SIP: Injecting a Structural Inductive Bias into a Seq2Seq Model by Simulation

0

Sign in to get full access
Overview
- This paper explores a method for injecting a structural inductive bias into a sequence-to-sequence (seq2seq) model by simulating the desired structure during training.
- The authors propose a training approach that encourages the model to learn a specific structural pattern, which can potentially improve its systematic generalization capabilities.
- The technique involves generating synthetic data with the desired structure and using it alongside the original training data to fine-tune the seq2seq model.
- The authors evaluate their approach on a language modeling task and a machine translation task, demonstrating improved performance compared to standard seq2seq models.
Plain English Explanation
In machine learning, models can sometimes struggle to generalize their understanding beyond the specific patterns they were trained on. This is known as the problem of systematic generalization.
To address this, the authors of this paper propose a novel training approach that can help a seq2seq model learn a specific structural pattern. The key idea is to generate synthetic data that exhibits the desired structure and use it to fine-tune the model, alongside the original training data.
For example, imagine you're training a machine translation model to translate between English and French. The authors suggest that you could create additional training examples that follow a specific grammatical structure, like subject-verb-object. By exposing the model to these structured examples during training, you can help it learn to recognize and generate that pattern more effectively.
The authors evaluate their technique on two tasks: language modeling and machine translation. They find that the models trained with their approach demonstrate improved performance compared to standard seq2seq models, suggesting that this method can be a useful way to inject a structural inductive bias into seq2seq models.
Technical Explanation
The authors propose a training approach that involves generating synthetic data with a specific structural pattern and using it to fine-tune a seq2seq model. This can be seen as a way to inject a structural inductive bias into the model, potentially improving its systematic generalization capabilities.
The training process consists of two main steps:
-
Synthetic Data Generation: The authors create a synthetic dataset that exhibits the desired structural pattern. This is done by defining a generative process that produces sequences with the target structure.
-
Fine-tuning: The authors fine-tune the seq2seq model using a combination of the original training data and the synthetic data generated in the previous step. This encourages the model to learn the target structural pattern.
The authors evaluate their approach on two tasks:
-
Language Modeling: The authors train a seq2seq model to generate natural language sequences and compare the performance of models trained with and without the synthetic data.
-
Machine Translation: The authors train a seq2seq model for machine translation and again compare the performance of models trained with and without the synthetic data.
The results show that the models trained with the proposed approach outperform the standard seq2seq models on both tasks, suggesting that this method can be an effective way to strengthen the structural inductive biases of seq2seq models.
Critical Analysis
The authors provide a clear and well-designed approach for injecting a structural inductive bias into seq2seq models. However, there are a few potential limitations and areas for further research:
-
Generalization to More Complex Structures: The authors focus on relatively simple structural patterns in their experiments. It would be interesting to see how well this approach scales to more complex structural biases, such as those found in natural language or other domains.
-
Sensitivity to Synthetic Data Quality: The performance of the proposed approach may be sensitive to the quality and realism of the synthetic data generated. More work is needed to understand how the characteristics of the synthetic data impact the model's learning and generalization.
-
Computational Overhead: The additional step of generating synthetic data and fine-tuning the model may increase the computational cost of the training process. The authors should consider the tradeoffs between the performance gains and the computational resources required.
-
Interpretability: While the authors demonstrate the effectiveness of their approach, it would be valuable to gain a deeper understanding of how the injected structural bias is manifested in the model's representations and decision-making processes. Transformer-powered surrogates could be a useful tool for this analysis.
Overall, this paper presents an interesting and promising approach for improving the systematic generalization capabilities of seq2seq models. Further research on the practical implications and limitations of this technique would be valuable for advancing the field of learning transductions and alignments in seq2seq models.
Conclusion
This paper introduces a novel training approach that aims to inject a structural inductive bias into seq2seq models by simulating the desired structure during the training process. The authors demonstrate the effectiveness of their technique on language modeling and machine translation tasks, showing improved performance compared to standard seq2seq models.
The key contribution of this work is the idea of leveraging synthetic data with a specific structural pattern to fine-tune seq2seq models, which can help them learn and generalize the target structure more effectively. This approach has the potential to be a useful tool for improving the systematic generalization capabilities of seq2seq models in a variety of applications.
While the authors provide a solid foundation, there are still opportunities for further research to address the limitations and explore the broader implications of this technique. Continued advancements in this area could lead to more robust and adaptable seq2seq models that can better handle the complexities of real-world data and tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SIP: Injecting a Structural Inductive Bias into a Seq2Seq Model by Simulation
Matthias Lindemann, Alexander Koller, Ivan Titov
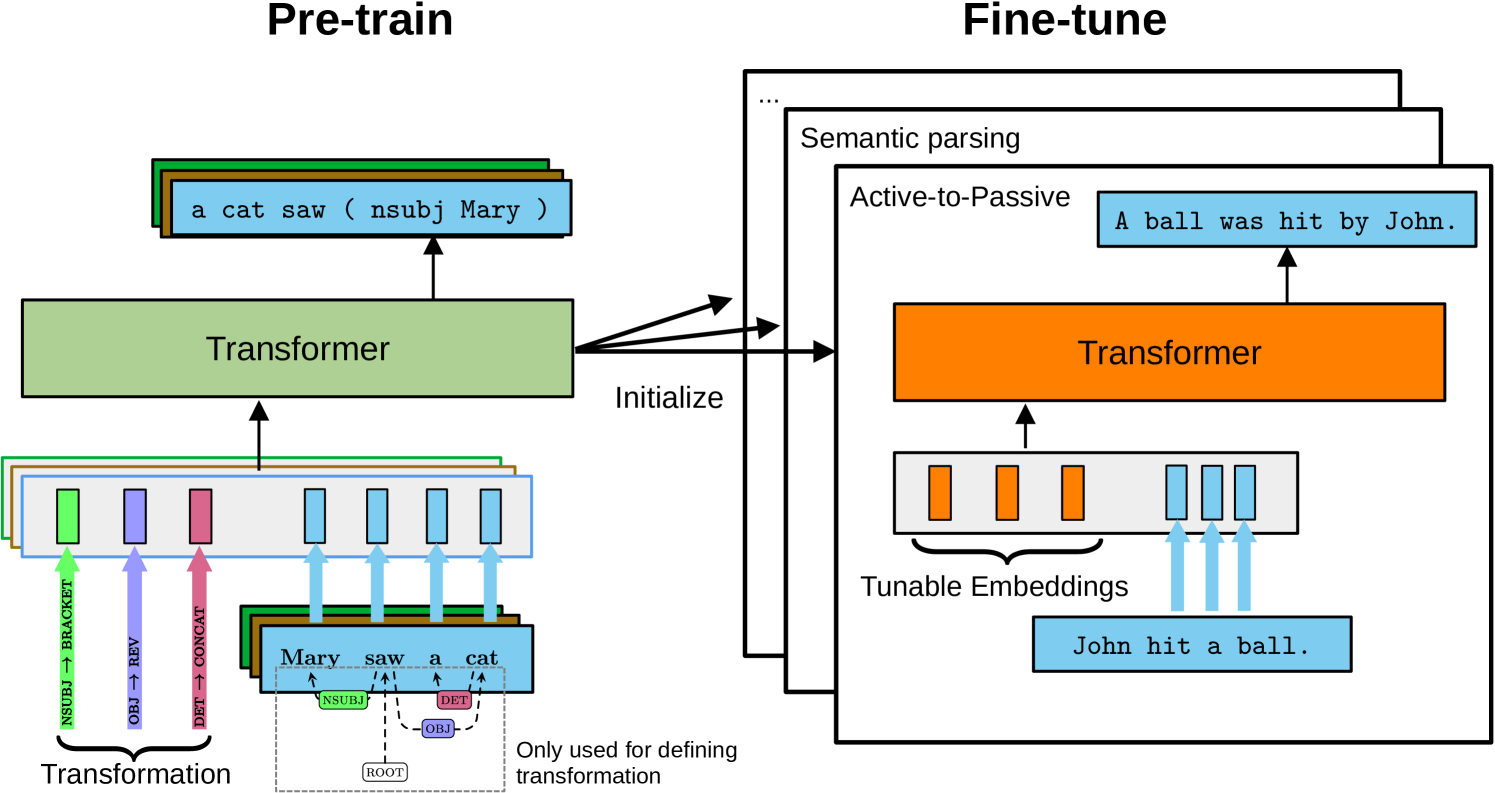
Strong inductive biases enable learning from little data and help generalization outside of the training distribution. Popular neural architectures such as Transformers lack strong structural inductive biases for seq2seq NLP tasks on their own. Consequently, they struggle with systematic generalization beyond the training distribution, e.g. with extrapolating to longer inputs, even when pre-trained on large amounts of text. We show how a structural inductive bias can be efficiently injected into a seq2seq model by pre-training it to simulate structural transformations on synthetic data. Specifically, we inject an inductive bias towards Finite State Transducers (FSTs) into a Transformer by pre-training it to simulate FSTs given their descriptions. Our experiments show that our method imparts the desired inductive bias, resulting in improved systematic generalization and better few-shot learning for FST-like tasks. Our analysis shows that fine-tuned models accurately capture the state dynamics of the unseen underlying FSTs, suggesting that the simulation process is internalized by the fine-tuned model.
Read more7/11/2024
0
Strengthening Structural Inductive Biases by Pre-training to Perform Syntactic Transformations
Matthias Lindemann, Alexander Koller, Ivan Titov
Models need appropriate inductive biases to effectively learn from small amounts of data and generalize systematically outside of the training distribution. While Transformers are highly versatile and powerful, they can still benefit from enhanced structural inductive biases for seq2seq tasks, especially those involving syntactic transformations, such as converting active to passive voice or semantic parsing. In this paper, we propose to strengthen the structural inductive bias of a Transformer by intermediate pre-training to perform synthetically generated syntactic transformations of dependency trees given a description of the transformation. Our experiments confirm that this helps with few-shot learning of syntactic tasks such as chunking, and also improves structural generalization for semantic parsing. Our analysis shows that the intermediate pre-training leads to attention heads that keep track of which syntactic transformation needs to be applied to which token, and that the model can leverage these attention heads on downstream tasks.
Read more7/8/2024
🔮
0
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
Ido Amos, Jonathan Berant, Ankit Gupta
Modeling long-range dependencies across sequences is a longstanding goal in machine learning and has led to architectures, such as state space models, that dramatically outperform Transformers on long sequences. However, these impressive empirical gains have been by and large demonstrated on benchmarks (e.g. Long Range Arena), where models are randomly initialized and trained to predict a target label from an input sequence. In this work, we show that random initialization leads to gross overestimation of the differences between architectures and that pretraining with standard denoising objectives, using $textit{only the downstream task data}$, leads to dramatic gains across multiple architectures and to very small gaps between Transformers and state space models (SSMs). In stark contrast to prior works, we find vanilla Transformers to match the performance of S4 on Long Range Arena when properly pretrained, and we improve the best reported results of SSMs on the PathX-256 task by 20 absolute points. Subsequently, we analyze the utility of previously-proposed structured parameterizations for SSMs and show they become mostly redundant in the presence of data-driven initialization obtained through pretraining. Our work shows that, when evaluating different architectures on supervised tasks, incorporation of data-driven priors via pretraining is essential for reliable performance estimation, and can be done efficiently.
Read more4/30/2024
🤔
0
Towards Understanding Inductive Bias in Transformers: A View From Infinity
Itay Lavie, Guy Gur-Ari, Zohar Ringel
We study inductive bias in Transformers in the infinitely over-parameterized Gaussian process limit and argue transformers tend to be biased towards more permutation symmetric functions in sequence space. We show that the representation theory of the symmetric group can be used to give quantitative analytical predictions when the dataset is symmetric to permutations between tokens. We present a simplified transformer block and solve the model at the limit, including accurate predictions for the learning curves and network outputs. We show that in common setups, one can derive tight bounds in the form of a scaling law for the learnability as a function of the context length. Finally, we argue WikiText dataset, does indeed possess a degree of permutation symmetry.
Read more5/29/2024