MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild

0

Sign in to get full access
Overview
- This paper presents a new method called "MultiPly" for reconstructing 3D models of multiple people from a single video feed captured in an uncontrolled environment.
- The approach leverages deep learning to jointly estimate the 3D poses, body shapes, and camera parameters of each individual in the video, without requiring any special camera setup or body markers.
- The method is designed to handle challenging real-world scenarios with multiple interacting people, occlusions, and background clutter.
Plain English Explanation
The researchers developed a new AI system called "MultiPly" that can take a regular video of multiple people and create 3D models of each person's body and movement. This is useful for applications like animation, virtual reality, and sports analysis, where having detailed 3D models of people in a scene is important.
Unlike previous methods that required special cameras or markers on the people being filmed, MultiPly can work with just a single regular video camera. It uses advanced deep learning algorithms to analyze the video and figure out the 3D poses, body shapes, and camera position of each person, even when there are occlusions (things blocking the view) or lots of activity in the background.
This makes it much easier and cheaper to capture high-quality 3D models of people in real-world environments, without needing specialized equipment. The researchers tested MultiPly on a variety of challenging videos and showed that it can accurately reconstruct multiple interacting people in chaotic scenes.
Technical Explanation
The MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild paper introduces a new deep learning-based approach for 3D reconstruction of multiple people from a single video feed. Unlike prior methods that focused on either single-person 3D pose estimation or multi-person 2D pose detection, this work jointly tackles the problems of 3D pose, shape, and camera parameter estimation for all people in the scene.
The key innovation is a novel neural network architecture that combines bottom-up and top-down processing to efficiently infer the 3D information of multiple individuals. The bottom-up pathway first detects 2D keypoints for each person, while the top-down pathway uses these 2D detections to estimate the 3D pose, shape, and camera parameters for each person. By iterating between these two pathways, the model is able to progressively refine the 3D reconstructions even in the presence of occlusions and background clutter.
The authors also introduce several training strategies, such as weakly-supervised learning and cross-view consistency, to improve the robustness and generalization of the model. Extensive experiments on challenging in-the-wild datasets like PoseTrack and 3DPW demonstrate the effectiveness of MultiPly compared to prior state-of-the-art methods for multi-person 3D reconstruction.
Critical Analysis
One key limitation of the MultiPly approach is that it requires a video input, rather than being able to reconstruct 3D models from a single image. This may limit its applicability in certain scenarios where only static images are available.
Additionally, while the method can handle occlusions and background clutter to some extent, very extreme cases with significant self-occlusion or heavy occlusion from other objects may still pose challenges. The authors acknowledge this and suggest further research to improve the robustness in such scenarios.
Another area for potential improvement is the computational efficiency of the model. The iterative bottom-up/top-down processing can be computationally intensive, which may limit its real-time applications. Exploring more efficient network architectures or inference techniques could help address this.
Overall, the MultiPly method represents an important step forward in the field of 3D reconstruction of interacting multi-person clothing and coherent 3D portrait video reconstruction. Its ability to handle challenging in-the-wild scenarios makes it a promising tool for a variety of applications.
Conclusion
The MultiPly method proposed in this paper offers a powerful new approach for reconstructing 3D models of multiple people from a single monocular video feed. By jointly estimating the 3D poses, body shapes, and camera parameters of each individual, the method can handle complex real-world scenes with occlusions and background clutter.
This advance in multi-person 3D pose estimation from unlabelled data has important implications for applications such as animation, virtual reality, and sports analysis, where detailed 3D models of people's movements are crucial. While the method has some limitations, the researchers have demonstrated its effectiveness on challenging benchmarks, paving the way for further improvements and wider adoption of this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Zeren Jiang, Chen Guo, Manuel Kaufmann, Tianjian Jiang, Julien Valentin, Otmar Hilliges, Jie Song
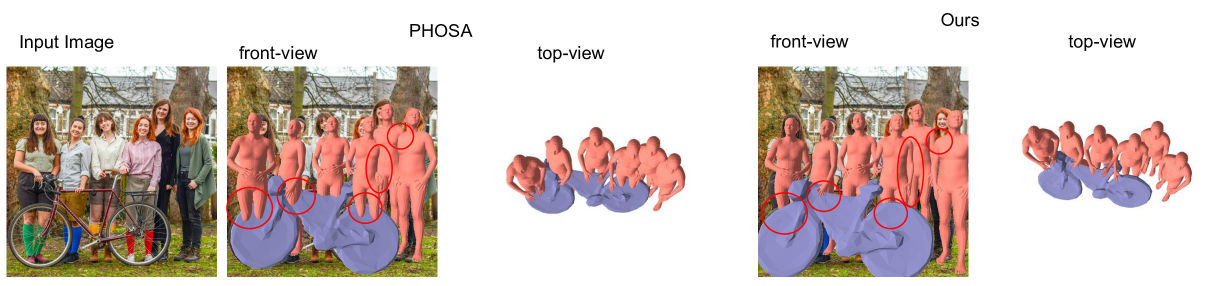
We present MultiPly, a novel framework to reconstruct multiple people in 3D from monocular in-the-wild videos. Reconstructing multiple individuals moving and interacting naturally from monocular in-the-wild videos poses a challenging task. Addressing it necessitates precise pixel-level disentanglement of individuals without any prior knowledge about the subjects. Moreover, it requires recovering intricate and complete 3D human shapes from short video sequences, intensifying the level of difficulty. To tackle these challenges, we first define a layered neural representation for the entire scene, composited by individual human and background models. We learn the layered neural representation from videos via our layer-wise differentiable volume rendering. This learning process is further enhanced by our hybrid instance segmentation approach which combines the self-supervised 3D segmentation and the promptable 2D segmentation module, yielding reliable instance segmentation supervision even under close human interaction. A confidence-guided optimization formulation is introduced to optimize the human poses and shape/appearance alternately. We incorporate effective objectives to refine human poses via photometric information and impose physically plausible constraints on human dynamics, leading to temporally consistent 3D reconstructions with high fidelity. The evaluation of our method shows the superiority over prior art on publicly available datasets and in-the-wild videos.
Read more6/4/2024
0
Single-image coherent reconstruction of objects and humans
Sarthak Batra, Partha P. Chakrabarti, Simon Hadfield, Armin Mustafa
Existing methods for reconstructing objects and humans from a monocular image suffer from severe mesh collisions and performance limitations for interacting occluding objects. This paper introduces a method to obtain a globally consistent 3D reconstruction of interacting objects and people from a single image. Our contributions include: 1) an optimization framework, featuring a collision loss, tailored to handle human-object and human-human interactions, ensuring spatially coherent scene reconstruction; and 2) a novel technique to robustly estimate 6 degrees of freedom (DOF) poses, specifically for heavily occluded objects, exploiting image inpainting. Notably, our proposed method operates effectively on images from real-world scenarios, without necessitating scene or object-level 3D supervision. Extensive qualitative and quantitative evaluation against existing methods demonstrates a significant reduction in collisions in the final reconstructions of scenes with multiple interacting humans and objects and a more coherent scene reconstruction.
Read more8/16/2024
📊
0
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Read more4/10/2024

0
MultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Nicolas Ugrinovic, Boxiao Pan, Georgios Pavlakos, Despoina Paschalidou, Bokui Shen, Jordi Sanchez-Riera, Francesc Moreno-Noguer, Leonidas Guibas
We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
Read more4/19/2024