Sparsest Models Elude Pruning: An Expos'e of Pruning's Current Capabilities

0
🔮
Sign in to get full access
Overview
- Pruning is a promising approach for compressing large-scale models
- The effectiveness of pruning in recovering the sparsest models has not been fully explored
- The authors conducted extensive experiments on a synthetic dataset called the Cubist Spiral
- Their findings reveal a significant gap between current pruning algorithms and the performance of ideal sparse networks
Plain English Explanation
Pruning is a technique used to compress large machine learning models by selectively removing parts of the model that are not important. This can make the model smaller and faster to run, which is important for deploying models on devices with limited computing power.
The authors of this paper wanted to see how well pruning could recover the sparsest possible models - models with the fewest parameters. They created a synthetic dataset called the Cubist Spiral and applied a variety of state-of-the-art pruning algorithms to it.
Their results showed that current pruning algorithms struggle to find the optimal sparse structure. Even on this simple dataset, the pruned models performed significantly worse than the ideal sparse networks that the authors identified using a novel search algorithm.
The authors attribute this gap to several issues with current pruning methods, including:
- They don't handle overparameterization well
- They tend to create disconnected paths in the network
- They often get stuck in suboptimal solutions, even when given the optimal model size and initialization.
These findings are concerning because the issues persisted even with simple network architectures and datasets. The authors hope their research will inspire the development of new pruning techniques that can better achieve true network sparsity.
Technical Explanation
The researchers conducted an extensive series of 485,838 experiments, applying a range of state-of-the-art pruning algorithms to a synthetic dataset they created, called the Cubist Spiral. Their goal was to explore the effectiveness of pruning in recovering the sparsest of models.
Through their novel combinatorial search algorithm, the authors were able to identify the optimal sparse networks for their experiments. Comparing the performance of the pruned models to these ideal sparse networks, they found a significant gap in performance.
The authors attribute this gap to several key issues with current pruning algorithms:
-
Poor behavior under overparameterization: The pruning methods struggled to handle the excess parameters in the initial models, leading to suboptimal sparse solutions.
-
Tendency to induce disconnected paths: The pruning process often resulted in sparse networks with disconnected paths, compromising the model's performance.
-
Propensity to get stuck at suboptimal solutions: Even when provided with the optimal width and initialization, the pruning algorithms were unable to consistently find the true optimal sparse structure.
These issues persisted even with the simple network architectures and datasets used in the study, which the authors find concerning. They hope that their research will encourage further investigation into new pruning techniques that can better achieve true network sparsity.
Critical Analysis
The authors make a compelling case for the limitations of current pruning algorithms in recovering the sparsest possible models. Their extensive experimental setup and the use of a novel combinatorial search algorithm to identify the optimal sparse networks provide a strong foundation for their analysis.
One potential caveat is the use of a synthetic dataset, the Cubist Spiral. While this allowed the authors to have greater control over the experimental conditions, it's unclear how well the findings would translate to real-world datasets and tasks. Further research using a broader range of datasets would help validate the generalizability of these insights.
Additionally, the authors acknowledge that the issues they identified persisted even with simple network architectures and datasets. This raises questions about the scalability of these problems and their potential impact on more complex, real-world models. Exploring the behavior of pruning algorithms on larger, more diverse models could yield additional insights.
The authors also note that their research encourages the development of new pruning techniques that can better achieve true network sparsity. Investigating the specific design choices and algorithmic improvements that could address the identified shortcomings would be a valuable next step in this line of research.
Conclusion
This paper provides a thought-provoking exploration of the limitations of current pruning algorithms in recovering the sparsest of models. The authors' extensive experimental findings and the identification of key issues, such as poor handling of overparameterization and the tendency to induce disconnected paths, highlight the need for further advancements in pruning techniques.
By calling attention to these challenges, the researchers hope to inspire the development of new pruning algorithms that can consistently achieve true network sparsity. This could have significant implications for the deployment of large-scale machine learning models on resource-constrained devices, as well as for the broader field of model compression and efficient inference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔮
0
Sparsest Models Elude Pruning: An Expos'e of Pruning's Current Capabilities
Stephen Zhang, Vardan Papyan
Pruning has emerged as a promising approach for compressing large-scale models, yet its effectiveness in recovering the sparsest of models has not yet been explored. We conducted an extensive series of 485,838 experiments, applying a range of state-of-the-art pruning algorithms to a synthetic dataset we created, named the Cubist Spiral. Our findings reveal a significant gap in performance compared to ideal sparse networks, which we identified through a novel combinatorial search algorithm. We attribute this performance gap to current pruning algorithms' poor behaviour under overparameterization, their tendency to induce disconnected paths throughout the network, and their propensity to get stuck at suboptimal solutions, even when given the optimal width and initialization. This gap is concerning, given the simplicity of the network architectures and datasets used in our study. We hope that our research encourages further investigation into new pruning techniques that strive for true network sparsity.
Read more7/8/2024
↗️
0
Pruning is Optimal for Learning Sparse Features in High-Dimensions
Nuri Mert Vural, Murat A. Erdogdu
While it is commonly observed in practice that pruning networks to a certain level of sparsity can improve the quality of the features, a theoretical explanation of this phenomenon remains elusive. In this work, we investigate this by demonstrating that a broad class of statistical models can be optimally learned using pruned neural networks trained with gradient descent, in high-dimensions. We consider learning both single-index and multi-index models of the form $y = sigma^*(boldsymbol{V}^{top} boldsymbol{x}) + epsilon$, where $sigma^*$ is a degree-$p$ polynomial, and $boldsymbol{V} in mathbbm{R}^{d times r}$ with $r ll d$, is the matrix containing relevant model directions. We assume that $boldsymbol{V}$ satisfies a certain $ell_q$-sparsity condition for matrices and show that pruning neural networks proportional to the sparsity level of $boldsymbol{V}$ improves their sample complexity compared to unpruned networks. Furthermore, we establish Correlational Statistical Query (CSQ) lower bounds in this setting, which take the sparsity level of $boldsymbol{V}$ into account. We show that if the sparsity level of $boldsymbol{V}$ exceeds a certain threshold, training pruned networks with a gradient descent algorithm achieves the sample complexity suggested by the CSQ lower bound. In the same scenario, however, our results imply that basis-independent methods such as models trained via standard gradient descent initialized with rotationally invariant random weights can provably achieve only suboptimal sample complexity.
Read more6/14/2024

0
Confident magnitude-based neural network pruning
Joaquin Alvarez
Pruning neural networks has proven to be a successful approach to increase the efficiency and reduce the memory storage of deep learning models without compromising performance. Previous literature has shown that it is possible to achieve a sizable reduction in the number of parameters of a deep neural network without deteriorating its predictive capacity in one-shot pruning regimes. Our work builds beyond this background in order to provide rigorous uncertainty quantification for pruning neural networks reliably, which has not been addressed to a great extent in previous literature focusing on pruning methods in computer vision settings. We leverage recent techniques on distribution-free uncertainty quantification to provide finite-sample statistical guarantees to compress deep neural networks, while maintaining high performance. Moreover, this work presents experiments in computer vision tasks to illustrate how uncertainty-aware pruning is a useful approach to deploy sparse neural networks safely.
Read more8/12/2024
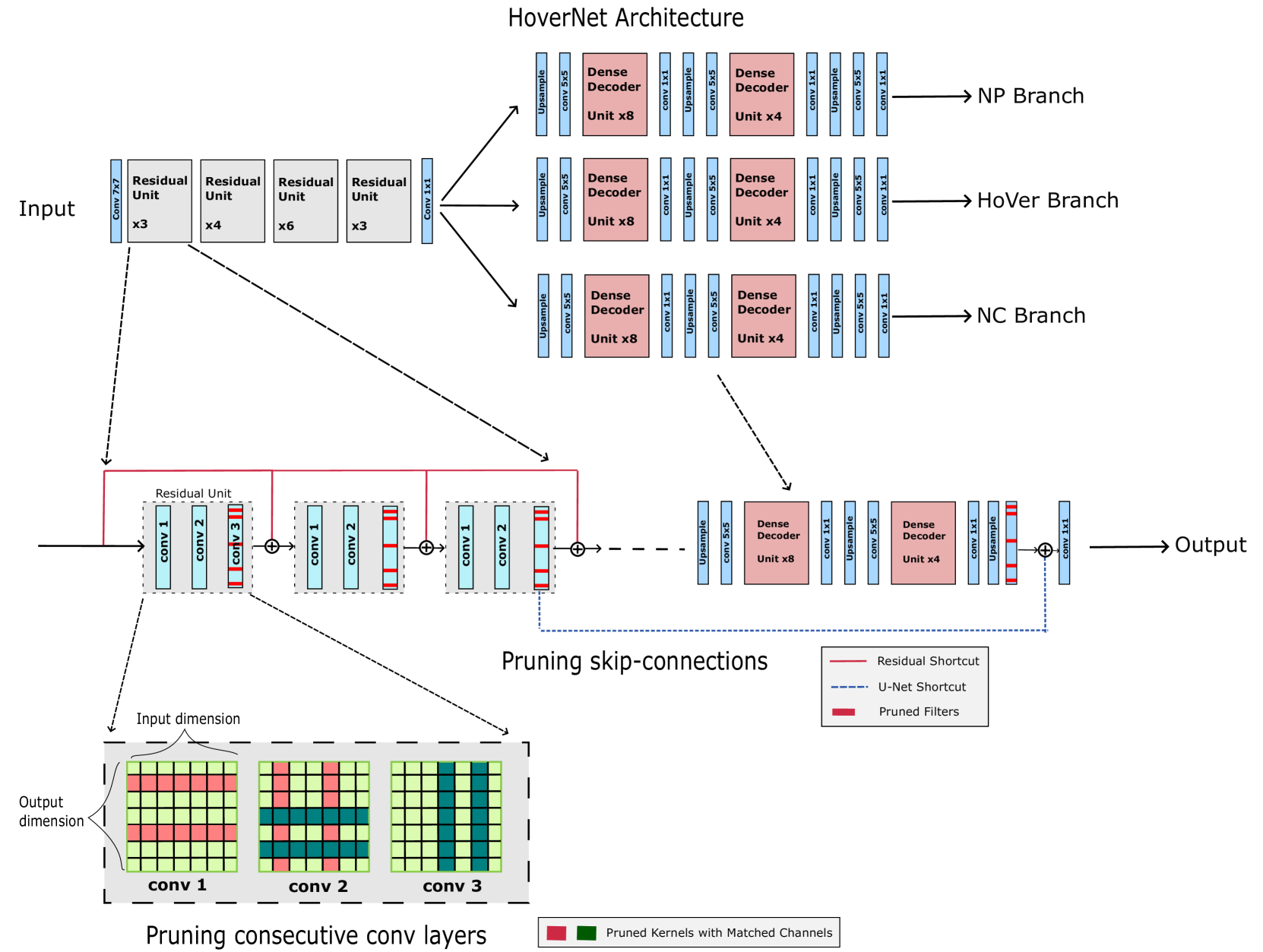
0
Structured Model Pruning for Efficient Inference in Computational Pathology
Mohammed Adnan, Qinle Ba, Nazim Shaikh, Shivam Kalra, Satarupa Mukherjee, Auranuch Lorsakul
Recent years have seen significant efforts to adopt Artificial Intelligence (AI) in healthcare for various use cases, from computer-aided diagnosis to ICU triage. However, the size of AI models has been rapidly growing due to scaling laws and the success of foundational models, which poses an increasing challenge to leverage advanced models in practical applications. It is thus imperative to develop efficient models, especially for deploying AI solutions under resource-constrains or with time sensitivity. One potential solution is to perform model compression, a set of techniques that remove less important model components or reduce parameter precision, to reduce model computation demand. In this work, we demonstrate that model pruning, as a model compression technique, can effectively reduce inference cost for computational and digital pathology based analysis with a negligible loss of analysis performance. To this end, we develop a methodology for pruning the widely used U-Net-style architectures in biomedical imaging, with which we evaluate multiple pruning heuristics on nuclei instance segmentation and classification, and empirically demonstrate that pruning can compress models by at least 70% with a negligible drop in performance.
Read more4/16/2024