Spatio-Temporal Side Tuning Pre-trained Foundation Models for Video-based Pedestrian Attribute Recognition
2404.17929
0
0
👁️
Abstract
Existing pedestrian attribute recognition (PAR) algorithms are mainly developed based on a static image, however, the performance is unreliable in challenging scenarios, such as heavy occlusion, motion blur, etc. In this work, we propose to understand human attributes using video frames that can fully use temporal information by fine-tuning a pre-trained multi-modal foundation model efficiently. Specifically, we formulate the video-based PAR as a vision-language fusion problem and adopt a pre-trained foundation model CLIP to extract the visual features. More importantly, we propose a novel spatiotemporal side-tuning strategy to achieve parameter-efficient optimization of the pre-trained vision foundation model. To better utilize the semantic information, we take the full attribute list that needs to be recognized as another input and transform the attribute words/phrases into the corresponding sentence via split, expand, and prompt operations. Then, the text encoder of CLIP is utilized for embedding processed attribute descriptions. The averaged visual tokens and text tokens are concatenated and fed into a fusion Transformer for multi-modal interactive learning. The enhanced tokens will be fed into a classification head for pedestrian attribute prediction. Extensive experiments on two large-scale video-based PAR datasets fully validated the effectiveness of our proposed framework. The source code of this paper is available at https://github.com/Event-AHU/OpenPAR.
Create account to get full access
Overview
- Existing pedestrian attribute recognition (PAR) algorithms are mainly based on static images, which can be unreliable in challenging scenarios like heavy occlusion or motion blur.
- This work proposes a video-based PAR approach that can leverage temporal information by fine-tuning a pre-trained multi-modal foundation model.
- The proposed method formulates video-based PAR as a vision-language fusion problem, using CLIP to extract visual features and a novel spatiotemporal side-tuning strategy for parameter-efficient optimization.
- The full attribute list is used as input, with the attribute words/phrases transformed into corresponding sentences to better utilize semantic information.
- Extensive experiments on two large-scale video-based PAR datasets validate the effectiveness of the proposed framework.
Plain English Explanation
Pedestrian attribute recognition (PAR) is the task of identifying characteristics like age, gender, or clothing of people in images or videos. Existing PAR algorithms work well on static images but can struggle in more challenging scenarios, like when people are partially blocked from view or the image is blurry due to motion.
This research proposes a new approach that uses video frames instead of just static images. By looking at multiple frames over time, the system can better understand the attributes of pedestrians, even in difficult situations. The key innovation is how the researchers leverage a powerful AI model called CLIP that has been pre-trained on a large amount of visual and text data.
The researchers first extract visual features from the video frames using CLIP. Then, they have a clever way of also incorporating information about the specific attributes that need to be recognized. They convert the attribute names into full sentences and use CLIP's language model to get embeddings for those as well. The visual and language features are combined and fed into a neural network that learns to predict the pedestrian attributes.
Importantly, the researchers use a special 'side-tuning' technique to fine-tune the pre-trained CLIP model efficiently, without having to retrain the entire model from scratch. This makes the approach more practical to use.
The researchers tested their method on two large datasets of video-based pedestrian attributes, and the results show it performs significantly better than previous approaches. This demonstrates the power of leveraging pre-trained models and video data to tackle challenging computer vision problems like pedestrian recognition.
Technical Explanation
The key contributions of this work are:
- Formulating video-based PAR as a vision-language fusion problem: The researchers use CLIP, a pre-trained multi-modal foundation model, to extract visual features from video frames and text features from the full attribute list.
- Proposing a novel spatiotemporal side-tuning strategy: Instead of fully retraining the entire CLIP model, the researchers introduce a parameter-efficient optimization approach that fine-tunes the pre-trained vision foundation model.
- Leveraging semantic information by transforming attribute words/phrases into corresponding sentences through split, expand, and prompt operations, and using the text encoder of CLIP to embed the processed attribute descriptions.
- Fusing the averaged visual and text tokens in a Transformer for multi-modal interactive learning, with the enhanced tokens fed into a classification head for final pedestrian attribute prediction.
The overall framework first extracts visual features from video frames using the CLIP vision encoder. Meanwhile, the full attribute list is processed into corresponding sentences, which are then encoded by the CLIP text encoder. The visual and text features are concatenated and fed into a fusion Transformer, which learns to combine the modalities for accurate pedestrian attribute prediction.
The key innovation is the spatiotemporal side-tuning strategy, which allows efficient fine-tuning of the pre-trained CLIP vision model instead of retraining the entire foundation model from scratch. This makes the approach more practical and scalable.
Extensive experiments on two large-scale video-based PAR datasets, PETA and VISUEL, demonstrate the effectiveness of the proposed framework, outperforming previous state-of-the-art methods.
Critical Analysis
While the proposed video-based PAR approach shows promising results, there are a few areas that could be further explored:
-
Generalization to other foundation models: The framework currently relies on the CLIP model, but it would be interesting to see if it can generalize to other pre-trained multi-modal models, such as HawkEye or VQ-VAE, to assess the broader applicability of the method.
-
Robustness to diverse datasets: The experiments were conducted on two large-scale video-based PAR datasets, but it would be valuable to evaluate the framework's performance on a more diverse range of datasets, including those with different cultural or contextual backgrounds, to ensure its generalizability.
-
Interpretability and explainability: While the model demonstrates strong predictive performance, it would be beneficial to provide more insight into how the system makes its decisions, especially when dealing with challenging scenarios like occlusion or motion blur. Incorporating interpretability could help build trust and understanding in the model's outputs.
-
Ethical considerations: Pedestrian attribute recognition systems can raise privacy and bias concerns, as they have the potential to be used for surveillance or discrimination. The researchers should address these ethical implications and discuss potential mitigation strategies.
Overall, this work presents a promising approach to video-based pedestrian attribute recognition, leveraging pre-trained multi-modal models and novel fine-tuning techniques. Further research to address the identified areas could strengthen the framework and contribute to more robust and responsible computer vision systems.
Conclusion
This research proposes a video-based pedestrian attribute recognition (PAR) framework that effectively leverages temporal information and a pre-trained multi-modal foundation model. By formulating the problem as a vision-language fusion task and introducing a novel spatiotemporal side-tuning strategy, the approach demonstrates significant performance improvements over existing static image-based PAR methods.
The key innovations include using CLIP to extract visual and text features, incorporating semantic information about the target attributes, and efficiently fine-tuning the pre-trained vision model. Extensive experiments on large-scale video-based PAR datasets validate the effectiveness of the proposed framework.
While the results are promising, future work should explore the generalization to other foundation models, the robustness to diverse datasets, the interpretability of the system's decision-making, and the ethical implications of deploying such technology. Overall, this research represents an important step forward in developing more accurate and reliable pedestrian attribute recognition systems, with potential applications in areas like surveillance, security, and urban planning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Attribute-Aware Implicit Modality Alignment for Text Attribute Person Search
Xin Wang, Fangfang Liu, Zheng Li, Caili Guo
0
0
Text attribute person search aims to find specific pedestrians through given textual attributes, which is very meaningful in the scene of searching for designated pedestrians through witness descriptions. The key challenge is the significant modality gap between textual attributes and images. Previous methods focused on achieving explicit representation and alignment through unimodal pre-trained models. Nevertheless, the absence of inter-modality correspondence in these models may lead to distortions in the local information of intra-modality. Moreover, these methods only considered the alignment of inter-modality and ignored the differences between different attribute categories. To mitigate the above problems, we propose an Attribute-Aware Implicit Modality Alignment (AIMA) framework to learn the correspondence of local representations between textual attributes and images and combine global representation matching to narrow the modality gap. Firstly, we introduce the CLIP model as the backbone and design prompt templates to transform attribute combinations into structured sentences. This facilitates the model's ability to better understand and match image details. Next, we design a Masked Attribute Prediction (MAP) module that predicts the masked attributes after the interaction of image and masked textual attribute features through multi-modal interaction, thereby achieving implicit local relationship alignment. Finally, we propose an Attribute-IoU Guided Intra-Modal Contrastive (A-IoU IMC) loss, aligning the distribution of different textual attributes in the embedding space with their IoU distribution, achieving better semantic arrangement. Extensive experiments on the Market-1501 Attribute, PETA, and PA100K datasets show that the performance of our proposed method significantly surpasses the current state-of-the-art methods.
6/7/2024

The Solution for the CVPR 2023 1st foundation model challenge-Track2
Haonan Xu, Yurui Huang, Sishun Pan, Zhihao Guan, Yi Xu, Yang Yang
0
0
In this paper, we propose a solution for cross-modal transportation retrieval. Due to the cross-domain problem of traffic images, we divide the problem into two sub-tasks of pedestrian retrieval and vehicle retrieval through a simple strategy. In pedestrian retrieval tasks, we use IRRA as the base model and specifically design an Attribute Classification to mine the knowledge implied by attribute labels. More importantly, We use the strategy of Inclusion Relation Matching to make the image-text pairs with inclusion relation have similar representation in the feature space. For the vehicle retrieval task, we use BLIP as the base model. Since aligning the color attributes of vehicles is challenging, we introduce attribute-based object detection techniques to add color patch blocks to vehicle images for color data augmentation. This serves as strong prior information, helping the model perform the image-text alignment. At the same time, we incorporate labeled attributes into the image-text alignment loss to learn fine-grained alignment and prevent similar images and texts from being incorrectly separated. Our approach ranked first in the final B-board test with a score of 70.9.
4/3/2024

Pedestrian Attribute Recognition as Label-balanced Multi-label Learning
Yibo Zhou, Hai-Miao Hu, Yirong Xiang, Xiaokang Zhang, Haotian Wu
0
0
Rooting in the scarcity of most attributes, realistic pedestrian attribute datasets exhibit unduly skewed data distribution, from which two types of model failures are delivered: (1) label imbalance: model predictions lean greatly towards the side of majority labels; (2) semantics imbalance: model is easily overfitted on the under-represented attributes due to their insufficient semantic diversity. To render perfect label balancing, we propose a novel framework that successfully decouples label-balanced data re-sampling from the curse of attributes co-occurrence, i.e., we equalize the sampling prior of an attribute while not biasing that of the co-occurred others. To diversify the attributes semantics and mitigate the feature noise, we propose a Bayesian feature augmentation method to introduce true in-distribution novelty. Handling both imbalances jointly, our work achieves best accuracy on various popular benchmarks, and importantly, with minimal computational budget.
5/9/2024
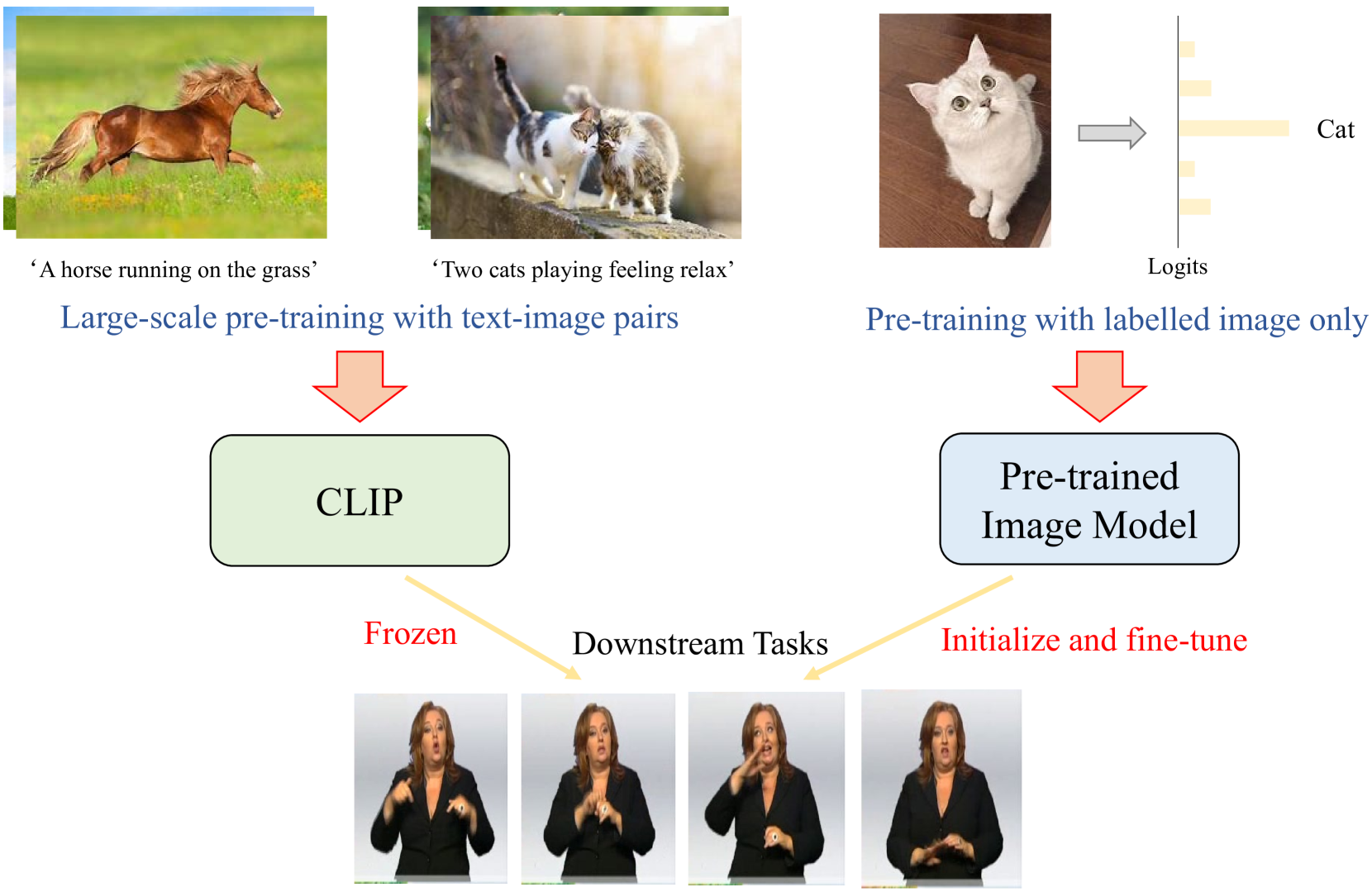
Improving Continuous Sign Language Recognition with Adapted Image Models
Lianyu Hu, Tongkai Shi, Liqing Gao, Zekang Liu, Wei Feng
0
0
The increase of web-scale weakly labelled image-text pairs have greatly facilitated the development of large-scale vision-language models (e.g., CLIP), which have shown impressive generalization performance over a series of downstream tasks. However, the massive model size and scarcity of available data limit their applications to fine-tune the whole model in downstream tasks. Besides, fully fine-tuning the model easily forgets the generic essential knowledge acquired in the pretraining stage and overfits the downstream data. To enable high efficiency when adapting these large vision-language models (e.g., CLIP) to performing continuous sign language recognition (CSLR) while preserving their generalizability, we propose a novel strategy (AdaptSign). Especially, CLIP is adopted as the visual backbone to extract frame-wise features whose parameters are fixed, and a set of learnable modules are introduced to model spatial sign variations or capture temporal sign movements. The introduced additional modules are quite lightweight, only owning 3.2% extra computations with high efficiency. The generic knowledge acquired in the pretraining stage is well-preserved in the frozen CLIP backbone in this process. Extensive experiments show that despite being efficient, AdaptSign is able to demonstrate superior performance across a series of CSLR benchmarks including PHOENIX14, PHOENIX14-T, CSL-Daily and CSL compared to existing methods. Visualizations show that AdaptSign could learn to dynamically pay major attention to the informative spatial regions and cross-frame trajectories in sign videos.
4/15/2024