Smart Vision-Language Reasoners

0
Sign in to get full access
Overview
- This paper explores the development of "smart" vision-language reasoners - AI systems that can understand and reason about the world by combining visual and linguistic information.
- The researchers aim to advance the state-of-the-art in multimodal AI, which integrates computer vision and natural language processing capabilities.
- Key focus areas include improving reasoning abilities, strengthening cross-modal understanding, and enhancing knowledge representation for vision-language tasks.
Plain English Explanation
The paper discusses the development of advanced AI systems that can combine visual information (from images or videos) with language understanding. The goal is to create "smart" vision-language reasoners - AI that can comprehend the world in a more holistic, human-like way by integrating visual and textual data.
These systems would go beyond just describing what they see in an image. They would use reasoning and cross-modal learning to develop a deeper understanding of the concepts, relationships, and context represented. This could enable them to answer more complex questions, solve problems, and engage in richer dialogue about the visual world.
The researchers are working to push the boundaries of multimodal AI - technology that brings together computer vision and natural language processing. Key aims include improving the reasoning abilities of these systems, strengthening their cross-modal understanding (how they connect visual and linguistic information), and enhancing their overall knowledge representation for vision-language tasks.
Technical Explanation
The paper reviews the current state-of-the-art in vision-language models and reasoning, and outlines several key research directions to advance this field. This includes:
- Improving reasoning abilities of vision-language models, enabling them to go beyond just describing images to engaging in more complex logical inference and problem-solving.
- Strengthening cross-modal understanding between visual and linguistic representations, allowing for deeper connections and more nuanced comprehension.
- Enhancing knowledge representation to better capture and reason about the concepts, relationships, and contextual information present in vision-language tasks.
The researchers propose novel architectures, training strategies, and evaluation frameworks to drive progress in these areas, drawing on insights from fields like computer vision, natural language processing, and cognitive science.
Critical Analysis
The paper provides a comprehensive overview of the current challenges and research frontiers in vision-language reasoning. However, it does not delve deeply into the specific limitations or potential issues with the proposed approaches.
For example, the paper does not address the sample efficiency or data requirements of the suggested models, which could be a significant practical concern. Additionally, the work does not explore the potential biases or ethical considerations that may arise from these advanced vision-language systems.
Further research and discussion would be needed to fully assess the tradeoffs, risks, and societal implications of deploying these "smart" vision-language reasoners at scale.
Conclusion
This paper outlines an ambitious research agenda for developing more sophisticated vision-language AI systems. By improving reasoning, cross-modal understanding, and knowledge representation, the researchers aim to create "smart" reasoners that can engage with the visual world in a more human-like way.
If successful, these advancements could unlock new applications in areas like multimodal dialogue, visual question answering, and integrated perception-cognition systems. However, careful consideration of the practical, ethical, and societal implications will be crucial as this technology continues to evolve.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Smart Vision-Language Reasoners
Denisa Roberts, Lucas Roberts
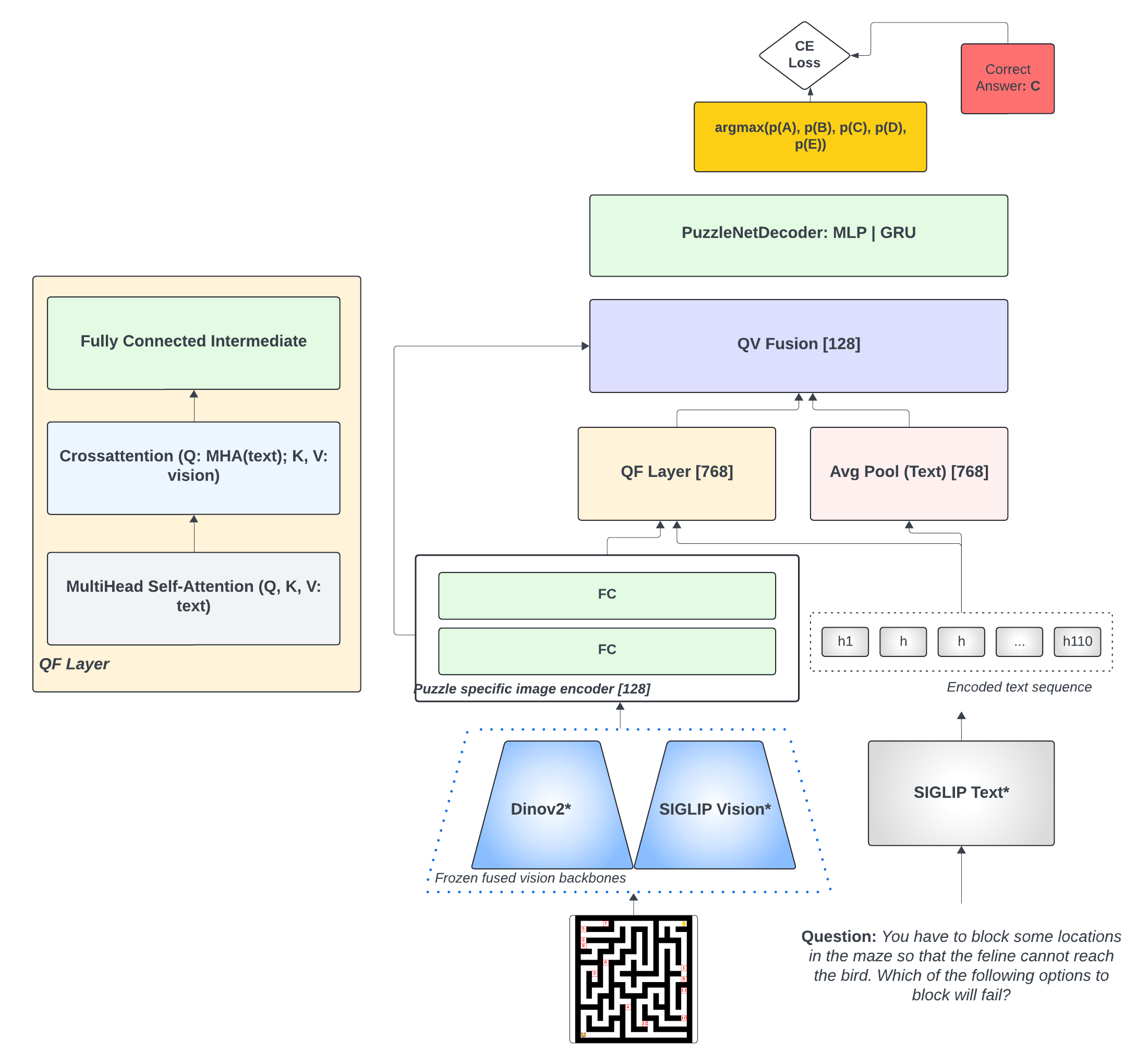
In this article, we investigate vision-language models (VLM) as reasoners. The ability to form abstractions underlies mathematical reasoning, problem-solving, and other Math AI tasks. Several formalisms have been given to these underlying abstractions and skills utilized by humans and intelligent systems for reasoning. Furthermore, human reasoning is inherently multimodal, and as such, we focus our investigations on multimodal AI. In this article, we employ the abstractions given in the SMART task (Simple Multimodal Algorithmic Reasoning Task) introduced in cite{cherian2022deep} as meta-reasoning and problem-solving skills along eight axes: math, counting, path, measure, logic, spatial, and pattern. We investigate the ability of vision-language models to reason along these axes and seek avenues of improvement. Including composite representations with vision-language cross-attention enabled learning multimodal representations adaptively from fused frozen pretrained backbones for better visual grounding. Furthermore, proper hyperparameter and other training choices led to strong improvements (up to $48%$ gain in accuracy) on the SMART task, further underscoring the power of deep multimodal learning. The smartest VLM, which includes a novel QF multimodal layer, improves upon the best previous baselines in every one of the eight fundamental reasoning skills. End-to-end code is available at https://github.com/smarter-vlm/smarter.
Read more7/8/2024

0
Is A Picture Worth A Thousand Words? Delving Into Spatial Reasoning for Vision Language Models
Jiayu Wang, Yifei Ming, Zhenmei Shi, Vibhav Vineet, Xin Wang, Neel Joshi
Large language models (LLMs) and vision-language models (VLMs) have demonstrated remarkable performance across a wide range of tasks and domains. Despite this promise, spatial understanding and reasoning -- a fundamental component of human cognition -- remains under-explored. We develop novel benchmarks that cover diverse aspects of spatial reasoning such as relationship understanding, navigation, and counting. We conduct a comprehensive evaluation of competitive language and vision-language models. Our findings reveal several counter-intuitive insights that have been overlooked in the literature: (1) Spatial reasoning poses significant challenges where competitive models can fall behind random guessing; (2) Despite additional visual input, VLMs often under-perform compared to their LLM counterparts; (3) When both textual and visual information is available, multi-modal language models become less reliant on visual information if sufficient textual clues are provided. Additionally, we demonstrate that leveraging redundancy between vision and text can significantly enhance model performance. We hope our study will inform the development of multimodal models to improve spatial intelligence and further close the gap with human intelligence.
Read more6/24/2024

0
Exploring the Frontier of Vision-Language Models: A Survey of Current Methodologies and Future Directions
Akash Ghosh, Arkadeep Acharya, Sriparna Saha, Vinija Jain, Aman Chadha
The advent of Large Language Models (LLMs) has significantly reshaped the trajectory of the AI revolution. Nevertheless, these LLMs exhibit a notable limitation, as they are primarily adept at processing textual information. To address this constraint, researchers have endeavored to integrate visual capabilities with LLMs, resulting in the emergence of Vision-Language Models (VLMs). These advanced models are instrumental in tackling more intricate tasks such as image captioning and visual question answering. In our comprehensive survey paper, we delve into the key advancements within the realm of VLMs. Our classification organizes VLMs into three distinct categories: models dedicated to vision-language understanding, models that process multimodal inputs to generate unimodal (textual) outputs and models that both accept and produce multimodal inputs and outputs.This classification is based on their respective capabilities and functionalities in processing and generating various modalities of data.We meticulously dissect each model, offering an extensive analysis of its foundational architecture, training data sources, as well as its strengths and limitations wherever possible, providing readers with a comprehensive understanding of its essential components. We also analyzed the performance of VLMs in various benchmark datasets. By doing so, we aim to offer a nuanced understanding of the diverse landscape of VLMs. Additionally, we underscore potential avenues for future research in this dynamic domain, anticipating further breakthroughs and advancements.
Read more4/16/2024

0
Evaluating Large Vision-and-Language Models on Children's Mathematical Olympiads
Anoop Cherian, Kuan-Chuan Peng, Suhas Lohit, Joanna Matthiesen, Kevin Smith, Joshua B. Tenenbaum
Recent years have seen a significant progress in the general-purpose problem solving abilities of large vision and language models (LVLMs), such as ChatGPT, Gemini, etc.; some of these breakthroughs even seem to enable AI models to outperform human abilities in varied tasks that demand higher-order cognitive skills. Are the current large AI models indeed capable of generalized problem solving as humans do? A systematic analysis of AI capabilities for joint vision and text reasoning, however, is missing in the current scientific literature. In this paper, we make an effort towards filling this gap, by evaluating state-of-the-art LVLMs on their mathematical and algorithmic reasoning abilities using visuo-linguistic problems from children's Olympiads. Specifically, we consider problems from the Mathematical Kangaroo (MK) Olympiad, which is a popular international competition targeted at children from grades 1-12, that tests children's deeper mathematical abilities using puzzles that are appropriately gauged to their age and skills. Using the puzzles from MK, we created a dataset, dubbed SMART-840, consisting of 840 problems from years 2020-2024. With our dataset, we analyze LVLMs power on mathematical reasoning; their responses on our puzzles offer a direct way to compare against that of children. Our results show that modern LVLMs do demonstrate increasingly powerful reasoning skills in solving problems for higher grades, but lack the foundations to correctly answer problems designed for younger children. Further analysis shows that there is no significant correlation between the reasoning capabilities of AI models and that of young children, and their capabilities appear to be based on a different type of reasoning than the cumulative knowledge that underlies children's mathematics and logic skills.
Read more6/26/2024