Sora and V-JEPA Have Not Learned The Complete Real World Model -- A Philosophical Analysis of Video AIs Through the Theory of Productive Imagination

0
📈
Sign in to get full access
Overview
- The paper discusses the debate around whether AI systems like Sora from OpenAI have truly comprehensive world understanding, or if they lack fundamental knowledge.
- It introduces V-JEPA from Meta as an approach aiming to address this issue through joint embedding.
- The authors develop a theory of "productive imagination" based on Kantian philosophy to identify key components of a coherent world model.
- The analysis reveals limitations in both Sora and V-JEPA in fully achieving genuine world understanding.
- The paper proposes a training framework for an AI "productive imagination-understanding engine" to advance towards comprehensive world modeling.
Plain English Explanation
This paper explores a critical question in the field of artificial intelligence (AI): do advanced AI systems like Sora from OpenAI truly understand the world around them, or do they lack a fundamental grasp of reality?
The authors argue that while these AI models demonstrate impressive technological capabilities, they may not have a comprehensive understanding of the world. They introduce V-JEPA from Meta as an approach that aims to address this issue by learning the context-dependent aspects of the world through a joint embedding approach.
To better understand what a "comprehensive world understanding" would entail, the authors develop a theory based on Kantian philosophy. They identify three essential components: representations of isolated objects, an a priori law of change across space and time, and Kantian categories (fundamental concepts that structure our understanding of the world).
The analysis reveals that both Sora and V-JEPA fall short in fully incorporating these components, limiting their ability to achieve genuine world understanding. For example, Sora lacks a proper grasp of the a priori law of change and Kantian categories, while V-JEPA struggles to fully comprehend Kantian categories and incorporate real-world experience.
Nevertheless, the authors believe that each system has developed important building blocks towards an integrated "productive imagination-understanding engine" that could eventually achieve comprehensive world modeling. They propose an innovative training framework centered around a joint embedding system to transform raw sensory inputs into a structured, coherent world model.
The paper's philosophical analysis highlights critical challenges in contemporary video AI technologies and suggests a path forward towards an AI system capable of true, human-like understanding of the world, which could have far-reaching implications for reasoning, planning, and decision-making in the future.
Technical Explanation
The paper presents a theoretical framework for evaluating the world understanding capabilities of advanced AI systems, such as Sora from OpenAI and V-JEPA from Meta.
The authors develop a theory of "productive imagination" based on Kantian philosophy, which identifies three essential components of a coherent world model: representations of isolated objects, an a priori law of change across space and time, and Kantian categories (fundamental concepts that structure our understanding of the world).
Through this theoretical lens, the authors analyze the limitations of Sora and V-JEPA. They find that Sora is hindered by its lack of understanding of the a priori law of change and Kantian categories, which are not rectifiable through simply scaling up the training data.
In contrast, V-JEPA attempts to address the context-dependent aspects of the a priori law of change through its joint embedding approach. However, the analysis reveals that V-JEPA still fails to fully comprehend Kantian categories and integrate real-world experience into its world model.
The paper proposes an innovative training framework for an "AI productive imagination-understanding engine" that centers around a joint embedding system. This system aims to transform disordered perceptual input into a structured, coherent world model by incorporating the key components identified in the Kantian-inspired theory.
The authors argue that while neither Sora nor V-JEPA currently achieve comprehensive world understanding, each system has developed essential components towards an integrated AI engine capable of genuine world modeling. The paper's philosophical analysis provides a framework for evaluating the progress and limitations of contemporary video AI technologies in this direction.
Critical Analysis
The paper raises valid concerns about the depth of world understanding achieved by state-of-the-art AI systems like Sora and V-JEPA. The authors' Kantian-inspired theory of "productive imagination" provides a useful framework for evaluating the essential components of a truly coherent world model.
However, the paper acknowledges the inherent challenges in fully realizing this vision, as evidenced by the limitations identified in both Sora and V-JEPA. Integrating representations of isolated objects, the a priori law of change, and Kantian categories into a unified world model remains an elusive goal for current AI technologies.
Furthermore, the paper does not address the potential trade-offs or practical considerations involved in developing such a comprehensive world understanding system. For example, the computational and data requirements, the scalability to real-world complexity, and the potential challenges in aligning such a system with human values and preferences.
Additionally, the paper could have delved deeper into the specific ways in which Sora and V-JEPA fall short in their world understanding, providing more concrete examples and empirical evidence to support the authors' claims. This could have strengthened the critical analysis and highlighted the nuances of the debate.
Despite these minor limitations, the paper's philosophical analysis and the proposed training framework for an "AI productive imagination-understanding engine" offer a valuable contribution to the ongoing discussion around the development of artificial general intelligence (AGI) systems with genuine world understanding capabilities.
Conclusion
This paper presents a thought-provoking exploration of the fundamental question of whether advanced AI systems like Sora and V-JEPA truly comprehend the world around them, or if they lack a deeper, more integrated understanding.
By developing a Kantian-inspired theory of "productive imagination," the authors identify key components that they argue are essential for a coherent world model. Their analysis reveals limitations in both Sora and V-JEPA in fully incorporating these components, suggesting that current AI technologies are still falling short of achieving genuine world understanding.
The paper's proposed training framework for an "AI productive imagination-understanding engine" offers a promising direction for advancing towards more comprehensive world modeling. If realized, such a system could have significant implications for the development of artificial general intelligence (AGI) with human-like reasoning and decision-making capabilities.
While the challenges are substantial, the paper's philosophical analysis and the proposed research directions contribute to the ongoing debate around the future of AI and its ability to achieve a deeper, more integrated understanding of the world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Sora and V-JEPA Have Not Learned The Complete Real World Model -- A Philosophical Analysis of Video AIs Through the Theory of Productive Imagination
Jianqiu Zhang
Sora from Open AI has shown exceptional performance, yet it faces scrutiny over whether its technological prowess equates to an authentic comprehension of reality. Critics contend that it lacks a foundational grasp of the world, a deficiency V-JEPA from Meta aims to amend with its joint embedding approach. This debate is vital for steering the future direction of Artificial General Intelligence(AGI). We enrich this debate by developing a theory of productive imagination that generates a coherent world model based on Kantian philosophy. We identify three indispensable components of the coherent world model capable of genuine world understanding: representations of isolated objects, an a priori law of change across space and time, and Kantian categories. Our analysis reveals that Sora is limited because of its oversight of the a priori law of change and Kantian categories, flaws that are not rectifiable through scaling up the training. V-JEPA learns the context-dependent aspect of the a priori law of change. Yet it fails to fully comprehend Kantian categories and incorporate experience, leading us to conclude that neither system currently achieves a comprehensive world understanding. Nevertheless, each system has developed components essential to advancing an integrated AI productive imagination-understanding engine. Finally, we propose an innovative training framework for an AI productive imagination-understanding engine, centered around a joint embedding system designed to transform disordered perceptual input into a structured, coherent world model. Our philosophical analysis pinpoints critical challenges within contemporary video AI technologies and a pathway toward achieving an AI system capable of genuine world understanding, such that it can be applied for reasoning and planning in the future.
Read more7/16/2024
🤷
0
Is Sora a World Simulator? A Comprehensive Survey on General World Models and Beyond
Zheng Zhu, Xiaofeng Wang, Wangbo Zhao, Chen Min, Nianchen Deng, Min Dou, Yuqi Wang, Botian Shi, Kai Wang, Chi Zhang, Yang You, Zhaoxiang Zhang, Dawei Zhao, Liang Xiao, Jian Zhao, Jiwen Lu, Guan Huang
General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: https://github.com/GigaAI-research/General-World-Models-Survey.
Read more5/7/2024
🛸
0
Sora as an AGI World Model? A Complete Survey on Text-to-Video Generation
Joseph Cho, Fachrina Dewi Puspitasari, Sheng Zheng, Jingyao Zheng, Lik-Hang Lee, Tae-Ho Kim, Choong Seon Hong, Chaoning Zhang
The evolution of video generation from text, starting with animating MNIST numbers to simulating the physical world with Sora, has progressed at a breakneck speed over the past seven years. While often seen as a superficial expansion of the predecessor text-to-image generation model, text-to-video generation models are developed upon carefully engineered constituents. Here, we systematically discuss these elements consisting of but not limited to core building blocks (vision, language, and temporal) and supporting features from the perspective of their contributions to achieving a world model. We employ the PRISMA framework to curate 97 impactful research articles from renowned scientific databases primarily studying video synthesis using text conditions. Upon minute exploration of these manuscripts, we observe that text-to-video generation involves more intricate technologies beyond the plain extension of text-to-image generation. Our additional review into the shortcomings of Sora-generated videos pinpoints the call for more in-depth studies in various enabling aspects of video generation such as dataset, evaluation metric, efficient architecture, and human-controlled generation. Finally, we conclude that the study of the text-to-video generation may still be in its infancy, requiring contribution from the cross-discipline research community towards its advancement as the first step to realize artificial general intelligence (AGI).
Read more6/10/2024
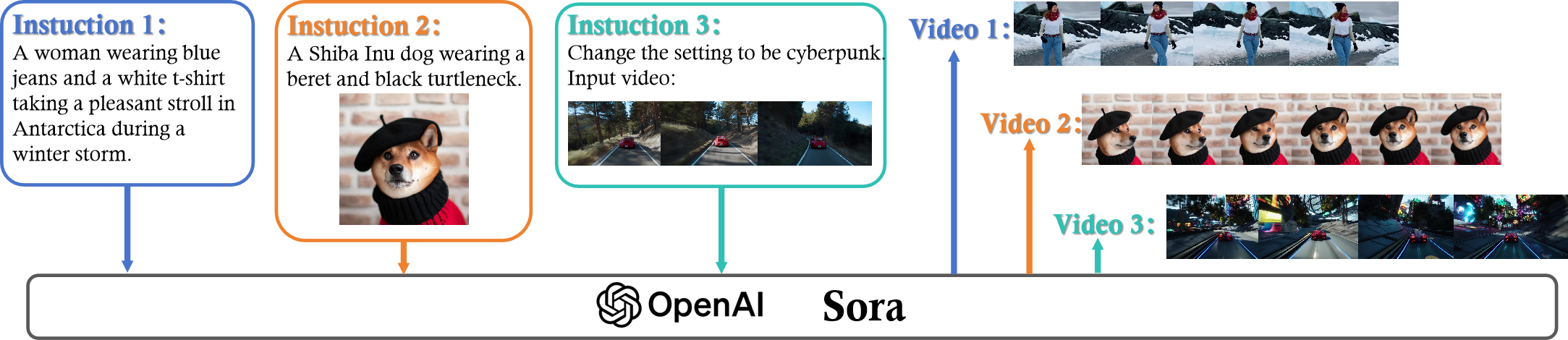
23
Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models
Yixin Liu, Kai Zhang, Yuan Li, Zhiling Yan, Chujie Gao, Ruoxi Chen, Zhengqing Yuan, Yue Huang, Hanchi Sun, Jianfeng Gao, Lifang He, Lichao Sun
Sora is a text-to-video generative AI model, released by OpenAI in February 2024. The model is trained to generate videos of realistic or imaginative scenes from text instructions and show potential in simulating the physical world. Based on public technical reports and reverse engineering, this paper presents a comprehensive review of the model's background, related technologies, applications, remaining challenges, and future directions of text-to-video AI models. We first trace Sora's development and investigate the underlying technologies used to build this world simulator. Then, we describe in detail the applications and potential impact of Sora in multiple industries ranging from film-making and education to marketing. We discuss the main challenges and limitations that need to be addressed to widely deploy Sora, such as ensuring safe and unbiased video generation. Lastly, we discuss the future development of Sora and video generation models in general, and how advancements in the field could enable new ways of human-AI interaction, boosting productivity and creativity of video generation.
Read more4/19/2024