Towards Generalized Entropic Sparsification for Convolutional Neural Networks
2404.04734
0
0
Abstract
Convolutional neural networks (CNNs) are reported to be overparametrized. The search for optimal (minimal) and sufficient architecture is an NP-hard problem as the hyperparameter space for possible network configurations is vast. Here, we introduce a layer-by-layer data-driven pruning method based on the mathematical idea aiming at a computationally-scalable entropic relaxation of the pruning problem. The sparse subnetwork is found from the pre-trained (full) CNN using the network entropy minimization as a sparsity constraint. This allows deploying a numerically scalable algorithm with a sublinear scaling cost. The method is validated on several benchmarks (architectures): (i) MNIST (LeNet) with sparsity 55%-84% and loss in accuracy 0.1%-0.5%, and (ii) CIFAR-10 (VGG-16, ResNet18) with sparsity 73-89% and loss in accuracy 0.1%-0.5%.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a novel approach to sparsifying convolutional neural networks (CNNs) called "Generalized Entropic Sparsification."
- The key idea is to use an information-theoretic measure called "generalized entropy" to identify and remove redundant connections in CNN architectures.
- The authors demonstrate that this method can significantly reduce the model size and computation requirements of CNNs without significantly impacting their performance.
Plain English Explanation
Convolutional neural networks (CNNs) are a powerful type of machine learning model that have revolutionized fields like computer vision and natural language processing. However, CNNs can be very large and computationally intensive, making them difficult to deploy on resource-constrained devices like smartphones or embedded systems.
This paper introduces a new technique called "Generalized Entropic Sparsification" that can help address this issue. The core insight is to use a information-theoretic concept called "generalized entropy" to identify and remove unnecessary connections in the CNN architecture. Intuitively, this allows the model to discard parts of its internal structure that don't contribute much to its overall performance, resulting in a smaller and more efficient model.
The authors demonstrate that their approach can significantly reduce the size and computational requirements of CNNs without sacrificing too much accuracy. This could have important practical implications, enabling the deployment of powerful AI models on a wider range of devices and applications.
Technical Explanation
The paper begins by providing background on the use of entropy and information theory in machine learning. The authors note that entropy-based measures have previously been used for network pruning and accelerating CNN inference. However, they argue that existing approaches are limited in their flexibility and generalization.
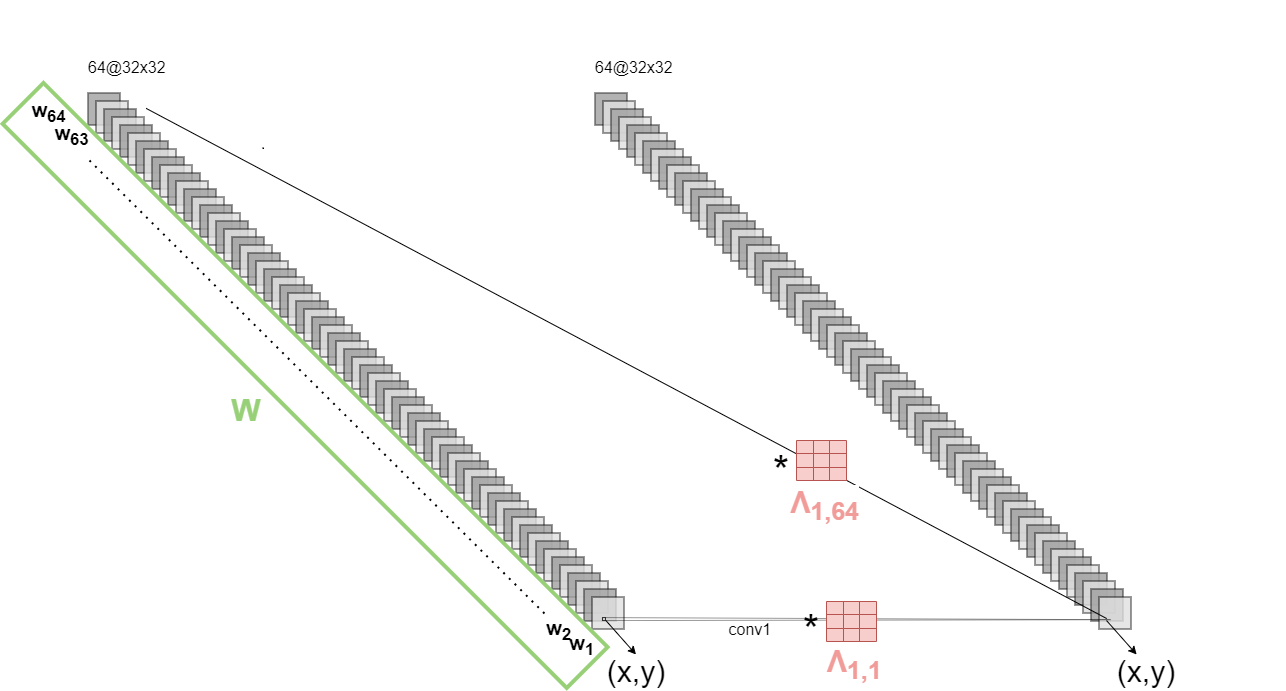
To address these limitations, the authors propose a new framework called "Generalized Entropic Sparsification." This method leverages a generalization of Shannon entropy, known as Rényi entropy, to identify and remove redundant connections in CNN architectures. The key advantage of Rényi entropy is that it can capture different notions of information content by tuning a single parameter.
The paper presents a detailed algorithm for applying Generalized Entropic Sparsification to CNNs. This includes techniques for computing the Rényi entropy of individual convolutional filters and using this to selectively prune connections. The authors also discuss how to fine-tune the pruned model to recover any lost performance.
Extensive experiments are conducted on various CNN architectures and datasets, including ImageNet and CIFAR-10. The results demonstrate that Generalized Entropic Sparsification can achieve significant model size and computation reductions (up to 90%) with only minor accuracy degradation (1-2%).
Critical Analysis
The paper makes a compelling case for the effectiveness of Generalized Entropic Sparsification as a technique for compressing and accelerating CNNs. The authors provide a solid theoretical foundation and rigorous experimental validation of their approach.
One potential limitation is that the method relies on tuning a parameter (the order of the Rényi entropy) to control the tradeoff between sparsity and accuracy. In practice, this may require some trial-and-error to find the optimal setting for a given model and task. The authors acknowledge this and suggest using a multi-objective optimization approach to automate this process.
Additionally, the paper focuses primarily on computer vision tasks. It would be interesting to see how well Generalized Entropic Sparsification performs on other domains, such as natural language processing or speech recognition. The underlying principles should be applicable, but the specific tradeoffs and hyperparameter settings may differ.
Overall, this paper presents a novel and promising approach to CNN model compression that could have significant real-world impact. The authors have made a valuable contribution to the ongoing efforts to make deep learning more efficient and deployable.
Conclusion
This paper introduces a new technique called "Generalized Entropic Sparsification" that can dramatically reduce the size and computational requirements of convolutional neural networks without sacrificing too much performance. By leveraging the concept of generalized entropy, the method is able to identify and prune redundant connections in CNN architectures in a principled, information-theoretic way.
The authors demonstrate the effectiveness of their approach through extensive experiments, showing that it can achieve up to 90% model compression with only minor accuracy degradation. This could enable the deployment of powerful AI models on a wider range of resource-constrained devices, opening up new possibilities for real-world applications of deep learning.
Overall, this paper represents an important step forward in the ongoing quest to make deep learning more efficient and accessible. The ideas and techniques presented here could have far-reaching implications for the field of machine learning as a whole.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
NEPENTHE: Entropy-Based Pruning as a Neural Network Depth's Reducer
Zhu Liao, Victor Qu'etu, Van-Tam Nguyen, Enzo Tartaglione
0
0
While deep neural networks are highly effective at solving complex tasks, their computational demands can hinder their usefulness in real-time applications and with limited-resources systems. Besides, for many tasks it is known that these models are over-parametrized: neoteric works have broadly focused on reducing the width of these networks, rather than their depth. In this paper, we aim to reduce the depth of over-parametrized deep neural networks: we propose an eNtropy-basEd Pruning as a nEural Network depTH's rEducer (NEPENTHE) to alleviate deep neural networks' computational burden. Based on our theoretical finding, NEPENTHE focuses on un-structurally pruning connections in layers with low entropy to remove them entirely. We validate our approach on popular architectures such as MobileNet and Swin-T, showing that when encountering an over-parametrization regime, it can effectively linearize some layers (hence reducing the model's depth) with little to no performance loss. The code will be publicly available upon acceptance of the article.
4/29/2024
Iterative Filter Pruning for Concatenation-based CNN Architectures
Svetlana Pavlitska, Oliver Bagge, Federico Peccia, Toghrul Mammadov, J. Marius Zollner
0
0
Model compression and hardware acceleration are essential for the resource-efficient deployment of deep neural networks. Modern object detectors have highly interconnected convolutional layers with concatenations. In this work, we study how pruning can be applied to such architectures, exemplary for YOLOv7. We propose a method to handle concatenation layers, based on the connectivity graph of convolutional layers. By automating iterative sensitivity analysis, pruning, and subsequent model fine-tuning, we can significantly reduce model size both in terms of the number of parameters and FLOPs, while keeping comparable model accuracy. Finally, we deploy pruned models to FPGA and NVIDIA Jetson Xavier AGX. Pruned models demonstrate a 2x speedup for the convolutional layers in comparison to the unpruned counterparts and reach real-time capability with 14 FPS on FPGA. Our code is available at https://github.com/fzi-forschungszentrum-informatik/iterative-yolo-pruning.
5/8/2024
NeuroPrune: A Neuro-inspired Topological Sparse Training Algorithm for Large Language Models
Amit Dhurandhar, Tejaswini Pedapati, Ronny Luss, Soham Dan, Aurelie Lozano, Payel Das, Georgios Kollias
0
0
Transformer-based Language Models have become ubiquitous in Natural Language Processing (NLP) due to their impressive performance on various tasks. However, expensive training as well as inference remains a significant impediment to their widespread applicability. While enforcing sparsity at various levels of the model architecture has found promise in addressing scaling and efficiency issues, there remains a disconnect between how sparsity affects network topology. Inspired by brain neuronal networks, we explore sparsity approaches through the lens of network topology. Specifically, we exploit mechanisms seen in biological networks, such as preferential attachment and redundant synapse pruning, and show that principled, model-agnostic sparsity approaches are performant and efficient across diverse NLP tasks, spanning both classification (such as natural language inference) and generation (summarization, machine translation), despite our sole objective not being optimizing performance. NeuroPrune is competitive with (or sometimes superior to) baselines on performance and can be up to $10$x faster in terms of training time for a given level of sparsity, simultaneously exhibiting measurable improvements in inference time in many cases.
4/10/2024
🗣️
Improving the interpretability of GNN predictions through conformal-based graph sparsification
Pablo Sanchez-Martin, Kinaan Aamir Khan, Isabel Valera
0
0
Graph Neural Networks (GNNs) have achieved state-of-the-art performance in solving graph classification tasks. However, most GNN architectures aggregate information from all nodes and edges in a graph, regardless of their relevance to the task at hand, thus hindering the interpretability of their predictions. In contrast to prior work, in this paper we propose a GNN emph{training} approach that jointly i) finds the most predictive subgraph by removing edges and/or nodes -- -emph{without making assumptions about the subgraph structure} -- while ii) optimizing the performance of the graph classification task. To that end, we rely on reinforcement learning to solve the resulting bi-level optimization with a reward function based on conformal predictions to account for the current in-training uncertainty of the classifier. Our empirical results on nine different graph classification datasets show that our method competes in performance with baselines while relying on significantly sparser subgraphs, leading to more interpretable GNN-based predictions.
4/19/2024