Speaker Adaptation for Quantised End-to-End ASR Models

0
👀
Sign in to get full access
Overview
- This paper explores speaker adaptation techniques for end-to-end automatic speech recognition (ASR) models that use vector quantization.
- The researchers propose a method to adapt the quantization codebook to individual speakers, improving the model's performance on speaker-specific data.
- The paper presents experiments on various datasets, demonstrating the effectiveness of the proposed speaker adaptation approach.
Plain English Explanation
The paper focuses on improving the performance of speech recognition models, specifically those that use a technique called vector quantization. Vector quantization is a way of compressing the audio data by representing it with a small set of representative values, or "codes."
The researchers found that these quantized speech recognition models struggled to handle variations in speakers' voices and accents. To address this, they developed a method to "adapt" the set of codes used by the model to better fit the characteristics of individual speakers.
By adapting the codebook to each speaker, the model was able to better capture the unique aspects of that speaker's voice. This led to improved speech recognition accuracy when the model was applied to data from that specific speaker.
The researchers tested their speaker adaptation approach on several different speech recognition datasets and found that it consistently outperformed the standard, non-adapted models. This suggests that their technique could be a valuable tool for improving the real-world performance of speech recognition systems, especially in scenarios where they need to work with diverse speakers.
Technical Explanation
The paper introduces a speaker adaptation technique for end-to-end automatic speech recognition (ASR) models that use vector quantization. The core idea is to adapt the quantization codebook to individual speakers, allowing the model to better capture speaker-specific characteristics.
Vector quantization is used to compress the acoustic features extracted from the input audio. The model learns a set of "code vectors" that represent common patterns in the features. During inference, the input features are mapped to the closest code vector, and this discrete representation is then processed by the downstream ASR model.
The researchers propose a speaker adaptation method that fine-tunes the codebook after the initial model training. They add a speaker-dependent linear layer that projects the shared codebook to a speaker-specific one, and then fine-tune this adaptation layer on speaker-specific data.
Experiments are conducted on several datasets, including LibriSpeech, CommonVoice, and AISHELL-1. The results show that the speaker-adapted models significantly outperform the baseline non-adapted models, demonstrating the effectiveness of the proposed technique.
The paper also explores the impact of different codebook sizes and the trade-offs between model size, inference speed, and recognition accuracy. The authors find that smaller codebooks can achieve competitive performance while being more computationally efficient.
Critical Analysis
The paper presents a novel and well-designed approach to improving the performance of quantized end-to-end ASR models through speaker adaptation. The proposed method is straightforward to implement and the experimental results are convincing.
One potential limitation, as mentioned in the paper, is that the speaker adaptation process requires some amount of speaker-specific data, which may not always be available in real-world scenarios. The researchers suggest that techniques like few-shot adaptation could be investigated to address this.
Additionally, the paper focuses on a specific type of ASR model architecture (quantized end-to-end) and does not explore the applicability of the speaker adaptation approach to other model types, such as hybrid ASR systems. Further research could investigate the generalizability of the technique to a wider range of ASR architectures.
Another area for potential exploration is the interaction between speaker adaptation and other techniques, such as data augmentation or meta-learning, that could further enhance the model's ability to handle speaker variability.
Overall, the paper makes a valuable contribution to the field of speech recognition by demonstrating an effective method for improving the performance of quantized ASR models through speaker adaptation. The insights and techniques presented could be leveraged to build more robust and versatile speech recognition systems.
Conclusion
This paper introduces a speaker adaptation technique for quantized end-to-end automatic speech recognition models. By fine-tuning the quantization codebook to individual speakers, the researchers were able to significantly improve the models' performance on speaker-specific data.
The proposed method is shown to be effective across multiple datasets, outperforming baseline non-adapted models. This suggests that speaker adaptation could be a valuable tool for deploying speech recognition systems in real-world scenarios with diverse speakers.
The paper also explores the trade-offs between model size, inference speed, and recognition accuracy, finding that smaller codebooks can achieve competitive performance while being more computationally efficient.
Overall, this research represents an important step forward in enhancing the flexibility and robustness of end-to-end speech recognition systems, with potential applications in a wide range of voice-based technologies and services.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
0
Speaker Adaptation for Quantised End-to-End ASR Models
Qiuming Zhao, Guangzhi Sun, Chao Zhang, Mingxing Xu, Thomas Fang Zheng
End-to-end models have shown superior performance for automatic speech recognition (ASR). However, such models are often very large in size and thus challenging to deploy on resource-constrained edge devices. While quantisation can reduce model sizes, it can lead to increased word error rates (WERs). Although improved quantisation methods were proposed to address the issue of performance degradation, the fact that quantised models deployed on edge devices often target only on a small group of users is under-explored. To this end, we propose personalisation for quantised models (P4Q), a novel strategy that uses speaker adaptation (SA) to improve quantised end-to-end ASR models by fitting them to the characteristics of the target speakers. In this paper, we study the P4Q strategy based on Whisper and Conformer attention-based encoder-decoder (AED) end-to-end ASR models, which leverages a 4-bit block-wise NormalFloat4 (NF4) approach for quantisation and the low-rank adaptation (LoRA) approach for SA. Experimental results on the LibriSpeech and the TED-LIUM 3 corpora show that, with a 7-time reduction in model size and 1% extra speaker-specific parameters, 15.1% and 23.3% relative WER reductions were achieved on quantised Whisper and Conformer AED models respectively, comparing to the full precision models.
Read more8/9/2024
0
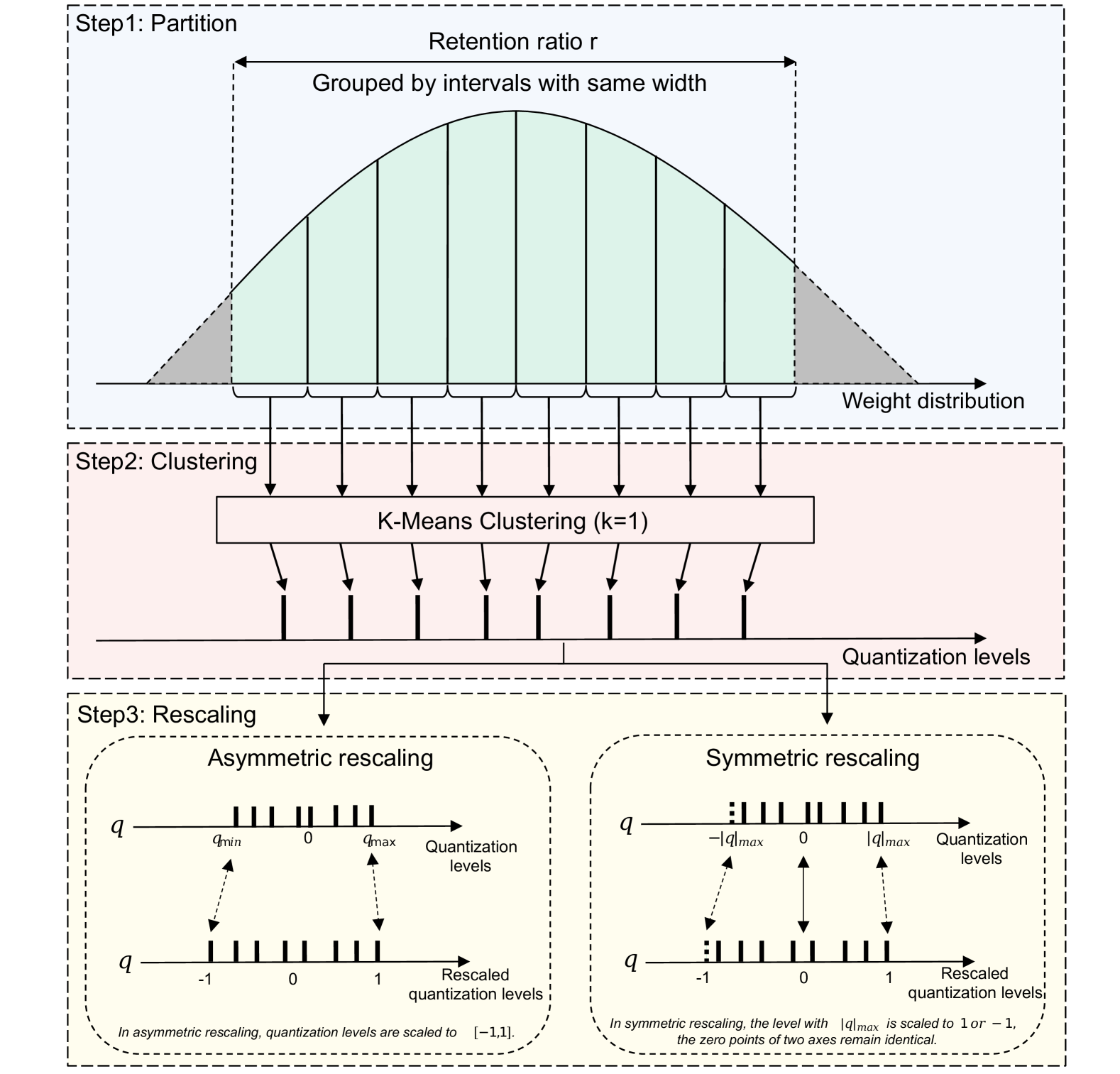
Towards Lightweight Speaker Verification via Adaptive Neural Network Quantization
Bei Liu, Haoyu Wang, Yanmin Qian
Modern speaker verification (SV) systems typically demand expensive storage and computing resources, thereby hindering their deployment on mobile devices. In this paper, we explore adaptive neural network quantization for lightweight speaker verification. Firstly, we propose a novel adaptive uniform precision quantization method which enables the dynamic generation of quantization centroids customized for each network layer based on k-means clustering. By applying it to the pre-trained SV systems, we obtain a series of quantized variants with different bit widths. To enhance the performance of low-bit quantized models, a mixed precision quantization algorithm along with a multi-stage fine-tuning (MSFT) strategy is further introduced. Unlike uniform precision quantization, mixed precision approach allows for the assignment of varying bit widths to different network layers. When bit combination is determined, MSFT is employed to progressively quantize and fine-tune network in a specific order. Finally, we design two distinct binary quantization schemes to mitigate performance degradation of 1-bit quantized models: the static and adaptive quantizers. Experiments on VoxCeleb demonstrate that lossless 4-bit uniform precision quantization is achieved on both ResNets and DF-ResNets, yielding a promising compression ratio of around 8. Moreover, compared to uniform precision approach, mixed precision quantization not only obtains additional performance improvements with a similar model size but also offers the flexibility to generate bit combination for any desirable model size. In addition, our suggested 1-bit quantization schemes remarkably boost the performance of binarized models. Finally, a thorough comparison with existing lightweight SV systems reveals that our proposed models outperform all previous methods by a large margin across various model size ranges.
Read more7/23/2024
🛠️
0
Optimization of DNN-based speaker verification model through efficient quantization technique
Yeona Hong, Woo-Jin Chung, Hong-Goo Kang
As Deep Neural Networks (DNNs) rapidly advance in various fields, including speech verification, they typically involve high computational costs and substantial memory consumption, which can be challenging to manage on mobile systems. Quantization of deep models offers a means to reduce both computational and memory expenses. Our research proposes an optimization framework for the quantization of the speaker verification model. By analyzing performance changes and model size reductions in each layer of a pre-trained speaker verification model, we have effectively minimized performance degradation while significantly reducing the model size. Our quantization algorithm is the first attempt to maintain the performance of the state-of-the-art pre-trained speaker verification model, ECAPATDNN, while significantly compressing its model size. Overall, our quantization approach resulted in reducing the model size by half, with an increase in EER limited to 0.07%.
Read more7/15/2024
0
SAML: Speaker Adaptive Mixture of LoRA Experts for End-to-End ASR
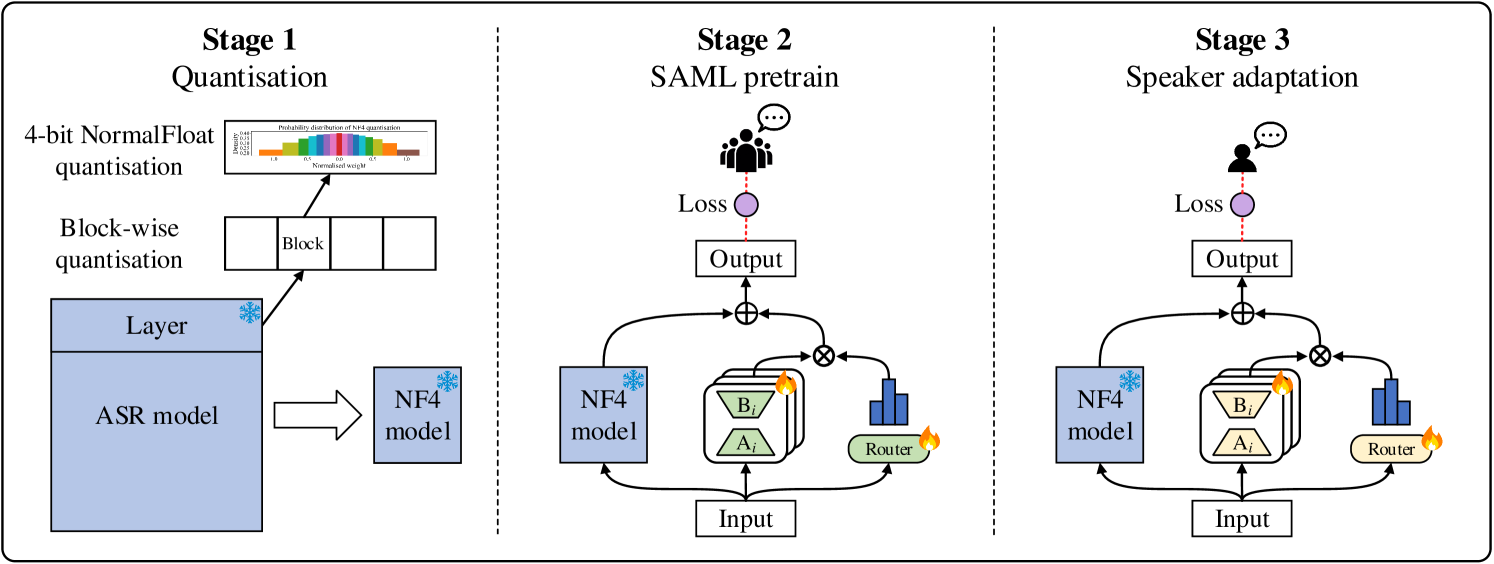
Qiuming Zhao, Guangzhi Sun, Chao Zhang, Mingxing Xu, Thomas Fang Zheng
Mixture-of-experts (MoE) models have achieved excellent results in many tasks. However, conventional MoE models are often very large, making them challenging to deploy on resource-constrained edge devices. In this paper, we propose a novel speaker adaptive mixture of LoRA experts (SAML) approach, which uses low-rank adaptation (LoRA) modules as experts to reduce the number of trainable parameters in MoE. Specifically, SAML is applied to the quantised and personalised end-to-end automatic speech recognition models, which combines test-time speaker adaptation to improve the performance of heavily compressed models in speaker-specific scenarios. Experiments have been performed on the LibriSpeech and the TED-LIUM 3 corpora. Remarkably, with a 7x reduction in model size, 29.1% and 31.1% relative word error rate reductions were achieved on the quantised Whisper model and Conformer-based attention-based encoder-decoder ASR model respectively, comparing to the original full precision models.
Read more7/1/2024