SoftTiger: A Clinical Foundation Model for Healthcare Workflows

1

Sign in to get full access
Overview
- This paper introduces SoftTiger, a clinical foundation model for healthcare workflows.
- It addresses the problem of limited availability of high-quality clinical data and models for specific medical tasks.
- SoftTiger aims to provide a versatile foundation model that can be fine-tuned for various healthcare-related tasks.
Plain English Explanation
The paper presents SoftTiger, a new type of machine learning model designed specifically for healthcare applications. The key idea behind SoftTiger is to create a versatile "foundation" model that can be easily adapted to tackle a wide range of clinical tasks, rather than building separate models for each specific task.
This is an important problem to address because the development of high-quality clinical models is often hindered by the limited availability of large, labeled datasets for training. By starting with a pre-trained foundation model and then fine-tuning it on smaller, domain-specific datasets, the researchers hope to create models that can perform well on a variety of healthcare-related tasks without requiring massive amounts of training data.
The paper outlines the problem formulation and the architecture of the SoftTiger models, which are based on large language models but adapted for clinical use. The researchers also describe their approach to training and fine-tuning the models on relevant healthcare data.
Technical Explanation
The paper first formulates the problem of developing high-performance clinical models for a variety of tasks, such as diagnosis, treatment recommendation, and patient monitoring. They note that the limited availability of large, labeled clinical datasets is a major challenge in this domain.
To address this, the authors propose the SoftTiger framework, which consists of a pre-trained foundation model that can be fine-tuned on smaller, domain-specific datasets. The foundation model is based on a large language model, but with modifications to make it better suited for clinical tasks.
The key innovations in the SoftTiger models include:
- Specialized pre-training: The foundation model is pre-trained on a diverse corpus of clinical text data, including electronic health records, medical literature, and clinical notes.
- Modular architecture: The model is designed with a modular structure, allowing different components to be fine-tuned independently for specific tasks.
- Multitask learning: The model is trained to perform multiple healthcare-related tasks simultaneously, enabling it to learn transferable knowledge across different domains.
The researchers evaluate the performance of SoftTiger on a range of clinical benchmarks, demonstrating its superiority over task-specific models trained from scratch. They also show that the modular fine-tuning approach allows the model to adapt quickly to new tasks with minimal additional training.
Critical Analysis
The paper presents a promising approach to addressing the challenges of clinical model development, but it also raises some important caveats and areas for further research:
- Data quality and bias: The performance of the SoftTiger models is heavily dependent on the quality and representativeness of the pre-training and fine-tuning datasets. The authors acknowledge the potential for biases in clinical data, which could be amplified in the models.
- Interpretability and transparency: As with many large language models, the inner workings of SoftTiger may be opaque, making it difficult to understand the reasoning behind its predictions. This could be a concern in high-stakes medical applications.
- Scalability and computational efficiency: The training and fine-tuning of large foundation models like SoftTiger can be computationally intensive and resource-heavy. The authors do not address the practical challenges of deploying and scaling these models in real-world clinical settings.
Overall, the SoftTiger framework represents an important step towards more versatile and data-efficient clinical AI systems. However, further research is needed to address the limitations and ensure the safe and responsible deployment of these models in healthcare.
Conclusion
The SoftTiger paper introduces a novel approach to developing clinical AI models that can be easily adapted to a variety of healthcare-related tasks. By leveraging the power of large language models and a modular, multitask learning architecture, the researchers aim to overcome the challenges posed by limited clinical data availability.
The technical innovations described in the paper, such as specialized pre-training and fine-tuning strategies, demonstrate the potential of this approach to improve the performance and versatility of clinical AI systems. However, the authors also acknowledge the need to address important concerns around data bias, model interpretability, and practical deployment considerations.
Overall, the SoftTiger framework represents an important step forward in the field of clinical AI, and the insights gained from this research could have significant implications for the development of more effective and trustworthy healthcare technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
SoftTiger: A Clinical Foundation Model for Healthcare Workflows
Ye Chen, Igor Couto, Wei Cai, Cong Fu, Bruno Dorneles
We introduce SoftTiger, a clinical large language model (CLaM) designed as a foundation model for healthcare workflows. The narrative and unstructured nature of clinical notes is a major obstacle for healthcare intelligentization. We address a critical problem of structuring clinical notes into clinical data, according to international interoperability standards. We collect and annotate data for three subtasks, namely, international patient summary, clinical impression and medical encounter. We then supervised fine-tuned a state-of-the-art LLM using public and credentialed clinical data. The training is orchestrated in a way that the target model can first support basic clinical tasks such as abbreviation expansion and temporal information extraction, and then learn to perform more complex downstream clinical tasks. Moreover, we address several modeling challenges in the healthcare context, e.g., extra long context window. Our blind pairwise evaluation shows that SoftTiger outperforms other popular open-source models and GPT-3.5, comparable to Gemini-pro, with a mild gap from GPT-4. We believe that LLMs may become a step-stone towards healthcare digitalization and democratization. Therefore, we publicly release SoftTiger models at scales of 13 billion and 70 billion parameters, as well as datasets and code for our innovative scalable evaluation, hopefully, making a significant contribution to the healthcare industry.
Read more8/21/2024
0
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
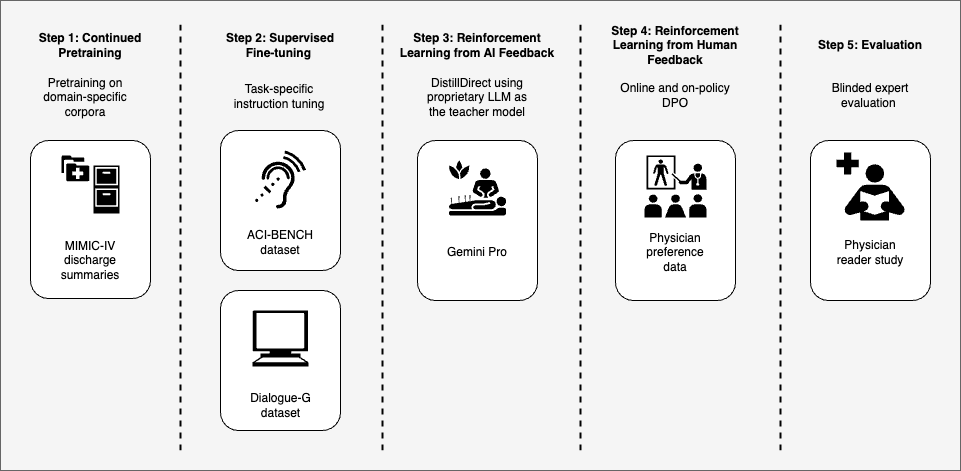
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
Read more6/11/2024
💬
0
Answering real-world clinical questions using large language model based systems
Yen Sia Low (Atropos Health, New York NY, USA), Michael L. Jackson (Atropos Health, New York NY, USA), Rebecca J. Hyde (Atropos Health, New York NY, USA), Robert E. Brown (Atropos Health, New York NY, USA), Neil M. Sanghavi (Atropos Health, New York NY, USA), Julian D. Baldwin (Atropos Health, New York NY, USA), C. William Pike (Atropos Health, New York NY, USA), Jananee Muralidharan (Atropos Health, New York NY, USA), Gavin Hui (Atropos Health, New York NY, USA, Department of Medicine, University of California, Los Angeles CA, USA), Natasha Alexander (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Hadeel Hassan (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Rahul V. Nene (Department of Emergency Medicine, University of California, San Diego CA, USA), Morgan Pike (Department of Emergency Medicine, University of Michigan, Ann Arbor MI, USA), Courtney J. Pokrzywa (Department of Surgery, Columbia University, New York NY, USA), Shivam Vedak (Center for Biomedical Informatics Research, Stanford University, Stanford CA, USA), Adam Paul Yan (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Dong-han Yao (Center for Biomedical Informatics Research, Stanford University, Stanford CA, USA), Amy R. Zipursky (Department of Pediatrics, The Hospital for Sick Children, Toronto ON, Canada), Christina Dinh (Atropos Health, New York NY, USA), Philip Ballentine (Atropos Health, New York NY, USA), Dan C. Derieg (Atropos Health, New York NY, USA), Vladimir Polony (Atropos Health, New York NY, USA), Rehan N. Chawdry (Atropos Health, New York NY, USA), Jordan Davies (Atropos Health, New York NY, USA), Brigham B. Hyde (Atropos Health, New York NY, USA), Nigam H. Shah (Atropos Health, New York NY, USA, Center for Biomedical Informatics Research, Stanford University, Stanford CA, USA), Saurabh Gombar (Atropos Health, New York NY, USA, Department of Pathology, Stanford University, Stanford CA, USA)
Evidence to guide healthcare decisions is often limited by a lack of relevant and trustworthy literature as well as difficulty in contextualizing existing research for a specific patient. Large language models (LLMs) could potentially address both challenges by either summarizing published literature or generating new studies based on real-world data (RWD). We evaluated the ability of five LLM-based systems in answering 50 clinical questions and had nine independent physicians review the responses for relevance, reliability, and actionability. As it stands, general-purpose LLMs (ChatGPT-4, Claude 3 Opus, Gemini Pro 1.5) rarely produced answers that were deemed relevant and evidence-based (2% - 10%). In contrast, retrieval augmented generation (RAG)-based and agentic LLM systems produced relevant and evidence-based answers for 24% (OpenEvidence) to 58% (ChatRWD) of questions. Only the agentic ChatRWD was able to answer novel questions compared to other LLMs (65% vs. 0-9%). These results suggest that while general-purpose LLMs should not be used as-is, a purpose-built system for evidence summarization based on RAG and one for generating novel evidence working synergistically would improve availability of pertinent evidence for patient care.
Read more7/2/2024
💬
0
Clinical Insights: A Comprehensive Review of Language Models in Medicine
Nikita Neveditsin, Pawan Lingras, Vijay Mago
This paper provides a detailed examination of the advancements and applications of large language models in the healthcare sector, with a particular emphasis on clinical applications. The study traces the evolution of LLMs from their foundational technologies to the latest developments in domain-specific models and multimodal integration. It explores the technical progression from encoder-based models requiring fine-tuning to sophisticated approaches that integrate textual, visual, and auditory data, thereby facilitating comprehensive AI solutions in healthcare. The paper discusses both the opportunities these technologies present for enhancing clinical efficiency and the challenges they pose in terms of ethics, data privacy, and implementation. Additionally, it critically evaluates the deployment strategies of LLMs, emphasizing the necessity of open-source models to ensure data privacy and adaptability within healthcare environments. Future research directions are proposed, focusing on empirical studies to evaluate the real-world efficacy of LLMs in healthcare and the development of open datasets for further research. This review aims to provide a comprehensive resource for both newcomers and multidisciplinary researchers interested in the intersection of AI and healthcare.
Read more9/4/2024