SparQ Attention: Bandwidth-Efficient LLM Inference

0

Sign in to get full access
Overview
- Introduces a novel attention mechanism called "SparQ Attention" that can significantly reduce the bandwidth required for large language model (LLM) inference
- Demonstrates the effectiveness of SparQ Attention on various language tasks, including natural language generation, question answering, and text classification
- Provides insights into the potential for bandwidth-efficient LLM inference, which could enable more accessible and energy-efficient AI applications
Plain English Explanation
The SparQ Attention paper presents a new way to make large language models (LLMs) more efficient. LLMs are powerful AI systems that can generate human-like text, answer questions, and perform other language-related tasks. However, running these models can be resource-intensive, requiring a lot of computing power and data transfer.
The researchers behind this paper developed a technique called "SparQ Attention" that can significantly reduce the amount of data needed to run an LLM. The key idea is to selectively transfer only the most important information from the model's attention mechanism, rather than transferring the entire attention matrix. This allows the model to make predictions with much less data, saving on bandwidth and energy consumption.
The paper demonstrates that SparQ Attention can maintain the performance of LLMs while reducing the required bandwidth by up to 90%. This could enable more accessible and energy-efficient AI applications, such as running language models on mobile devices or in low-power settings.
Technical Explanation
The SparQ Attention paper proposes a novel attention mechanism called "SparQ Attention" that can significantly reduce the bandwidth required for large language model (LLM) inference.
The core idea of SparQ Attention is to selectively transfer only the most important information from the model's attention mechanism, rather than transferring the entire attention matrix. This is achieved by identifying a smaller set of "salient" attention weights that capture the key dependencies in the input sequence.
The paper introduces two key components to realize this:
- Attention Memory Transfer: A technique to efficiently transfer the salient attention weights from the model to the client, reducing the overall bandwidth requirements.
- SparQ Attention: A modified attention mechanism that can be seamlessly integrated into existing LLMs to enable bandwidth-efficient inference.
The authors evaluate the effectiveness of SparQ Attention on various language tasks, including natural language generation, question answering, and text classification. They demonstrate that SparQ Attention can maintain the performance of LLMs while reducing the required bandwidth by up to 90%, outperforming alternative [bandwidth-efficient techniques](https://aimodels.fyi/papers/arxiv/self-selected-attention-span-accelerating-large-language, https://aimodels.fyi/papers/arxiv/quickllama-query-aware-inference-acceleration-large-language, https://aimodels.fyi/papers/arxiv/relayattention-efficient-large-language-model-serving-long).
Critical Analysis
The SparQ Attention paper presents a promising approach to making large language model (LLM) inference more bandwidth-efficient. By selectively transferring only the most important attention information, the technique can significantly reduce the data requirements while maintaining model performance.
However, the paper does not address the potential impact of this selective attention on the interpretability and explainability of the LLM's decision-making process. Removing certain attention weights could affect the model's ability to provide transparent explanations for its outputs, which is an important consideration for many real-world applications.
Additionally, the paper focuses on a specific set of language tasks and does not explore the generalizability of SparQ Attention to other domains or more complex language models. Further research is needed to understand the broader applicability and limitations of this approach.
It's also worth noting that the paper does not discuss the potential security or privacy implications of bandwidth-efficient LLM inference. As AI systems become more widely deployed, it will be crucial to consider the security and privacy trade-offs of such techniques.
Conclusion
The SparQ Attention paper presents an innovative approach to making large language model (LLM) inference more bandwidth-efficient. By selectively transferring only the most important attention information, the SparQ Attention technique can reduce the data requirements by up to 90% while maintaining model performance.
This breakthrough could enable more accessible and energy-efficient AI applications, such as running language models on mobile devices or in low-power settings. The potential for bandwidth-efficient LLM inference could have far-reaching implications for the democratization of AI and the development of more sustainable, environmentally-friendly AI systems.
While the paper raises some critical questions about the interpretability and generalizability of the SparQ Attention approach, it represents an important step forward in the ongoing effort to make large language models more efficient and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SparQ Attention: Bandwidth-Efficient LLM Inference
Luka Ribar, Ivan Chelombiev, Luke Hudlass-Galley, Charlie Blake, Carlo Luschi, Douglas Orr
The computational difficulties of large language model (LLM) inference remain a significant obstacle to their widespread deployment. The need for many applications to support long input sequences and process them in large batches typically causes token-generation to be bottlenecked by data transfer. For this reason, we introduce SparQ Attention, a technique for increasing the inference throughput of LLMs by utilising memory bandwidth more efficiently within the attention layers, through selective fetching of the cached history. Our proposed technique can be applied directly to off-the-shelf LLMs during inference, without requiring any modification to the pre-training setup or additional fine-tuning. We show that SparQ Attention brings up to 8x savings in attention data transfers without substantial drops in accuracy, by evaluating Llama 2 and 3, Mistral, Gemma and Pythia models on a wide range of downstream tasks.
Read more7/22/2024
0
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
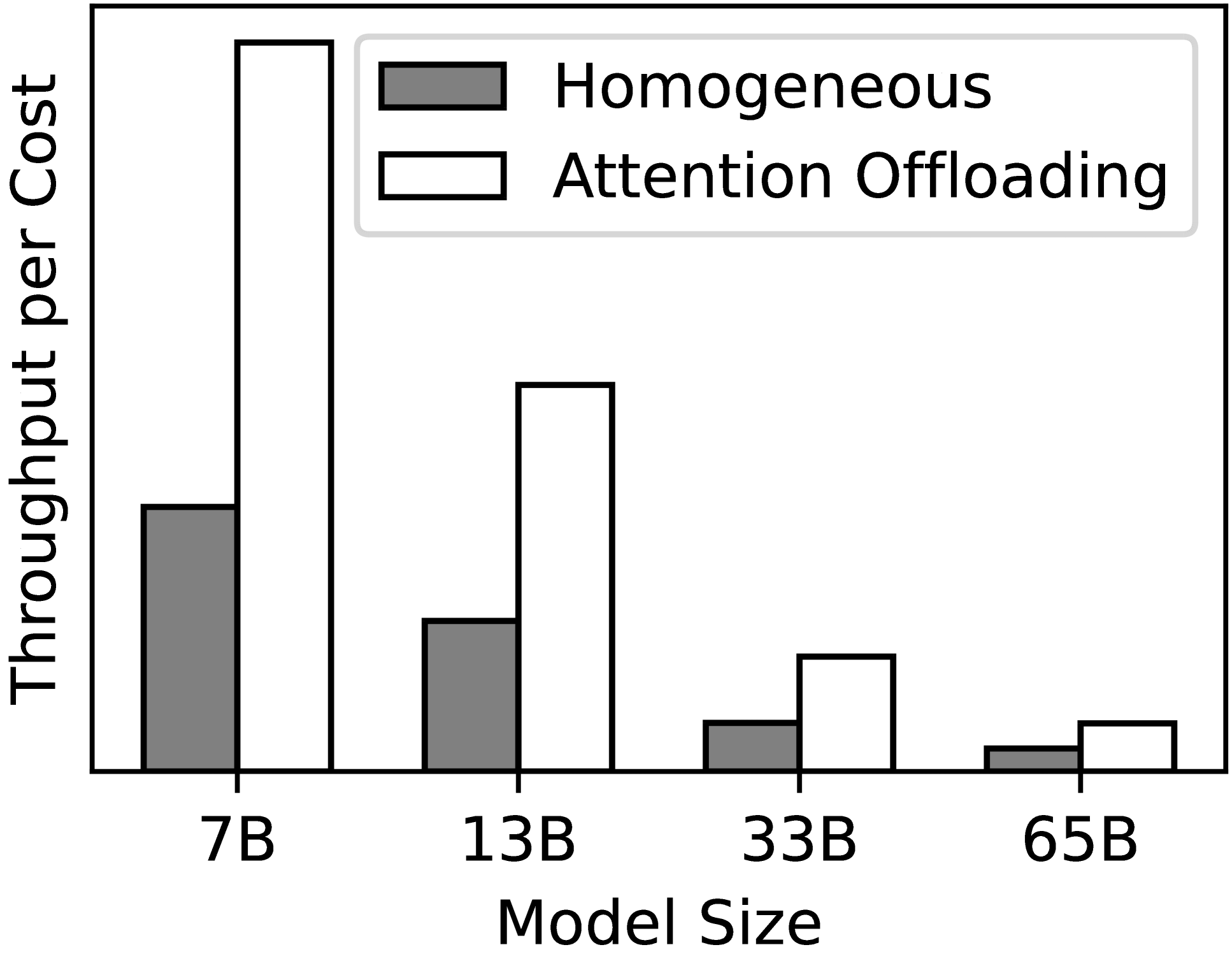
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Read more5/6/2024
0
Self-Selected Attention Span for Accelerating Large Language Model Inference
Tian Jin, Wanzin Yazar, Zifei Xu, Sayeh Sharify, Xin Wang
Large language models (LLMs) can solve challenging tasks. However, their inference computation on modern GPUs is highly inefficient due to the increasing number of tokens they must attend to as they generate new ones. To address this inefficiency, we capitalize on LLMs' problem-solving capabilities to optimize their own inference-time efficiency. We demonstrate with two specific tasks: (a) evaluating complex arithmetic expressions and (b) summarizing news articles. For both tasks, we create custom datasets to fine-tune an LLM. The goal of fine-tuning is twofold: first, to make the LLM learn to solve the evaluation or summarization task, and second, to train it to identify the minimal attention spans required for each step of the task. As a result, the fine-tuned model is able to convert these self-identified minimal attention spans into sparse attention masks on-the-fly during inference. We develop a custom CUDA kernel to take advantage of the reduced context to attend to. We demonstrate that using this custom CUDA kernel improves the throughput of LLM inference by 28%. Our work presents an end-to-end demonstration showing that training LLMs to self-select their attention spans speeds up autoregressive inference in solving real-world tasks.
Read more4/16/2024

0
QuickLLaMA: Query-aware Inference Acceleration for Large Language Models
Jingyao Li, Han Shi, Xin Jiang, Zhenguo Li, Hong Xu, Jiaya Jia
The capacity of Large Language Models (LLMs) to comprehend and reason over long contexts is pivotal for advancements in diverse fields. Yet, they still stuggle with capturing long-distance dependencies within sequences to deeply understand semantics. To address this issue, we introduce Query-aware Inference for LLMs (Q-LLM), a system designed to process extensive sequences akin to human cognition. By focusing on memory data relevant to a given query, Q-LLM can accurately capture pertinent information within a fixed window size and provide precise answers to queries. It doesn't require extra training and can be seamlessly integrated with any LLMs. Q-LLM using LLaMA3 (QuickLLaMA) can read Harry Potter within 30s and accurately answer the questions. On widely recognized benchmarks, Q-LLM improved by 7.17% compared to the current state-of-the-art on LLaMA3, and by 3.26% on Mistral on the $infty$-bench. In the Needle-in-a-Haystack and BABILong task, Q-LLM improved upon the current SOTA by 7.0% and 6.1%. Our code can be found in https://github.com/dvlab-research/Q-LLM.
Read more8/23/2024