Speaker and Style Disentanglement of Speech Based on Contrastive Predictive Coding Supported Factorized Variational Autoencoder

0

Sign in to get full access
Overview
- This paper proposes a Speaker and Style Disentanglement (SSD) model for speech, which aims to separate the speaker identity and speaking style into distinct latent representations.
- The model uses a Contrastive Predictive Coding (CPC) supported Factorized Variational Autoencoder (FVAE) architecture to achieve this disentanglement.
- The proposed approach demonstrates strong performance on speech conversion and voice conversion tasks, showing its ability to learn disentangled representations.
Plain English Explanation
The paper presents a [object Object] model for speech, which can separate the [object Object] and their [object Object] into distinct latent representations. This is achieved by using a [object Object] supported [object Object] architecture.
The key idea is to learn separate representations for the speaker's identity and their speaking style, which can then be manipulated independently. For example, this could allow you to change the speaking style of a particular person's voice while keeping their identity intact, or to convert the voice of one person to sound like another person but with their own speaking style. The authors show that their model performs well on these types of speech conversion and voice conversion tasks, demonstrating its ability to learn disentangled representations.
Technical Explanation
The [object Object] model proposed in this paper uses a [object Object] architecture, where the latent representation is factorized into speaker and style components. To further improve the disentanglement, the authors incorporate [object Object] as an auxiliary task, which encourages the model to learn representations that are predictive of the future but invariant to the speaker identity and style.
The model is trained on a dataset of speech recordings from multiple speakers, and the authors evaluate its performance on speech conversion and voice conversion tasks. The results show that the SSD model is able to successfully disentangle the speaker identity and speaking style, outperforming previous state-of-the-art methods.
Critical Analysis
The [object Object] presents a promising approach for learning disentangled representations of speech, with potential applications in areas like voice conversion and speech synthesis. However, the authors acknowledge that the model is currently limited to a fixed number of speakers, and that further research is needed to scale it to larger and more diverse datasets.
Additionally, the paper does not provide a thorough analysis of the learned latent representations or the specific mechanisms by which the model achieves disentanglement. It would be valuable to have a deeper understanding of how the [object Object] and [object Object] components interact to enable the disentanglement, and whether there are any potential trade-offs or limitations in this approach.
Overall, the [object Object] represents an interesting step forward in the field of [object Object], and the authors' future work on scaling and further understanding the model could lead to valuable insights and advancements.
Conclusion
This paper presents a [object Object] model for speech, which uses a [object Object] supported [object Object] architecture to learn separate representations for a speaker's identity and speaking style. The model demonstrates strong performance on speech conversion and voice conversion tasks, showcasing its ability to effectively disentangle these factors.
While the paper provides a solid technical foundation, further research is needed to scale the model to larger and more diverse datasets, as well as to gain a deeper understanding of the disentanglement mechanisms. Nonetheless, the [object Object] represents an important step forward in the field of [object Object] for speech, with promising applications in areas like [object Object] and [object Object].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Speaker and Style Disentanglement of Speech Based on Contrastive Predictive Coding Supported Factorized Variational Autoencoder
Yuying Xie, Michael Kuhlmann, Frederik Rautenberg, Zheng-Hua Tan, Reinhold Haeb-Umbach
Speech signals encompass various information across multiple levels including content, speaker, and style. Disentanglement of these information, although challenging, is important for applications such as voice conversion. The contrastive predictive coding supported factorized variational autoencoder achieves unsupervised disentanglement of a speech signal into speaker and content embeddings by assuming speaker info to be temporally more stable than content-induced variations. However, this assumption may introduce other temporal stable information into the speaker embeddings, like environment or emotion, which we call style. In this work, we propose a method to further disentangle non-content features into distinct speaker and style features, notably by leveraging readily accessible and well-defined speaker labels without the necessity for style labels. Experimental results validate the proposed method's effectiveness on extracting disentangled features, thereby facilitating speaker, style, or combined speaker-style conversion.
Read more9/6/2024
0
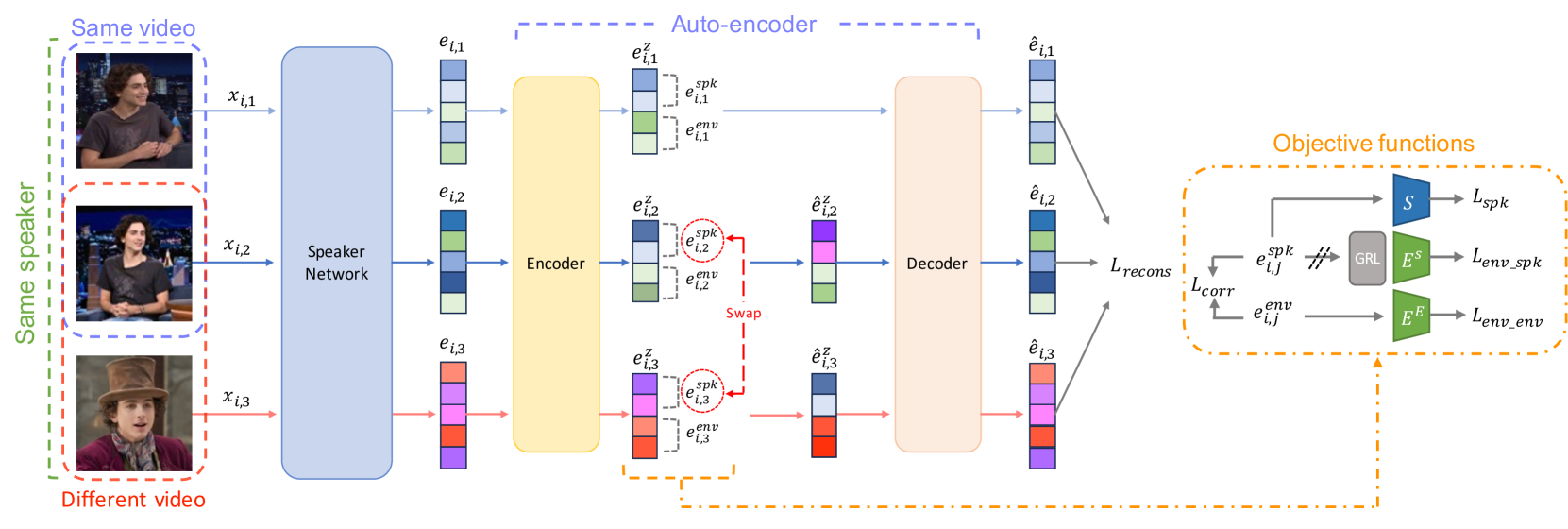
Disentangled Representation Learning for Environment-agnostic Speaker Recognition
KiHyun Nam, Hee-Soo Heo, Jee-weon Jung, Joon Son Chung
This work presents a framework based on feature disentanglement to learn speaker embeddings that are robust to environmental variations. Our framework utilises an auto-encoder as a disentangler, dividing the input speaker embedding into components related to the speaker and other residual information. We employ a group of objective functions to ensure that the auto-encoder's code representation - used as the refined embedding - condenses only the speaker characteristics. We show the versatility of our framework through its compatibility with any existing speaker embedding extractor, requiring no structural modifications or adaptations for integration. We validate the effectiveness of our framework by incorporating it into two popularly used embedding extractors and conducting experiments across various benchmarks. The results show a performance improvement of up to 16%. We release our code for this work to be available https://github.com/kaistmm/voxceleb-disentangler
Read more6/21/2024

0
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Zhaoxi Mu, Xinyu Yang, Sining Sun, Qing Yang
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
Read more8/27/2024
0
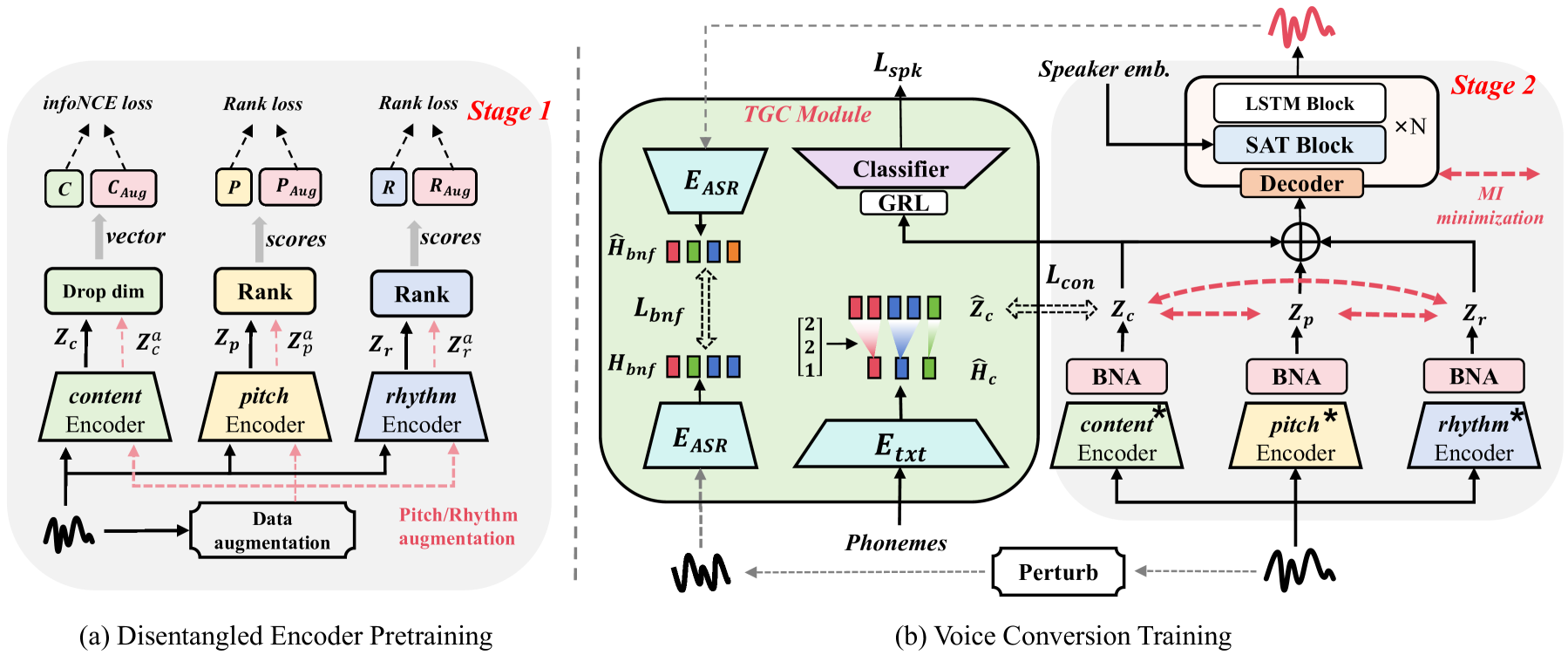
EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning
Ziqi Liang, Jianzong Wang, Xulong Zhang, Yong Zhang, Ning Cheng, Jing Xiao
Using unsupervised learning to disentangle speech into content, rhythm, pitch, and timbre for voice conversion has become a hot research topic. Existing works generally take into account disentangling speech components through human-crafted bottleneck features which can not achieve sufficient information disentangling, while pitch and rhythm may still be mixed together. There is a risk of information overlap in the disentangling process which results in less speech naturalness. To overcome such limits, we propose a two-stage model to disentangle speech representations in a self-supervised manner without a human-crafted bottleneck design, which uses the Mutual Information (MI) with the designed upper bound estimator (IFUB) to separate overlapping information between speech components. Moreover, we design a Joint Text-Guided Consistent (TGC) module to guide the extraction of speech content and eliminate timbre leakage issues. Experiments show that our model can achieve a better performance than the baseline, regarding disentanglement effectiveness, speech naturalness, and similarity. Audio samples can be found at https://largeaudiomodel.com/eadvc.
Read more5/1/2024