EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning

0
Sign in to get full access
Overview
- The paper introduces EAD-VC, a method for enhancing speech auto-disentanglement for voice conversion tasks.
- It proposes using an IFUB (Intrinsic Flat Upper Bound) estimator to improve the disentanglement of speaker identity and content information.
- The method also incorporates joint text-guided consistent learning to further enhance the disentanglement and voice conversion performance.
Plain English Explanation
The researchers developed a new approach called EAD-VC to help convert one person's voice to sound like another person's voice more effectively. This is useful for applications like dubbing movies or creating virtual assistants with customized voices.
The key innovations in EAD-VC are:
-
IFUB Estimator: This is a mathematical technique that helps separate the speaker's identity (who is talking) from the content of what they are saying. This improves the ability to convert the voice while preserving the original meaning.
-
Joint Text-Guided Consistent Learning: This additional training step uses the written text associated with the speech to further improve the separation of speaker identity and content. This helps ensure the converted voice sounds natural and consistent with the original meaning.
By combining these two techniques, the researchers were able to enhance the "disentanglement" - or separation - of speaker identity and speech content. This led to higher-quality voice conversion that maintains the original meaning and emotion, even when the voice is changed to sound like someone else.
The researchers tested their approach on several standard voice conversion datasets and found significant improvements compared to previous methods. This suggests EAD-VC could be a valuable tool for applications that require high-fidelity voice conversion, such as audio-visual dubbing or expressive speech synthesis.
Technical Explanation
The core of the EAD-VC method is a speech auto-disentanglement framework that separates the speaker identity and speech content representations. This is achieved through a neural network architecture with two key components:
-
IFUB Estimator: The researchers propose using an Intrinsic Flat Upper Bound (IFUB) estimator to improve the disentanglement of speaker identity and content information. This estimator helps maximize the mutual information between the input speech and the extracted content representation, while minimizing the mutual information between the speaker identity and content representations.
-
Joint Text-Guided Consistent Learning: In addition to the IFUB estimator, the researchers incorporate a text-guided consistency regularization loss. This loss encourages the model to generate content representations that are consistent with the input text, further enhancing the disentanglement of speaker identity and speech content.
The full EAD-VC model is trained end-to-end using a combination of these two key components, along with standard voice conversion losses. The researchers evaluate their approach on several benchmark voice conversion datasets, including VCTK, LJSpeech, and AISHELL-3. Their results demonstrate significant improvements in voice conversion quality compared to previous state-of-the-art methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the EAD-VC method, with extensive experiments and comparison to multiple baselines. The proposed IFUB estimator and joint text-guided consistent learning appear to be effective at enhancing speech auto-disentanglement and improving voice conversion performance.
However, the paper does not address some potential limitations or future research directions. For example, the method assumes the availability of parallel training data (i.e., speech recordings paired with their corresponding text transcripts), which may not always be readily available. It would be interesting to see if the approach could be extended to work with non-parallel data as well.
Additionally, the paper focuses on objective evaluation metrics, but it would be valuable to also conduct subjective user studies to assess the perceptual quality and naturalness of the converted voices. This could provide further insights into the practical usefulness of the EAD-VC method.
Overall, the EAD-VC approach represents a significant advancement in speech auto-disentanglement and voice conversion, and the technical innovations introduced in this paper are likely to inspire further research in this area.
Conclusion
The EAD-VC method proposed in this paper offers an effective solution for enhancing speech auto-disentanglement and improving the quality of voice conversion. By leveraging an IFUB estimator and joint text-guided consistent learning, the researchers were able to achieve state-of-the-art voice conversion performance on several benchmark datasets.
This work has important implications for a range of applications, such as audio-visual dubbing, expressive speech synthesis, and the development of virtual assistants with customized voices. The technical innovations introduced in this paper are likely to inspire further research and advancements in the field of speech processing and voice conversion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EAD-VC: Enhancing Speech Auto-Disentanglement for Voice Conversion with IFUB Estimator and Joint Text-Guided Consistent Learning
Ziqi Liang, Jianzong Wang, Xulong Zhang, Yong Zhang, Ning Cheng, Jing Xiao
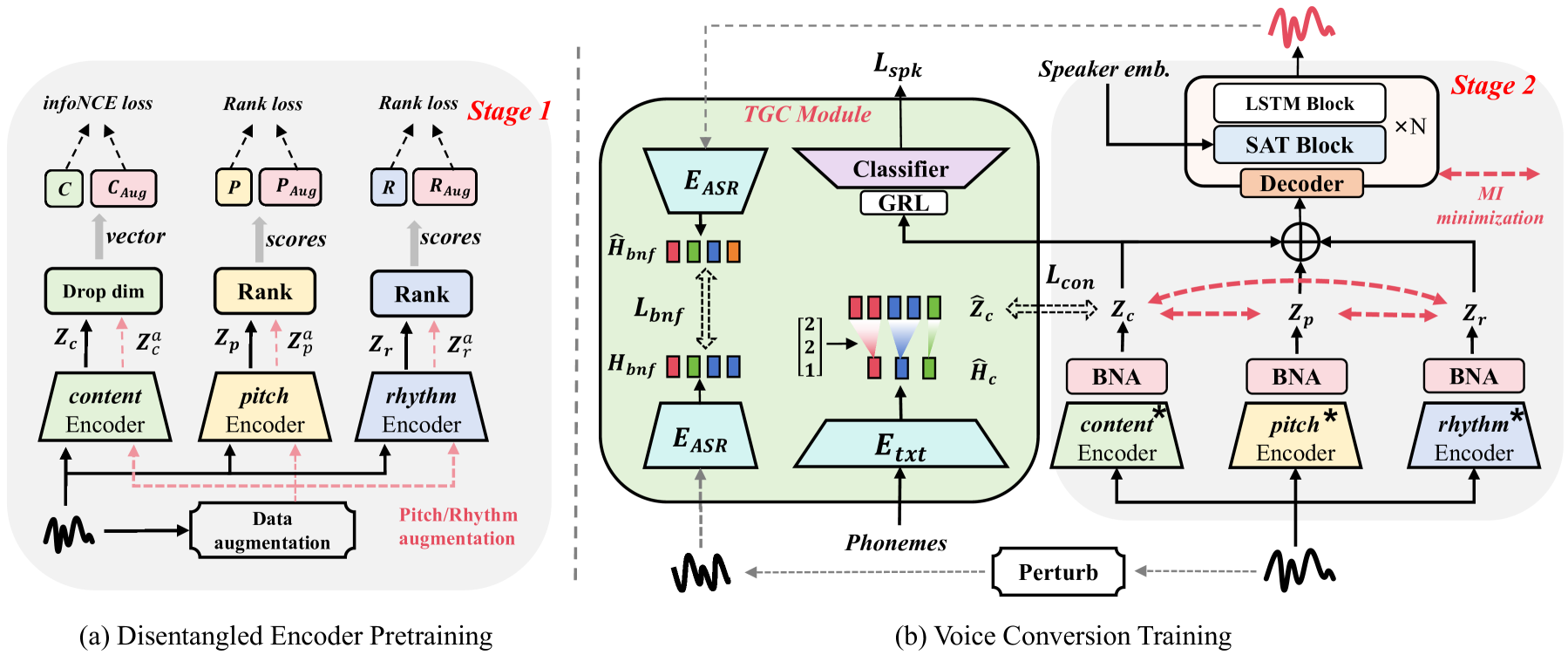
Using unsupervised learning to disentangle speech into content, rhythm, pitch, and timbre for voice conversion has become a hot research topic. Existing works generally take into account disentangling speech components through human-crafted bottleneck features which can not achieve sufficient information disentangling, while pitch and rhythm may still be mixed together. There is a risk of information overlap in the disentangling process which results in less speech naturalness. To overcome such limits, we propose a two-stage model to disentangle speech representations in a self-supervised manner without a human-crafted bottleneck design, which uses the Mutual Information (MI) with the designed upper bound estimator (IFUB) to separate overlapping information between speech components. Moreover, we design a Joint Text-Guided Consistent (TGC) module to guide the extraction of speech content and eliminate timbre leakage issues. Experiments show that our model can achieve a better performance than the baseline, regarding disentanglement effectiveness, speech naturalness, and similarity. Audio samples can be found at https://largeaudiomodel.com/eadvc.
Read more5/1/2024

0
Self-Supervised Disentangled Representation Learning for Robust Target Speech Extraction
Zhaoxi Mu, Xinyu Yang, Sining Sun, Qing Yang
Speech signals are inherently complex as they encompass both global acoustic characteristics and local semantic information. However, in the task of target speech extraction, certain elements of global and local semantic information in the reference speech, which are irrelevant to speaker identity, can lead to speaker confusion within the speech extraction network. To overcome this challenge, we propose a self-supervised disentangled representation learning method. Our approach tackles this issue through a two-phase process, utilizing a reference speech encoding network and a global information disentanglement network to gradually disentangle the speaker identity information from other irrelevant factors. We exclusively employ the disentangled speaker identity information to guide the speech extraction network. Moreover, we introduce the adaptive modulation Transformer to ensure that the acoustic representation of the mixed signal remains undisturbed by the speaker embeddings. This component incorporates speaker embeddings as conditional information, facilitating natural and efficient guidance for the speech extraction network. Experimental results substantiate the effectiveness of our meticulously crafted approach, showcasing a substantial reduction in the likelihood of speaker confusion.
Read more8/27/2024

0
Speaker and Style Disentanglement of Speech Based on Contrastive Predictive Coding Supported Factorized Variational Autoencoder
Yuying Xie, Michael Kuhlmann, Frederik Rautenberg, Zheng-Hua Tan, Reinhold Haeb-Umbach
Speech signals encompass various information across multiple levels including content, speaker, and style. Disentanglement of these information, although challenging, is important for applications such as voice conversion. The contrastive predictive coding supported factorized variational autoencoder achieves unsupervised disentanglement of a speech signal into speaker and content embeddings by assuming speaker info to be temporally more stable than content-induced variations. However, this assumption may introduce other temporal stable information into the speaker embeddings, like environment or emotion, which we call style. In this work, we propose a method to further disentangle non-content features into distinct speaker and style features, notably by leveraging readily accessible and well-defined speaker labels without the necessity for style labels. Experimental results validate the proposed method's effectiveness on extracting disentangled features, thereby facilitating speaker, style, or combined speaker-style conversion.
Read more9/6/2024
0
Towards the Next Frontier in Speech Representation Learning Using Disentanglement
Varun Krishna, Sriram Ganapathy
The popular frameworks for self-supervised learning of speech representations have largely focused on frame-level masked prediction of speech regions. While this has shown promising downstream task performance for speech recognition and related tasks, this has largely ignored factors of speech that are encoded at coarser level, like characteristics of the speaker or channel that remain consistent through-out a speech utterance. In this work, we propose a framework for Learning Disentangled Self Supervised (termed as Learn2Diss) representations of speech, which consists of frame-level and an utterance-level encoder modules. The two encoders are initially learned independently, where the frame-level model is largely inspired by existing self supervision techniques, thereby learning pseudo-phonemic representations, while the utterance-level encoder is inspired by constrastive learning of pooled embeddings, thereby learning pseudo-speaker representations. The joint learning of these two modules consists of disentangling the two encoders using a mutual information based criterion. With several downstream evaluation experiments, we show that the proposed Learn2Diss achieves state-of-the-art results on a variety of tasks, with the frame-level encoder representations improving semantic tasks, while the utterance-level representations improve non-semantic tasks.
Read more7/4/2024