Spectral Codecs: Spectrogram-Based Audio Codecs for High Quality Speech Synthesis

0

Sign in to get full access
Overview
- This paper introduces "Spectral Codecs", a new approach to high-quality speech synthesis that uses spectrogram-based audio codecs.
- The authors propose techniques to improve the quality of speech generation by focusing on the spectrogram representation of audio, rather than the waveform.
- This work is relevant to advancements in text-to-speech and speech tokenization systems.
Plain English Explanation
The paper describes a new way to create high-quality synthetic speech using "spectral codecs". Rather than working directly with the raw audio waveform, the authors focus on representing the audio as a spectrogram - a visual plot of the frequency content over time.
By optimizing the spectrogram representation, they are able to generate more natural-sounding speech. This is an interesting alternative to traditional speech synthesis approaches that operate on the waveform directly. The spectrogram-based techniques could lead to improved text-to-speech systems and more efficient ways to represent speech data.
The key idea is that the spectrogram, which shows the frequency information of the audio, may be an easier and more effective representation to work with compared to the raw waveform. By focusing on optimizing this spectrogram, the authors are able to synthesize speech that sounds more natural and human-like.
Technical Explanation
The paper introduces "Spectral Codecs", a new approach to speech synthesis that operates on the spectrogram representation of audio rather than the raw waveform. The authors propose several techniques to improve the quality of generated speech by optimizing the spectrogram:
-
Spectrogram-based Codec: The authors develop a neural network-based codec that can encode and decode high-quality spectrograms, enabling efficient storage and transmission of the audio data.
-
Spectrogram-based Up-sampling: To generate high-resolution spectrograms, the authors use a diffusion model to up-sample low-resolution spectrograms.
-
Spectrogram-based Synthesis: A neural network is trained to generate spectrograms from linguistic features, which are then converted to audio waveforms.
The key insight is that optimizing the spectrogram representation, rather than the waveform directly, can lead to more natural-sounding synthetic speech. This is because the spectrogram captures the frequency content of the audio in a more interpretable way, making it easier for the neural networks to model the complex patterns of human speech.
Critical Analysis
The paper presents a promising new approach to high-quality speech synthesis, but there are a few potential limitations and areas for future research:
-
Computational Complexity: The authors mention that the spectrogram-based techniques may be more computationally intensive than traditional waveform-based methods. Further research is needed to optimize the efficiency of the proposed models.
-
Language Generalization: The experiments in the paper focus on English speech. It would be valuable to evaluate the performance of Spectral Codecs on other languages to assess its broader applicability.
-
Subjective Evaluation: While the authors report objective metrics like signal-to-noise ratio, a more thorough subjective evaluation with human listeners would help validate the perceived quality improvements of the Spectral Codec approach.
-
Integration with Other Techniques: The paper does not discuss how Spectral Codecs could be combined with language modeling or speech representation learning techniques to further enhance speech synthesis capabilities.
Overall, the Spectral Codec approach is an interesting and promising direction for advancing the state-of-the-art in high-quality speech synthesis. The focus on the spectrogram representation is a unique perspective that could lead to important breakthroughs in text-to-speech and related areas.
Conclusion
This paper introduces "Spectral Codecs", a new technique for high-quality speech synthesis that focuses on optimizing the spectrogram representation of audio, rather than working directly with the raw waveform. The authors demonstrate several techniques, including spectrogram-based coding, up-sampling, and synthesis, that can lead to more natural-sounding synthetic speech.
While the paper presents promising results, there are still some areas for further research and improvement, such as computational efficiency, language generalization, and integration with other speech processing techniques. Overall, the Spectral Codec approach represents an interesting and innovative direction in the field of speech synthesis that could have significant implications for text-to-speech applications and speech representation learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Spectral Codecs: Spectrogram-Based Audio Codecs for High Quality Speech Synthesis
Ryan Langman, Ante Juki'c, Kunal Dhawan, Nithin Rao Koluguri, Boris Ginsburg
Historically, most speech models in machine-learning have used the mel-spectrogram as a speech representation. Recently, discrete audio tokens produced by neural audio codecs have become a popular alternate speech representation for speech synthesis tasks such as text-to-speech (TTS). However, the data distribution produced by such codecs is too complex for some TTS models to predict, hence requiring large autoregressive models to get reasonable quality. Typical audio codecs compress and reconstruct the time-domain audio signal. We propose a spectral codec which compresses the mel-spectrogram and reconstructs the time-domain audio signal. A study of objective audio quality metrics suggests that our spectral codec has comparable perceptual quality to equivalent audio codecs. Furthermore, non-autoregressive TTS models trained with the proposed spectral codec generate audio with significantly higher quality than when trained with mel-spectrograms or audio codecs.
Read more6/11/2024

0
Codec-ASR: Training Performant Automatic Speech Recognition Systems with Discrete Speech Representations
Kunal Dhawan, Nithin Rao Koluguri, Ante Juki'c, Ryan Langman, Jagadeesh Balam, Boris Ginsburg
Discrete speech representations have garnered recent attention for their efficacy in training transformer-based models for various speech-related tasks such as automatic speech recognition (ASR), translation, speaker verification, and joint speech-text foundational models. In this work, we present a comprehensive analysis on building ASR systems with discrete codes. We investigate different methods for codec training such as quantization schemes and time-domain vs spectral feature encodings. We further explore ASR training techniques aimed at enhancing performance, training efficiency, and noise robustness. Drawing upon our findings, we introduce a codec ASR pipeline that outperforms Encodec at similar bit-rate. Remarkably, it also surpasses the state-of-the-art results achieved by strong self-supervised models on the 143 languages ML-SUPERB benchmark despite being smaller in size and pretrained on significantly less data.
Read more7/8/2024
🗣️
0
Language-Codec: Reducing the Gaps Between Discrete Codec Representation and Speech Language Models
Shengpeng Ji, Minghui Fang, Ziyue Jiang, Siqi Zheng, Qian Chen, Rongjie Huang, Jialung Zuo, Shulei Wang, Zhou Zhao
In recent years, large language models have achieved significant success in generative tasks (e.g., speech cloning and audio generation) related to speech, audio, music, and other signal domains. A crucial element of these models is the discrete acoustic codecs, which serves as an intermediate representation replacing the mel-spectrogram. However, there exist several gaps between discrete codecs and downstream speech language models. Specifically, 1) most codec models are trained on only 1,000 hours of data, whereas most speech language models are trained on 60,000 hours; 2) Achieving good reconstruction performance requires the utilization of numerous codebooks, which increases the burden on downstream speech language models; 3) The initial channel of the codebooks contains excessive information, making it challenging to directly generate acoustic tokens from weakly supervised signals such as text in downstream tasks. Consequently, leveraging the characteristics of speech language models, we propose Language-Codec. In the Language-Codec, we introduce a Mask Channel Residual Vector Quantization (MCRVQ) mechanism along with improved Fourier transform structures and larger training datasets to address the aforementioned gaps. We compare our method with competing audio compression algorithms and observe significant outperformance across extensive evaluations. Furthermore, we also validate the efficiency of the Language-Codec on downstream speech language models. The source code and pre-trained models can be accessed at https://github.com/jishengpeng/languagecodec .
Read more4/30/2024
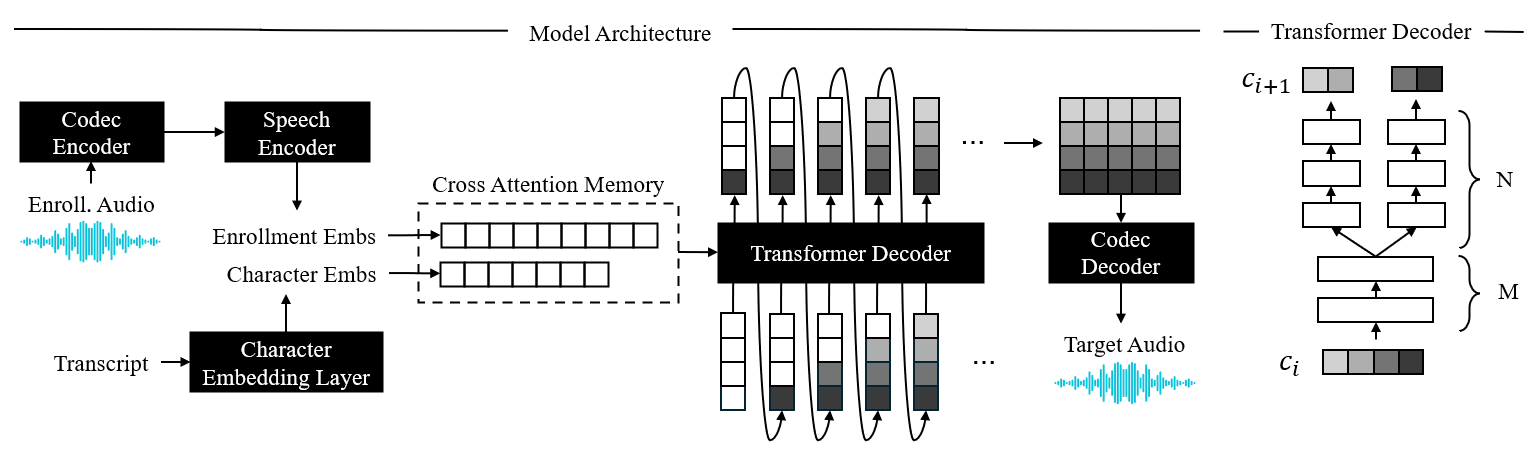
0
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Trung Dang, David Aponte, Dung Tran, Kazuhito Koishida
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
Read more6/11/2024