalence of NCVaR optimization and robust CVaR optimization. We further propose value iteration algorithms and validate our approach in simulation experiments.
5/6/2024
🤿
Risk-averse Learning with Non-Stationary Distributions
Siyi Wang, Zifan Wang, Xinlei Yi, Michael M. Zavlanos, Karl H. Johansson, Sandra Hirche
0
0
Considering non-stationary environments in online optimization enables decision-maker to effectively adapt to changes and improve its performance over time. In such cases, it is favorable to adopt a strategy that minimizes the negative impact of change to avoid potentially risky situations. In this paper, we investigate risk-averse online optimization where the distribution of the random cost changes over time. We minimize risk-averse objective function using the Conditional Value at Risk (CVaR) as risk measure. Due to the difficulty in obtaining the exact CVaR gradient, we employ a zeroth-order optimization approach that queries the cost function values multiple times at each iteration and estimates the CVaR gradient using the sampled values. To facilitate the regret analysis, we use a variation metric based on Wasserstein distance to capture time-varying distributions. Given that the distribution variation is sub-linear in the total number of episodes, we show that our designed learning algorithm achieves sub-linear dynamic regret with high probability for both convex and strongly convex functions. Moreover, theoretical results suggest that increasing the number of samples leads to a reduction in the dynamic regret bounds until the sampling number reaches a specific limit. Finally, we provide numerical experiments of dynamic pricing in a parking lot to illustrate the efficacy of the designed algorithm.
4/5/2024

Catastrophic-risk-aware reinforcement learning with extreme-value-theory-based policy gradients
Parisa Davar, Fr'ed'eric Godin, Jose Garrido
0
0
This paper tackles the problem of mitigating catastrophic risk (which is risk with very low frequency but very high severity) in the context of a sequential decision making process. This problem is particularly challenging due to the scarcity of observations in the far tail of the distribution of cumulative costs (negative rewards). A policy gradient algorithm is developed, that we call POTPG. It is based on approximations of the tail risk derived from extreme value theory. Numerical experiments highlight the out-performance of our method over common benchmarks, relying on the empirical distribution. An application to financial risk management, more precisely to the dynamic hedging of a financial option, is presented.
7/1/2024