SLTrain: a sparse plus low-rank approach for parameter and memory efficient pretraining

0

Sign in to get full access
Overview
- Introduces a new approach called SLTrain for efficient pretraining of large language models
- SLTrain combines a sparse neural network with a low-rank decomposition to reduce the number of parameters and memory footprint
- Aims to enable high-sparsity in foundational language models like LLAMA for efficient training and deployment
Plain English Explanation
SLTrain is a new technique for training large language models more efficiently. It combines two key ideas: sparsity and low-rank decomposition. Sparsity means using a neural network where most of the connections between neurons are removed, leaving only the most important ones. This reduces the number of parameters (or "weights") in the model, making it smaller and faster. Low-rank decomposition is a way to further compress the model by representing the remaining weights as the product of two smaller matrices.
By using both sparsity and low-rank decomposition, SLTrain can create highly efficient language models that use far fewer parameters and memory than traditional approaches. This could enable the development of high-sparsity foundational models that are faster and cheaper to train and run, opening up new possibilities for large language models in real-world applications.
The key innovation of SLTrain is how it combines sparsity and low-rank techniques in a novel way, building on ideas from previous work like SLOPE and LOQT. By carefully balancing these two complementary approaches, SLTrain can achieve significant efficiency gains without sacrificing model performance.
Technical Explanation
The SLTrain approach starts by initializing the model weights in a sparse configuration, with most weights set to zero. During training, a sparse plus low-rank decomposition is applied to the weights, where the non-zero weights are factorized into the product of two lower-rank matrices. This has the effect of further reducing the number of parameters required to represent the model.
Specifically, the sparse plus low-rank decomposition can be expressed as:
W = S + L
Where W is the original weight matrix, S is a sparse matrix, and L is a low-rank matrix. The sparsity of S and the rank of L are hyperparameters that can be tuned to balance parameter efficiency and model performance.
The key technical innovation of SLTrain is the training algorithm, which alternates between updating the sparse matrix S and the low-rank matrix L. This allows the model to learn an optimal sparse plus low-rank representation during pretraining, leading to significant reductions in parameter count and memory usage compared to a dense baseline.
The authors evaluate SLTrain on a variety of language modeling benchmarks, including pretraining on the C4 corpus and fine-tuning on tasks like GLUE and SuperGLUE. They show that SLTrain can achieve competitive model performance while using 4-8x fewer parameters than a dense baseline.
Critical Analysis
The SLTrain paper makes a compelling case for the benefits of combining sparsity and low-rank decomposition for efficient language model pretraining. The experimental results demonstrate impressive parameter and memory savings without significant degradation in model performance.
However, the paper does not deeply explore potential limitations or caveats of the approach. For example, it's unclear how the SLTrain technique would scale to truly massive language models, or how it would perform on more specialized tasks beyond general language modeling.
Additionally, the authors do not provide much insight into the specific tradeoffs between sparsity and low-rank rank in their approach. Further analysis of how these two factors influence model efficiency and performance could help researchers better understand the strengths and weaknesses of SLTrain.
Finally, while the paper cites relevant prior work like SLOPE and LOQT, it does not deeply engage with or build upon the ideas presented in those works. A more thorough discussion of how SLTrain relates to and advances the state-of-the-art in efficient language model pretraining could strengthen the paper's overall contribution.
Conclusion
The SLTrain approach represents an important step forward in the quest for more parameter and memory-efficient pretraining of large language models. By cleverly combining sparsity and low-rank decomposition techniques, the authors demonstrate a pathway to creating highly compact models that maintain competitive performance.
This work aligns with broader trends in the field toward enabling high-sparsity in foundational language models and accelerating the training of large language models through novel architectural and algorithmic innovations.
If further developed and refined, SLTrain could help unlock new applications and deployment scenarios for large language models, making them more practical and accessible. This could lead to significant advancements in natural language processing and the broader field of artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SLTrain: a sparse plus low-rank approach for parameter and memory efficient pretraining
Andi Han, Jiaxiang Li, Wei Huang, Mingyi Hong, Akiko Takeda, Pratik Jawanpuria, Bamdev Mishra
Large language models (LLMs) have shown impressive capabilities across various tasks. However, training LLMs from scratch requires significant computational power and extensive memory capacity. Recent studies have explored low-rank structures on weights for efficient fine-tuning in terms of parameters and memory, either through low-rank adaptation or factorization. While effective for fine-tuning, low-rank structures are generally less suitable for pretraining because they restrict parameters to a low-dimensional subspace. In this work, we propose to parameterize the weights as a sum of low-rank and sparse matrices for pretraining, which we call SLTrain. The low-rank component is learned via matrix factorization, while for the sparse component, we employ a simple strategy of uniformly selecting the sparsity support at random and learning only the non-zero entries with the fixed support. While being simple, the random fixed-support sparse learning strategy significantly enhances pretraining when combined with low-rank learning. Our results show that SLTrain adds minimal extra parameters and memory costs compared to pretraining with low-rank parameterization, yet achieves substantially better performance, which is comparable to full-rank training. Remarkably, when combined with quantization and per-layer updates, SLTrain can reduce memory requirements by up to 73% when pretraining the LLaMA 7B model.
Read more6/5/2024
0
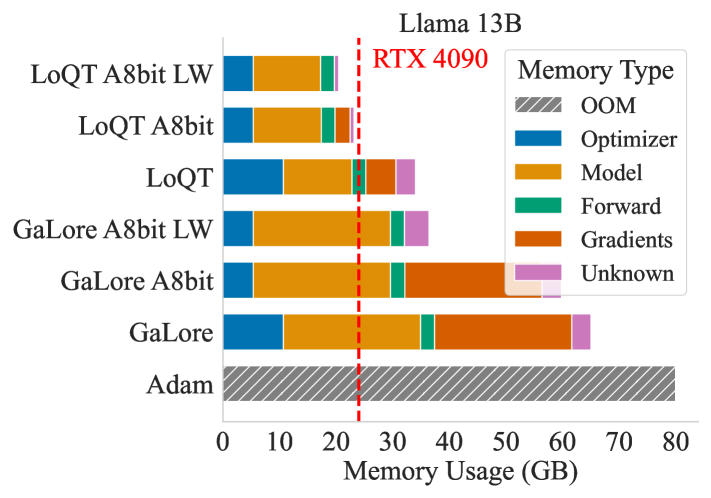
LoQT: Low Rank Adapters for Quantized Training
Sebastian Loeschcke, Mads Toftrup, Michael J. Kastoryano, Serge Belongie, V'esteinn Sn{ae}bjarnarson
Training of large neural networks requires significant computational resources. Despite advances using low-rank adapters and quantization, pretraining of models such as LLMs on consumer hardware has not been possible without model sharding, offloading during training, or per-layer gradient updates. To address these limitations, we propose LoQT, a method for efficiently training quantized models. LoQT uses gradient-based tensor factorization to initialize low-rank trainable weight matrices that are periodically merged into quantized full-rank weight matrices. Our approach is suitable for both pretraining and fine-tuning of models, which we demonstrate experimentally for language modeling and downstream task adaptation. We find that LoQT enables efficient training of models up to 7B parameters on a consumer-grade 24GB GPU. We also demonstrate the feasibility of training a 13B parameter model using per-layer gradient updates on the same hardware.
Read more9/10/2024

0
Sparsity-Accelerated Training for Large Language Models
Da Ma, Lu Chen, Pengyu Wang, Hongshen Xu, Hanqi Li, Liangtai Sun, Su Zhu, Shuai Fan, Kai Yu
Large language models (LLMs) have demonstrated proficiency across various natural language processing (NLP) tasks but often require additional training, such as continual pre-training and supervised fine-tuning. However, the costs associated with this, primarily due to their large parameter count, remain high. This paper proposes leveraging emph{sparsity} in pre-trained LLMs to expedite this training process. By observing sparsity in activated neurons during forward iterations, we identify the potential for computational speed-ups by excluding inactive neurons. We address associated challenges by extending existing neuron importance evaluation metrics and introducing a ladder omission rate scheduler. Our experiments on Llama-2 demonstrate that Sparsity-Accelerated Training (SAT) achieves comparable or superior performance to standard training while significantly accelerating the process. Specifically, SAT achieves a $45%$ throughput improvement in continual pre-training and saves $38%$ training time in supervised fine-tuning in practice. It offers a simple, hardware-agnostic, and easily deployable framework for additional LLM training. Our code is available at https://github.com/OpenDFM/SAT.
Read more6/7/2024

0
SLoPe: Double-Pruned Sparse Plus Lazy Low-Rank Adapter Pretraining of LLMs
Mohammad Mozaffari, Amir Yazdanbakhsh, Zhao Zhang, Maryam Mehri Dehnavi
We propose SLoPe, a Double-Pruned Sparse Plus Lazy Low-rank Adapter Pretraining method for LLMs that improves the accuracy of sparse LLMs while accelerating their pretraining and inference and reducing their memory footprint. Sparse pretraining of LLMs reduces the accuracy of the model, to overcome this, prior work uses dense models during fine-tuning. SLoPe improves the accuracy of sparsely pretrained models by adding low-rank adapters in the final 1% iterations of pretraining without adding significant overheads to the model pretraining and inference. In addition, SLoPe uses a double-pruned backward pass formulation that prunes the transposed weight matrix using N:M sparsity structures to enable an accelerated sparse backward pass. SLoPe accelerates the training and inference of models with billions of parameters up to $1.14times$ and $1.34times$ respectively (OPT-33B and OPT-66B) while reducing their memory usage by up to $0.77times$ and $0.51times$ for training and inference respectively.
Read more6/17/2024