The Solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition

0

Sign in to get full access
Overview
- The paper presents a solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition.
- The proposed approach aims to address the challenge of continual learning, where an AI model must learn new tasks sequentially without forgetting previously learned information.
- The solution involves a novel pairwise layer architecture and other techniques to mitigate catastrophic forgetting and improve performance on the sequential task learning track.
Plain English Explanation
The paper describes a method for training artificial intelligence (AI) models to continually learn new tasks without forgetting what they've learned before. This is an important challenge in the field of machine learning, known as "continual learning."
In a continual learning scenario, an AI model is presented with a series of tasks to learn, one after the other. The model needs to be able to learn each new task while still maintaining its performance on the previous tasks. This is difficult because the model can tend to "forget" what it has learned before, a phenomenon known as "catastrophic forgetting."
The researchers in this paper have developed a new architecture and techniques to help AI models overcome catastrophic forgetting and perform well on a sequence of tasks. Their pairwise layer architecture and other methods aim to allow the model to more effectively learn and retain information as it encounters new tasks.
By addressing the challenge of continual learning, this research could lead to AI systems that are more adaptable and capable of handling real-world, evolving environments where the tasks and data are constantly changing. This could have significant implications for the development of more robust and versatile AI applications.
Technical Explanation
The paper proposes a solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The key technical components of their approach include:
-
Pairwise Layer Architecture: The researchers introduce a pairwise layer architecture that consists of pairs of layers, where each pair is responsible for learning a specific task. This architecture helps to mitigate catastrophic forgetting by isolating the parameters associated with each task.
-
Data-aware and Parameter-aware Robustness: The model also incorporates techniques to improve data-aware and parameter-aware robustness, which help the model adapt to changes in the data distribution and task requirements during continual learning.
-
Adaptive Optimization Methods: The paper explores the use of adaptive optimization methods to improve the model's performance and convergence during continual learning.
-
Attention-guided Knowledge Distillation: The researchers also incorporate an attention-guided knowledge distillation mechanism to selectively transfer relevant knowledge from previous tasks to the current task, further mitigating catastrophic forgetting.
-
Distributed Continual Learning: Finally, the paper investigates a distributed continual learning approach to leverage the computational resources of multiple devices and improve the efficiency of the continual learning process.
The combination of these technical components allows the proposed solution to achieve strong performance on the sequential task continual learning track of the competition.
Critical Analysis
The paper presents a comprehensive approach to addressing the challenge of continual learning, incorporating several state-of-the-art techniques. However, the authors acknowledge that there are still some limitations and areas for further research:
-
Scalability and Complexity: While the proposed methods demonstrate promising results, the increased architectural complexity and computational requirements may limit the scalability of the approach, particularly for larger-scale or more diverse task sequences.
-
Task Interference: The paper notes that there may still be some residual interference between tasks, even with the attention-guided knowledge distillation mechanism. Further research is needed to fully mitigate such interference.
-
Interpretability and Explainability: The intricate nature of the pairwise layer architecture and the various techniques employed may make it challenging to interpret the model's decision-making process and explain its behavior, which could be a concern for certain applications.
-
Real-world Applicability: The paper focuses on the specific competition task, and additional research may be needed to evaluate the generalization and applicability of the proposed solution to more diverse and realistic continual learning scenarios.
Overall, the paper presents a well-designed and comprehensive solution for the sequential task continual learning challenge, but there remain opportunities for further refinement and exploration to address the identified limitations and enhance the real-world practicality of the approach.
Conclusion
The paper introduced a novel solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The key aspects of the proposed approach include a pairwise layer architecture, techniques to improve data-aware and parameter-aware robustness, the use of adaptive optimization methods, attention-guided knowledge distillation, and a distributed continual learning framework.
The combination of these components allows the model to effectively learn new tasks while mitigating catastrophic forgetting, thereby achieving strong performance on the competition's sequential task continual learning track. This research contributes to the ongoing efforts in the field of continual learning, which is crucial for developing versatile and adaptable AI systems that can thrive in dynamic, real-world environments.
While the paper presents a comprehensive solution, there are still areas for further refinement and exploration, such as improving scalability, addressing residual task interference, enhancing interpretability, and validating the approach in a broader range of continual learning scenarios. Continued advancements in this field could lead to significant breakthroughs in the development of more robust and capable AI systems that can learn and adapt over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
The Solution for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition
Sishun Pan, Xixian Wu, Tingmin Li, Longfei Huang, Mingxu Feng, Zhonghua Wan, Yang Yang
This paper presents a data-free, parameter-isolation-based continual learning algorithm we developed for the sequential task continual learning track of the 2nd Greater Bay Area International Algorithm Competition. The method learns an independent parameter subspace for each task within the network's convolutional and linear layers and freezes the batch normalization layers after the first task. Specifically, for domain incremental setting where all domains share a classification head, we freeze the shared classification head after first task is completed, effectively solving the issue of catastrophic forgetting. Additionally, facing the challenge of domain incremental settings without providing a task identity, we designed an inference task identity strategy, selecting an appropriate mask matrix for each sample. Furthermore, we introduced a gradient supplementation strategy to enhance the importance of unselected parameters for the current task, facilitating learning for new tasks. We also implemented an adaptive importance scoring strategy that dynamically adjusts the amount of parameters to optimize single-task performance while reducing parameter usage. Moreover, considering the limitations of storage space and inference time, we designed a mask matrix compression strategy to save storage space and improve the speed of encryption and decryption of the mask matrix. Our approach does not require expanding the core network or using external auxiliary networks or data, and performs well under both task incremental and domain incremental settings. This solution ultimately won a second-place prize in the competition.
Read more7/9/2024
🧪
0
Task agnostic continual learning with Pairwise layer architecture
Santtu Keskinen
Most of the dominant approaches to continual learning are based on either memory replay, parameter isolation, or regularization techniques that require task boundaries to calculate task statistics. We propose a static architecture-based method that doesn't use any of these. We show that we can improve the continual learning performance by replacing the final layer of our networks with our pairwise interaction layer. The pairwise interaction layer uses sparse representations from a Winner-take-all style activation function to find the relevant correlations in the hidden layer representations. The networks using this architecture show competitive performance in MNIST and FashionMNIST-based continual image classification experiments. We demonstrate this in an online streaming continual learning setup where the learning system cannot access task labels or boundaries.
Read more5/24/2024
0
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
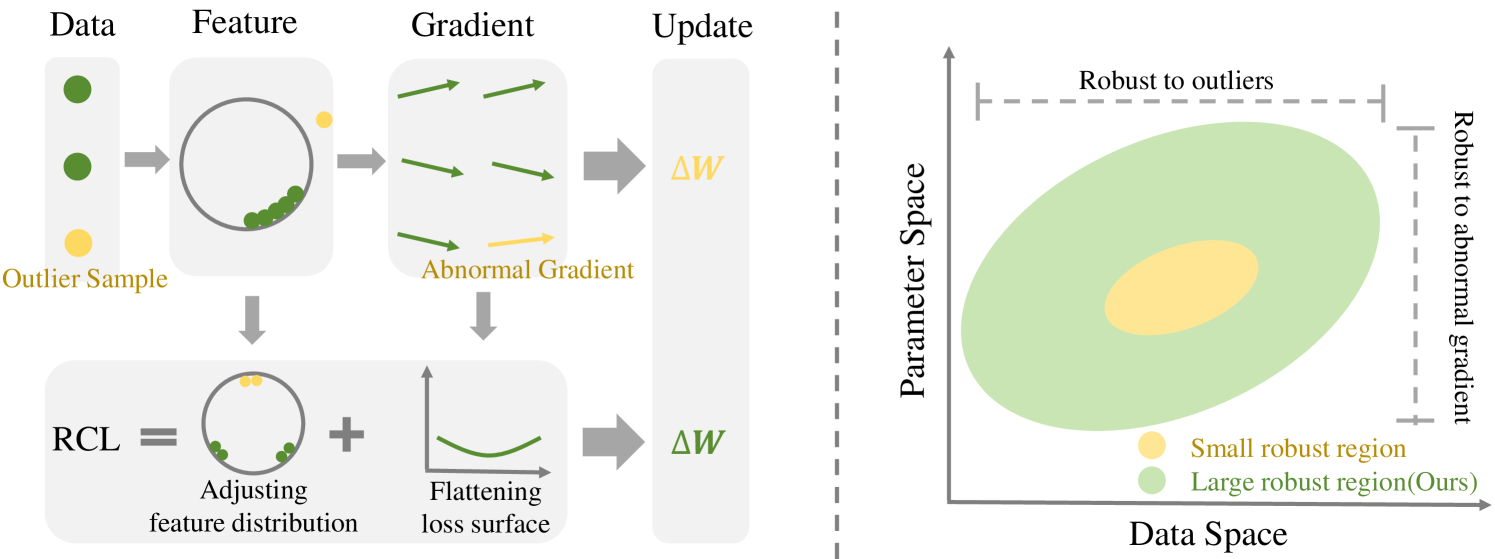
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
Read more5/28/2024
0
Adaptive Cascading Network for Continual Test-Time Adaptation
Kien X. Nguyen, Fengchun Qiao, Xi Peng
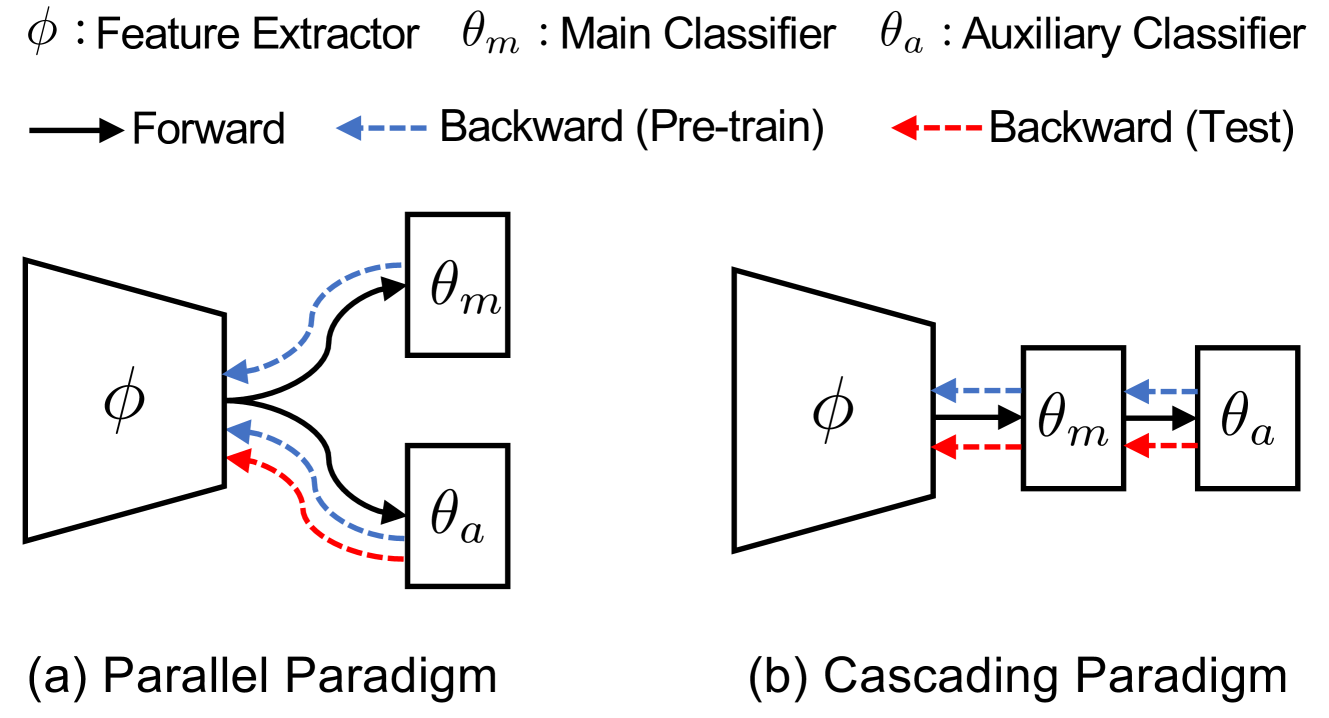
We study the problem of continual test-time adaption where the goal is to adapt a source pre-trained model to a sequence of unlabelled target domains at test time. Existing methods on test-time training suffer from several limitations: (1) Mismatch between the feature extractor and classifier; (2) Interference between the main and self-supervised tasks; (3) Lack of the ability to quickly adapt to the current distribution. In light of these challenges, we propose a cascading paradigm that simultaneously updates the feature extractor and classifier at test time, mitigating the mismatch between them and enabling long-term model adaptation. The pre-training of our model is structured within a meta-learning framework, thereby minimizing the interference between the main and self-supervised tasks and encouraging fast adaptation in the presence of limited unlabelled data. Additionally, we introduce innovative evaluation metrics, average accuracy and forward transfer, to effectively measure the model's adaptation capabilities in dynamic, real-world scenarios. Extensive experiments and ablation studies demonstrate the superiority of our approach in a range of tasks including image classification, text classification, and speech recognition.
Read more7/18/2024