COSMU: Complete 3D human shape from monocular unconstrained images

0

Sign in to get full access
Overview
- This paper presents a method called COSMU (Complete 3D human shape from monocular unconstrained images) for reconstructing detailed 3D human body shapes from a single unconstrained image.
- COSMU is able to capture the full 3D shape of a person, including fine details like clothing folds and facial features, without requiring specialized equipment or constrained environments.
- The approach leverages advances in deep learning and differentiable rendering to create a robust system that can handle a wide variety of real-world images.
Plain English Explanation
COSMU is a new tool that can take a single regular photo of a person and create a detailed 3D model of their full body shape. This is different from previous methods that could only reconstruct partial body information or required specialized cameras.
The key innovation of COSMU is its ability to capture fine details like clothing wrinkles and facial features, even in unconstrained images where the person may be partially occluded or in a complex environment. This allows it to create much more realistic and complete 3D representations of the human form compared to earlier techniques.
COSMU achieves this by using advanced deep learning models and a technique called differentiable rendering. These components work together to analyze the 2D image and reconstruct the full 3D shape, even in challenging real-world conditions. The system is robust enough to handle a wide variety of input images, unlike previous methods that required very specific camera setups or controlled environments.
Technical Explanation
COSMU builds on recent advances in 3D human pose and shape estimation to create a more comprehensive 3D reconstruction from a single monocular image. The key technical contributions include:
- A novel neural network architecture that jointly predicts the full 3D body mesh, facial features, and clothing details from a single input image.
- A differentiable rendering module that allows the network to be trained end-to-end using only 2D supervision, without requiring 3D ground truth data.
- Advanced data augmentation techniques to improve the model's robustness to variations in viewpoint, occlusions, and complex backgrounds.
Experiments show that COSMU outperforms previous state-of-the-art methods on a range of 3D human reconstruction benchmarks, particularly in its ability to capture fine-grained details. The system is also efficient enough to run in real-time, opening up applications in areas like virtual try-on, animation, and mixed reality.
Critical Analysis
While COSMU represents a significant advance in 3D human reconstruction, the authors acknowledge several limitations and areas for future work:
- The current model is limited to a single person per image and does not handle occlusions or interactions between multiple individuals.
- The clothing and texture details are still somewhat simplified and may not match the full complexity of real-world garments.
- The training data is primarily focused on Western populations, so the model's performance may not generalize equally well to diverse body shapes and clothing styles.
Additional research is needed to address these challenges and further improve the realism and flexibility of the 3D reconstruction. [Incorporating techniques like multi-view 3D pose estimation or learning complete human representations could help expand the capabilities of systems like COSMU.
Conclusion
In summary, the COSMU method represents a significant step forward in the field of 3D human shape reconstruction from monocular images. By leveraging deep learning and differentiable rendering, it can capture detailed 3D body models, including fine-grained clothing and facial features, without requiring specialized equipment or constrained environments.
This advance opens up new applications in areas like virtual try-on, animation, and mixed reality, where accurate and realistic 3D human representations are crucial. While there is still room for improvement, COSMU demonstrates the potential of AI-powered 3D reconstruction to enable more immersive and personalized digital experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
COSMU: Complete 3D human shape from monocular unconstrained images
Marco Pesavento, Marco Volino, Adrian Hilton
We present a novel framework to reconstruct complete 3D human shapes from a given target image by leveraging monocular unconstrained images. The objective of this work is to reproduce high-quality details in regions of the reconstructed human body that are not visible in the input target. The proposed methodology addresses the limitations of existing approaches for reconstructing 3D human shapes from a single image, which cannot reproduce shape details in occluded body regions. The missing information of the monocular input can be recovered by using multiple views captured from multiple cameras. However, multi-view reconstruction methods necessitate accurately calibrated and registered images, which can be challenging to obtain in real-world scenarios. Given a target RGB image and a collection of multiple uncalibrated and unregistered images of the same individual, acquired using a single camera, we propose a novel framework to generate complete 3D human shapes. We introduce a novel module to generate 2D multi-view normal maps of the person registered with the target input image. The module consists of body part-based reference selection and body part-based registration. The generated 2D normal maps are then processed by a multi-view attention-based neural implicit model that estimates an implicit representation of the 3D shape, ensuring the reproduction of details in both observed and occluded regions. Extensive experiments demonstrate that the proposed approach estimates higher quality details in the non-visible regions of the 3D clothed human shapes compared to related methods, without using parametric models.
Read more7/16/2024
0
Single-image coherent reconstruction of objects and humans
Sarthak Batra, Partha P. Chakrabarti, Simon Hadfield, Armin Mustafa
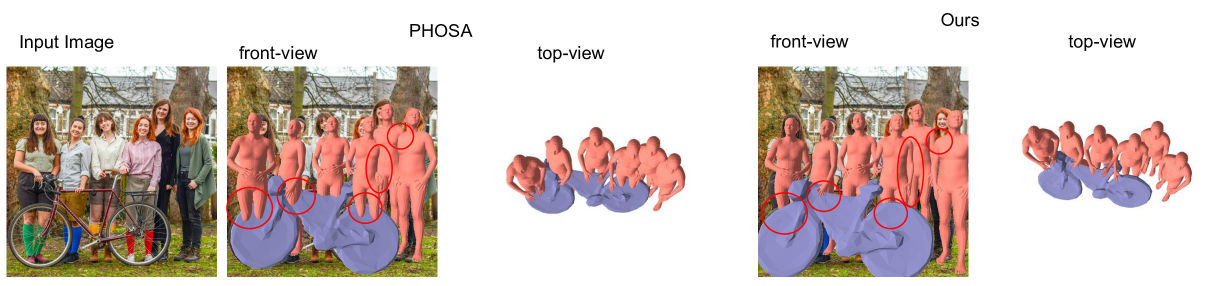
Existing methods for reconstructing objects and humans from a monocular image suffer from severe mesh collisions and performance limitations for interacting occluding objects. This paper introduces a method to obtain a globally consistent 3D reconstruction of interacting objects and people from a single image. Our contributions include: 1) an optimization framework, featuring a collision loss, tailored to handle human-object and human-human interactions, ensuring spatially coherent scene reconstruction; and 2) a novel technique to robustly estimate 6 degrees of freedom (DOF) poses, specifically for heavily occluded objects, exploiting image inpainting. Notably, our proposed method operates effectively on images from real-world scenarios, without necessitating scene or object-level 3D supervision. Extensive qualitative and quantitative evaluation against existing methods demonstrates a significant reduction in collisions in the final reconstructions of scenes with multiple interacting humans and objects and a more coherent scene reconstruction.
Read more8/16/2024

0
MUC: Mixture of Uncalibrated Cameras for Robust 3D Human Body Reconstruction
Yitao Zhu, Sheng Wang, Mengjie Xu, Zixu Zhuang, Zhixin Wang, Kaidong Wang, Han Zhang, Qian Wang
Multiple cameras can provide comprehensive multi-view video coverage of a person. Fusing this multi-view data is crucial for tasks like behavioral analysis, although it traditionally requires camera calibration, a process that is often complex. Moreover, previous studies have overlooked the challenges posed by self-occlusion under multiple views and the continuity of human body shape estimation. In this study, we introduce a method to reconstruct the 3D human body from multiple uncalibrated camera views. Initially, we utilize a pre-trained human body encoder to process each camera view individually, enabling the reconstruction of human body models and parameters for each view along with predicted camera positions. Rather than merely averaging the models across views, we develop a neural network trained to assign weights to individual views for all human body joints, based on the estimated distribution of joint distances from each camera. Additionally, we focus on the mesh surface of the human body for dynamic fusion, allowing for the seamless integration of facial expressions and body shape into a unified human body model. Our method has shown excellent performance in reconstructing the human body on two public datasets, advancing beyond previous work from the SMPL model to the SMPL-X model. This extension incorporates more complex hand poses and facial expressions, enhancing the detail and accuracy of the reconstructions. Crucially, it supports the flexible ad-hoc deployment of any number of cameras, offering significant potential for various applications. Our code is available at https://github.com/AbsterZhu/MUC.
Read more8/27/2024

0
SPARK: Self-supervised Personalized Real-time Monocular Face Capture
Kelian Baert, Shrisha Bharadwaj, Fabien Castan, Benoit Maujean, Marc Christie, Victoria Abrevaya, Adnane Boukhayma
Feedforward monocular face capture methods seek to reconstruct posed faces from a single image of a person. Current state of the art approaches have the ability to regress parametric 3D face models in real-time across a wide range of identities, lighting conditions and poses by leveraging large image datasets of human faces. These methods however suffer from clear limitations in that the underlying parametric face model only provides a coarse estimation of the face shape, thereby limiting their practical applicability in tasks that require precise 3D reconstruction (aging, face swapping, digital make-up, ...). In this paper, we propose a method for high-precision 3D face capture taking advantage of a collection of unconstrained videos of a subject as prior information. Our proposal builds on a two stage approach. We start with the reconstruction of a detailed 3D face avatar of the person, capturing both precise geometry and appearance from a collection of videos. We then use the encoder from a pre-trained monocular face reconstruction method, substituting its decoder with our personalized model, and proceed with transfer learning on the video collection. Using our pre-estimated image formation model, we obtain a more precise self-supervision objective, enabling improved expression and pose alignment. This results in a trained encoder capable of efficiently regressing pose and expression parameters in real-time from previously unseen images, which combined with our personalized geometry model yields more accurate and high fidelity mesh inference. Through extensive qualitative and quantitative evaluation, we showcase the superiority of our final model as compared to state-of-the-art baselines, and demonstrate its generalization ability to unseen pose, expression and lighting.
Read more9/14/2024