Sparse multimodal fusion with modal channel attention
2403.20280
0
0

Abstract
The ability of masked multimodal transformer architectures to learn a robust embedding space when modality samples are sparsely aligned is studied by measuring the quality of generated embedding spaces as a function of modal sparsity. An extension to the masked multimodal transformer model is proposed which incorporates modal-incomplete channels in the multihead attention mechanism called modal channel attention (MCA). Two datasets with 4 modalities are used, CMU-MOSEI for multimodal sentiment recognition and TCGA for multiomics. Models are shown to learn uniform and aligned embedding spaces with only two out of four modalities in most samples. It was found that, even with no modal sparsity, the proposed MCA mechanism improves the quality of generated embedding spaces, recall metrics, and subsequent performance on downstream tasks.
Create account to get full access
Abstract
The study investigates the capability of masked multimodal transformer architectures to learn robust embedding spaces when modality samples are sparsely aligned. An extension called modal channel attention (MCA) incorporates modal-incomplete channels into the multihead attention mechanism of the masked multimodal transformer model. Two datasets with four modalities each, CMU-MOSEI for multimodal sentiment recognition and TCGA for multiomics, are utilized. The models demonstrate the ability to learn uniform and aligned embedding spaces with only two out of four modalities present in most samples. Even in the absence of modal sparsity, the proposed MCA mechanism enhances the quality of generated embedding spaces, recall metrics, and subsequent performance on downstream tasks.
Introduction
The paper discusses the increasing use of multimodal models in deep learning applications, which combine various data formats such as text, audio, images, and video. It highlights the challenges of training models with incomplete or partially aligned modalities, as datasets often contain missing or sparse modalities. The paper proposes an extension of the masked multimodal transformer model called modal channel attention (MCA), which incorporates modal-incomplete channels in the multihead attention block.
The authors demonstrate that MCA can learn high-quality embedding spaces even when modalities are sparsely aligned, up to a sparsity level of 40%, corresponding to an average of 2.4 modalities per sample. Compared to the previous masked multimodal attention (MMA) model, MCA generally improves the quality of generated embedding spaces, recall metrics, and performance on downstream tasks through linear probing.
The paper concludes by discussing potential applications and future research directions in multimodal learning with incomplete or sparsely aligned modalities.
Related Work
The paper discusses several approaches for multimodal representation learning, including the Everything At Once model, FLAVA, Zhang et al.'s model, Wei et al.'s model, LORRETA, and Zorro.
The Everything At Once model uses a fusion transformer with contrastive loss to generate embeddings for each modality and pair of modalities, which are then pooled and projected into a multimodal embedding space. However, this approach scales exponentially with the number of modalities, making it computationally inefficient.
FLAVA uses multiple loss models for data with missing modalities, allowing for unimodal and multimodal inference but not generating a multimodal fusion embedding space. Zhang et al.'s model projects unimodal encodings into a modality-aligned feature space and performs weight-shared dual attention prediction, improving predictions for unseen modalities.
Wei et al.'s model and LORRETA are trained to generate missing modalities but cannot directly embed higher-order modality combinations or produce a fused embedding space applicable to tasks like retrieval or linear probing.
Zorro is an MMA model that produces unimodal and multimodal outputs trained with a contrastive loss. A similar MMA architecture was applied by Shi et al. for image segmentation in a biomedical application, though the performance with sparsely aligned multimodal data was not directly explored.

Model
The model architecture consists of a transformer encoder with a learnable pooling layer and noise contrastive estimation (NCE) loss between pooled tokens. Trainable transformations are applied to the input data, such as linear transformations or MLPs, to encode tabular data or compress pretrained frozen embeddings. The attention model uses Multi-Modal Attention (MMA) with fusion token blocks attended by unimodal token blocks. Multi-channel attention is introduced, where blocks of fusion attention are attended to by a subset of modalities, maintaining efficiency regardless of the number of modalities. Each fusion channel corresponds to a different set of modalities, with a unique pooling token in the learnable pooling layer. NCE Loss is applied between each pair of unimodal and fusion channel tokens. The fusion channel attended to by all modalities is used for downstream tasks. The learnable pooling layer has a multimodal mask preventing fusion tokens from attending to unimodal tokens. The model uses 5 transformer encoder layers with a hidden size of 512 and 8 attention heads. The feed-forward layers use a feed-forward multiplier of 4 and the GeGLU activation function. There are 88 fusion tokens in both studied models, with the MCA transformer using 11 channels of 8 tokens each, pooled separately.
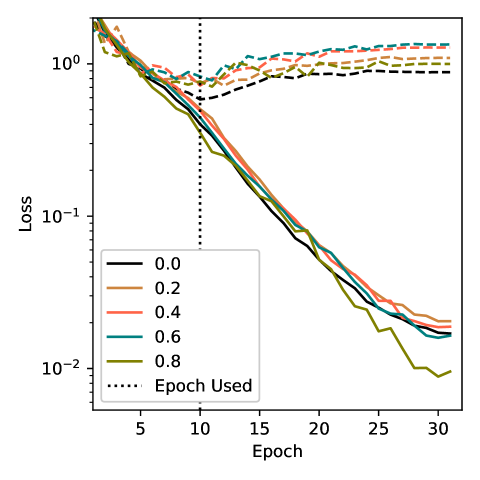
Methods
The paper discusses the datasets and training procedures used in the experiments. The CMU-MOSEI dataset contains 23,248 samples of aligned multimodal data (text, audio, and video) with a test split of 2,324 samples. Each modality is preprocessed and transformed into token embeddings using linear layers and positional embeddings.
The TCGA dataset consists of tabular data from multiple omics sources like gene expression and DNA methylation. After preprocessing, it has 7,017 multimodal samples with a test split of 707 samples. The tabular data is encoded using trainable MLPs and combined with column index embeddings.
The paper evaluates performance under modal sparsity, where some modalities are randomly dropped from samples during training. Sparsity levels of 0, 0.2, 0.4, 0.6, and 0.8 are used.
Training used 4 Nvidia GPUs, a batch size of 32, cosine learning rate scheduling, and varied epoch numbers for the two datasets. Figures show metrics like embedding space uniformity, alignment between modalities, median rank, and recall at different sparsity levels on the test sets.
Evaluation of Embeddings
The section analyzes the characteristics of embeddings produced by trained multimodal models, focusing on alignment and uniformity metrics. The Multiple Choice Alignment (MCA) model achieves significantly lower uniformity (indicating a more uniform embedding space) than the Multimodal Mixture-of-Experts (MMA) model, while its alignment is increased. As modal sparsity increases beyond 40%, both models' fusion uniformities worsen, indicating less uniform unimodal embedding spaces.
The recall metrics (median rank, R1, R5, and R10) demonstrate the ability of the model to use a unimodal embedding to recall a fused embedding. The MCA architecture shows improved average median rank and recall metrics over MMA for most modal sparsities examined in both datasets studied. The improvement is more significant in the smaller TCGA dataset at low modal sparsity and in the larger CMU-MOSEI dataset at high modal sparsity.
The results highlight the utility of using MCA as a method for retrieving embeddings containing information from multiple modalities, even when only a single modality is available at inference time and training examples contain sparsely aligned modalities.

This section evaluates the performance of the generated embeddings from the proposed models on two downstream tasks: cancer type classification on the TCGA dataset and sentiment analysis on the CMU-MOSEI dataset. Linear probing is used, where a linear layer is trained on the embeddings produced from the training data, and the metrics are calculated on the test data.
For the TCGA dataset, a multiclass cancer type classification task with 32 classes, the class-averaged area under the precision-recall curve (AUPR) is presented. Both MCA and MMA perform well, with MCA showing a slight improvement over MMA as modal sparsity increases up to 0.4.
For the CMU-MOSEI sentiment analysis task, which involves regression to a single value between 0 and 1 for negative and positive sentiment, the correlation coefficient is used as the metric. MCA meets the baseline result of 0.54 when no modal sparsity is present. As modal sparsity increases, the correlation coefficient decreases, and MCA and MMA results become similar, with a minor advantage for MCA.
In general, MCA provides improved results over MMA for both datasets.
Conclusion
The paper discusses masked multimodal transformer architectures, which can learn embedding spaces robust to missing modalities. It presents multichannel attention (MCA) as an extension of the masked multimodal transformer model, incorporating modal-incomplete channels in the multihead attention mechanism.
Using two well-known datasets with four modalities each, the paper demonstrates that both MMA (Masked Multimodal Attention) and MCA can learn high-quality embedding spaces up to a modal sparsity of 0.4, corresponding to 1-2 modalities most frequently missing per sample.
The results show that MCA generally improves the quality of embedding spaces, recall metrics, and subsequent performance on downstream tasks.
The paper suggests future research directions, including extending the architecture to autoencoding or joint embedding predictive architectures for multimodal transformers, exploring multimodal scaling laws with modal sparsity, and investigating foundational model scale datasets for multimodal representation learning with sparsely aligned datasets.
Acknowledgments
This section acknowledges contributions from individuals who provided helpful discussions during the study. These individuals are Clayton Rabideau, Gabrielle Griffin, Callum Birch-Sykes, and Archis Joglekar. Additionally, it states that the results presented in the paper are derived, either wholly or partially, from data generated by the TCGA Research Network, providing the relevant website link.
Additional Figures
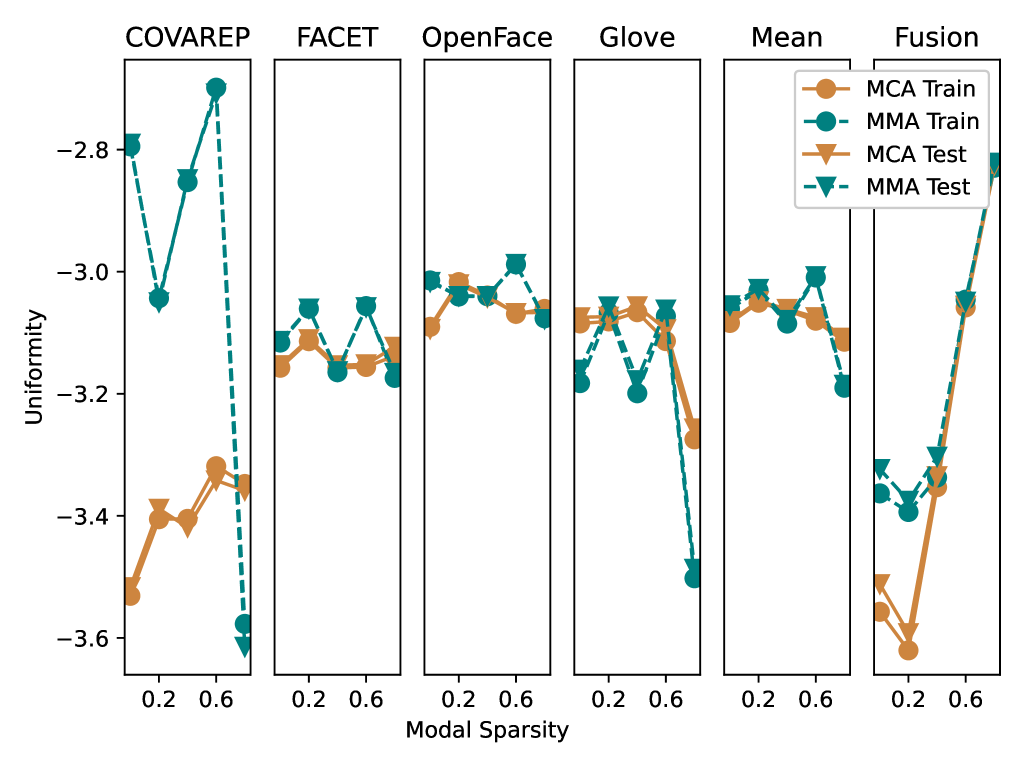

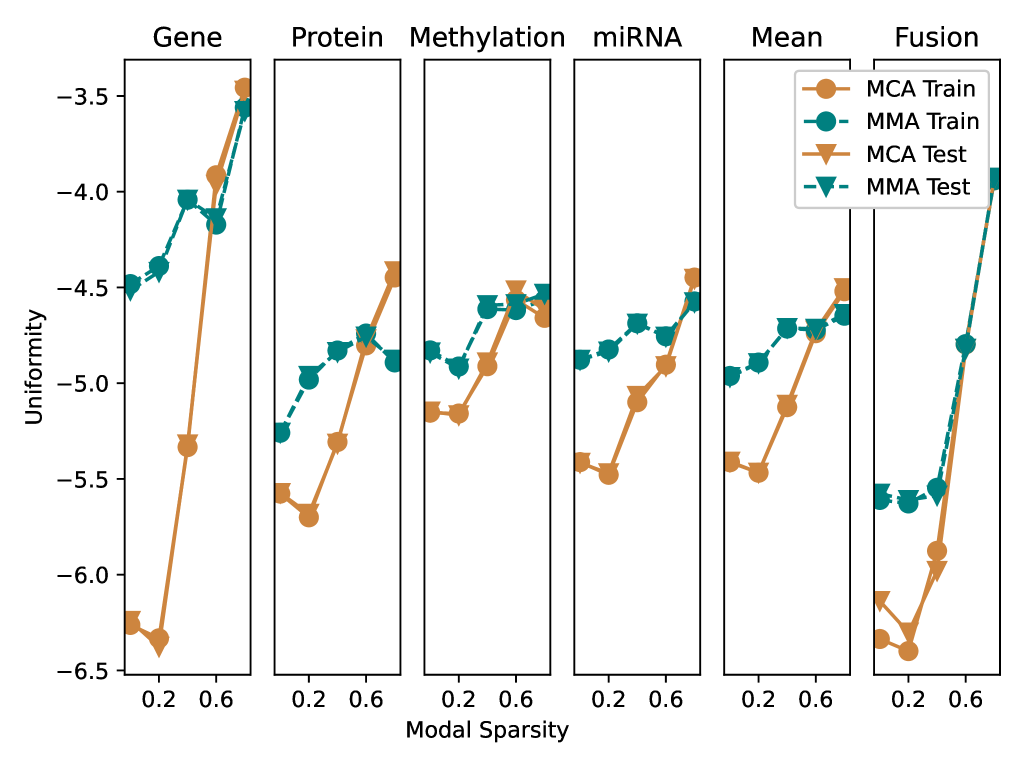
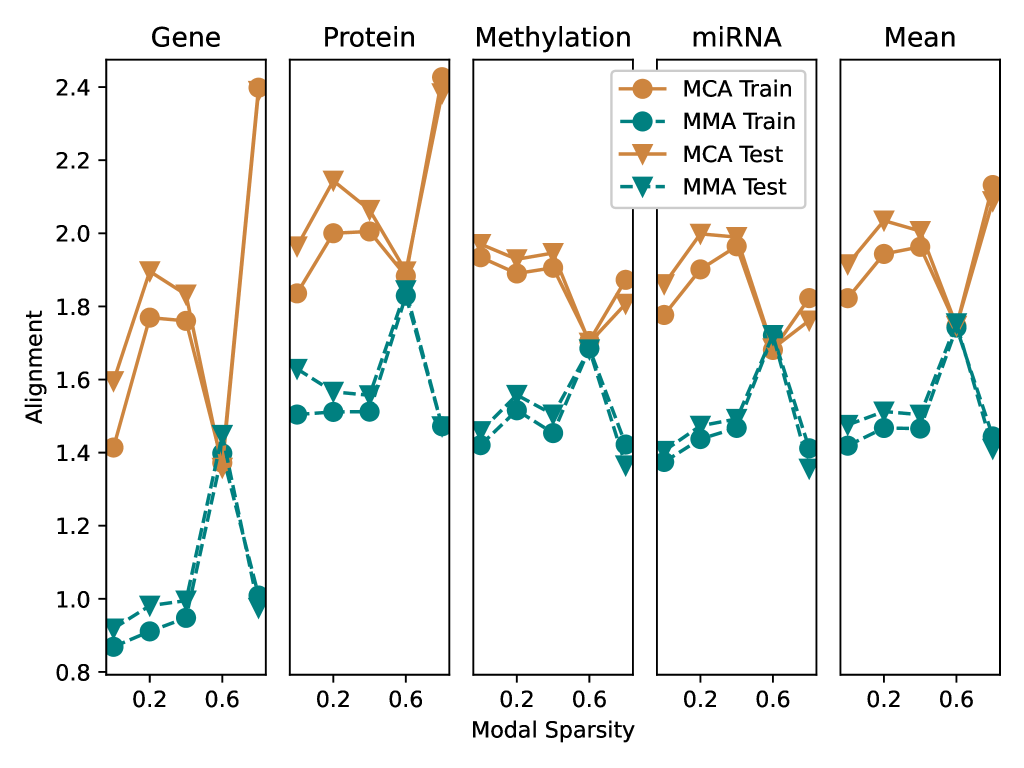
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌀
Data-Efficient Multimodal Fusion on a Single GPU
Noel Vouitsis, Zhaoyan Liu, Satya Krishna Gorti, Valentin Villecroze, Jesse C. Cresswell, Guangwei Yu, Gabriel Loaiza-Ganem, Maksims Volkovs
0
0
The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $sim ! 600times$ fewer GPU days and $sim ! 80times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
4/11/2024
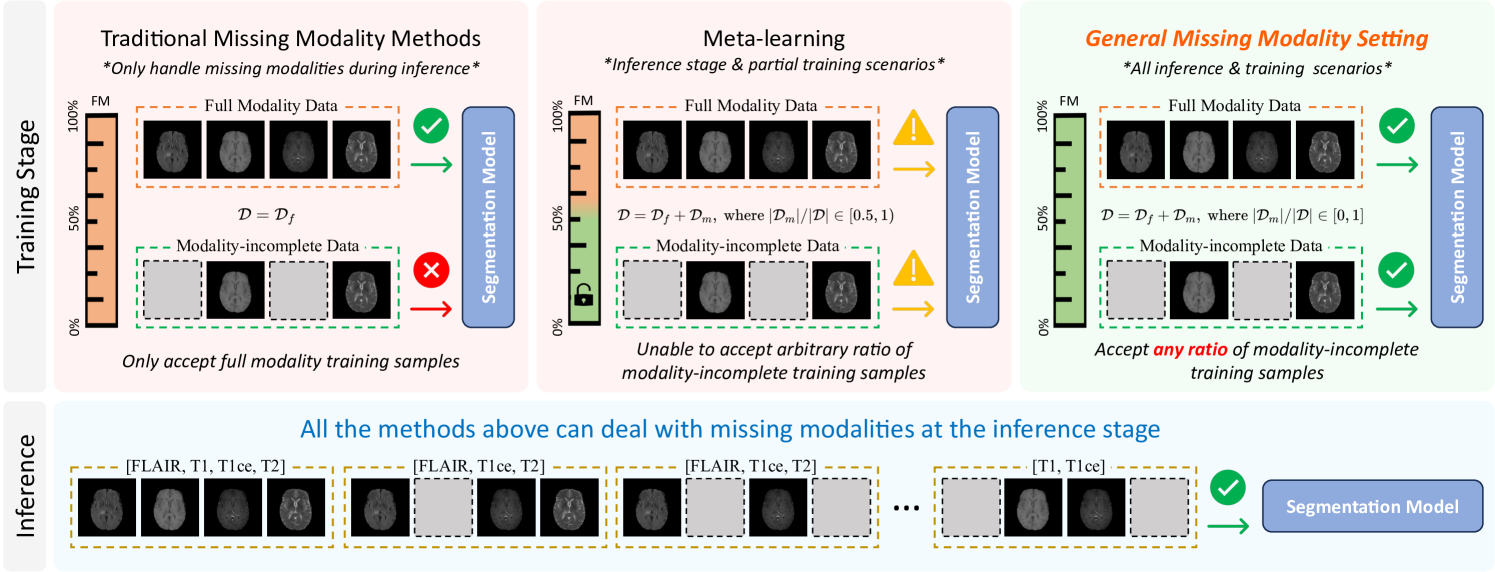
Dealing with All-stage Missing Modality: Towards A Universal Model with Robust Reconstruction and Personalization
Yunpeng Zhao, Cheng Chen, Qing You Pang, Quanzheng Li, Carol Tang, Beng-Ti Ang, Yueming Jin
0
0
Addressing missing modalities presents a critical challenge in multimodal learning. Current approaches focus on developing models that can handle modality-incomplete inputs during inference, assuming that the full set of modalities are available for all the data during training. This reliance on full-modality data for training limits the use of abundant modality-incomplete samples that are often encountered in practical settings. In this paper, we propose a robust universal model with modality reconstruction and model personalization, which can effectively tackle the missing modality at both training and testing stages. Our method leverages a multimodal masked autoencoder to reconstruct the missing modality and masked patches simultaneously, incorporating an innovative distribution approximation mechanism to fully utilize both modality-complete and modality-incomplete data. The reconstructed modalities then contributes to our designed data-model co-distillation scheme to guide the model learning in the presence of missing modalities. Moreover, we propose a CLIP-driven hyper-network to personalize partial model parameters, enabling the model to adapt to each distinct missing modality scenario. Our method has been extensively validated on two brain tumor segmentation benchmarks. Experimental results demonstrate the promising performance of our method, which consistently exceeds previous state-of-the-art approaches under the all-stage missing modality settings with different missing ratios. Code will be available.
6/5/2024
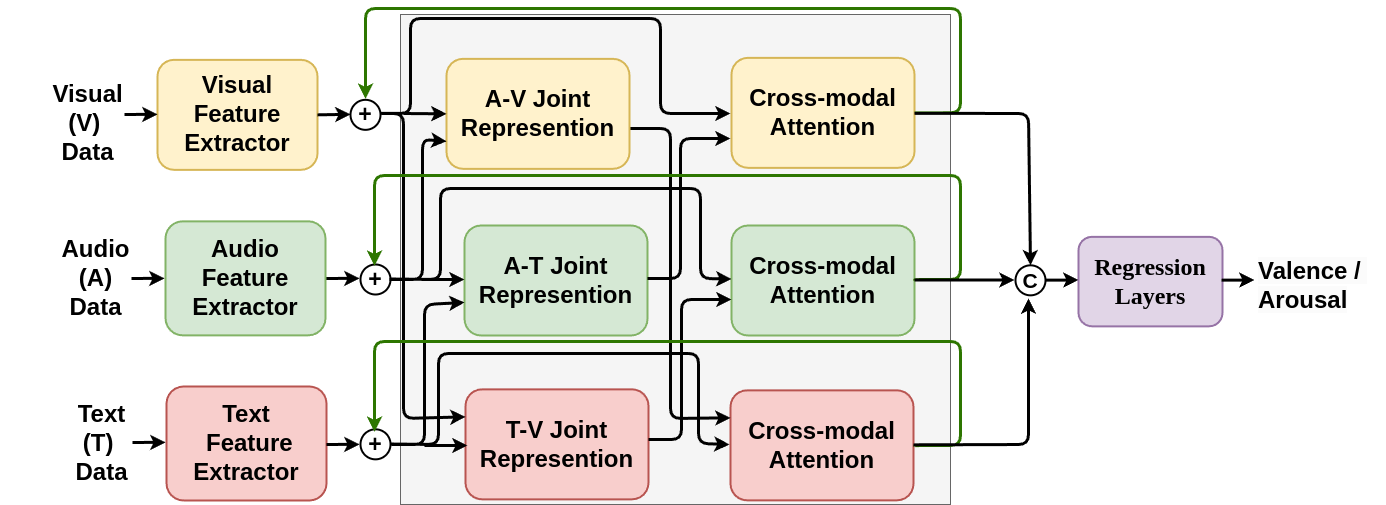
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Jahangir Alam
0
0
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
4/16/2024

Dissecting Multimodality in VideoQA Transformer Models by Impairing Modality Fusion
Ishaan Singh Rawal, Alexander Matyasko, Shantanu Jaiswal, Basura Fernando, Cheston Tan
0
0
While VideoQA Transformer models demonstrate competitive performance on standard benchmarks, the reasons behind their success are not fully understood. Do these models capture the rich multimodal structures and dynamics from video and text jointly? Or are they achieving high scores by exploiting biases and spurious features? Hence, to provide insights, we design $textit{QUAG}$ (QUadrant AveraGe), a lightweight and non-parametric probe, to conduct dataset-model combined representation analysis by impairing modality fusion. We find that the models achieve high performance on many datasets without leveraging multimodal representations. To validate QUAG further, we design $textit{QUAG-attention}$, a less-expressive replacement of self-attention with restricted token interactions. Models with QUAG-attention achieve similar performance with significantly fewer multiplication operations without any finetuning. Our findings raise doubts about the current models' abilities to learn highly-coupled multimodal representations. Hence, we design the $textit{CLAVI}$ (Complements in LAnguage and VIdeo) dataset, a stress-test dataset curated by augmenting real-world videos to have high modality coupling. Consistent with the findings of QUAG, we find that most of the models achieve near-trivial performance on CLAVI. This reasserts the limitations of current models for learning highly-coupled multimodal representations, that is not evaluated by the current datasets (project page: https://dissect-videoqa.github.io ).
6/10/2024