SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
2405.12739
0
0
📶
Abstract
Human preference alignment is critical in building powerful and reliable large language models (LLMs). However, current methods either ignore the multi-dimensionality of human preferences (e.g. helpfulness and harmlessness) or struggle with the complexity of managing multiple reward models. To address these issues, we propose Sequential Preference Optimization (SPO), a method that sequentially fine-tunes LLMs to align with multiple dimensions of human preferences. SPO avoids explicit reward modeling, directly optimizing the models to align with nuanced human preferences. We theoretically derive closed-form optimal SPO policy and loss function. Gradient analysis is conducted to show how SPO manages to fine-tune the LLMs while maintaining alignment on previously optimized dimensions. Empirical results on LLMs of different size and multiple evaluation datasets demonstrate that SPO successfully aligns LLMs across multiple dimensions of human preferences and significantly outperforms the baselines.
Create account to get full access
Overview
- This paper proposes a method called Sequential Preference Optimization (SPO) to align large language models (LLMs) with multiple dimensions of human preferences.
- Current methods either ignore the multi-dimensionality of human preferences or struggle with managing multiple reward models.
- SPO aims to directly optimize LLMs to align with nuanced human preferences without explicit reward modeling.
Plain English Explanation
The researchers recognize that as we develop powerful AI language models, it's critical to ensure they align with human preferences. This means the models should be helpful and harmless, rather than just optimizing for a single metric.
However, existing approaches have struggled with this challenge. Some methods ignore the fact that human preferences are multi-dimensional - we care about things like helpfulness and safety, not just a single reward. Other approaches try to manage multiple reward models, but this complexity is difficult to handle.
To address these issues, the researchers propose a new technique called Sequential Preference Optimization (SPO). Instead of explicit reward modeling, SPO directly fine-tunes the language models to match nuanced human preferences. The key insight is that this sequential optimization process can maintain alignment on previously optimized dimensions while continuously improving the model.
Technical Explanation
The paper theoretically derives the optimal SPO policy and loss function. They also conduct gradient analysis to show how SPO can fine-tune the language models while preserving alignment on earlier preference dimensions.
Experimentally, the researchers evaluate SPO on language models of different sizes and across multiple datasets. The results demonstrate that SPO successfully aligns the models with multiple aspects of human preferences, outperforming existing baselines like direct preference optimization and self-play preference optimization.
Critical Analysis
The paper provides a thoughtful approach to the important challenge of aligning powerful AI systems with human values. By considering the multi-dimensional nature of preferences, the researchers avoid the limitations of single-objective optimization.
However, the work does not address how to elicit and represent the full spectrum of human preferences, which remains an open challenge. Additionally, the evaluation is limited to language model performance and does not consider potential real-world impacts or societal implications.
Further research is needed to understand the robustness of SPO to distributional shift, the scalability to more complex preference spaces, and the broader ethical considerations around aligning AI systems with human values. Critically analyzing the assumptions and limitations of this approach is key to advancing the field.
Conclusion
This paper introduces Sequential Preference Optimization (SPO) as a promising technique for aligning large language models with multiple dimensions of human preferences. By directly optimizing the models rather than explicit reward modeling, SPO can capture nuanced preferences while maintaining alignment on previously optimized dimensions.
The empirical results demonstrate the effectiveness of SPO, suggesting it as a valuable tool for building powerful and reliable AI systems that are truly helpful and harmless. However, continued research is needed to address the broader challenges of preference elicitation, robustness, and the responsible development of transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
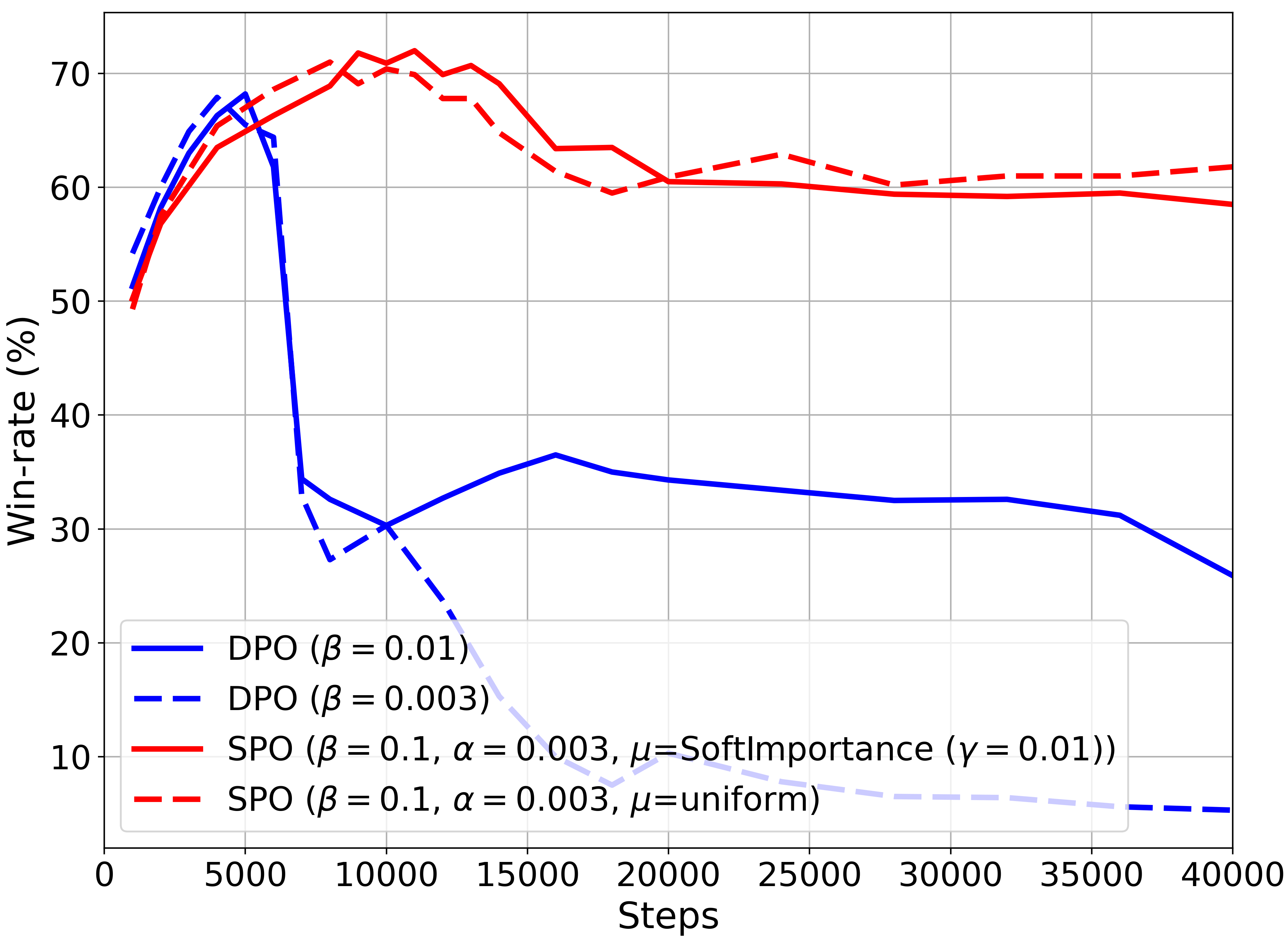
Soft Preference Optimization: Aligning Language Models to Expert Distributions
Arsalan Sharifnassab, Sina Ghiassian, Saber Salehkaleybar, Surya Kanoria, Dale Schuurmans
0
0
We propose Soft Preference Optimization (SPO), a method for aligning generative models, such as Large Language Models (LLMs), with human preferences, without the need for a reward model. SPO optimizes model outputs directly over a preference dataset through a natural loss function that integrates preference loss with a regularization term across the model's entire output distribution rather than limiting it to the preference dataset. Although SPO does not require the assumption of an existing underlying reward model, we demonstrate that, under the Bradley-Terry (BT) model assumption, it converges to a softmax of scaled rewards, with the distribution's softness adjustable via the softmax exponent, an algorithm parameter. We showcase SPO's methodology, its theoretical foundation, and its comparative advantages in simplicity, computational efficiency, and alignment precision.
5/29/2024
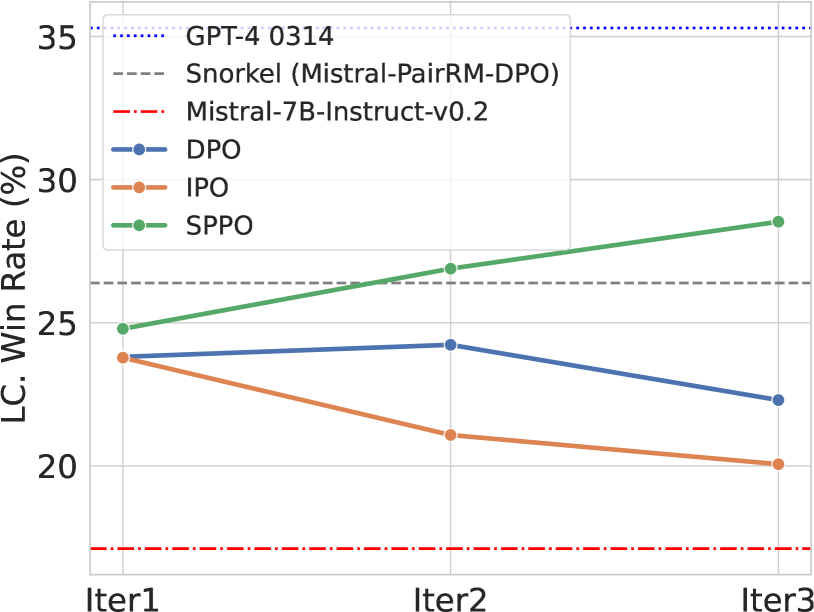
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
6/17/2024
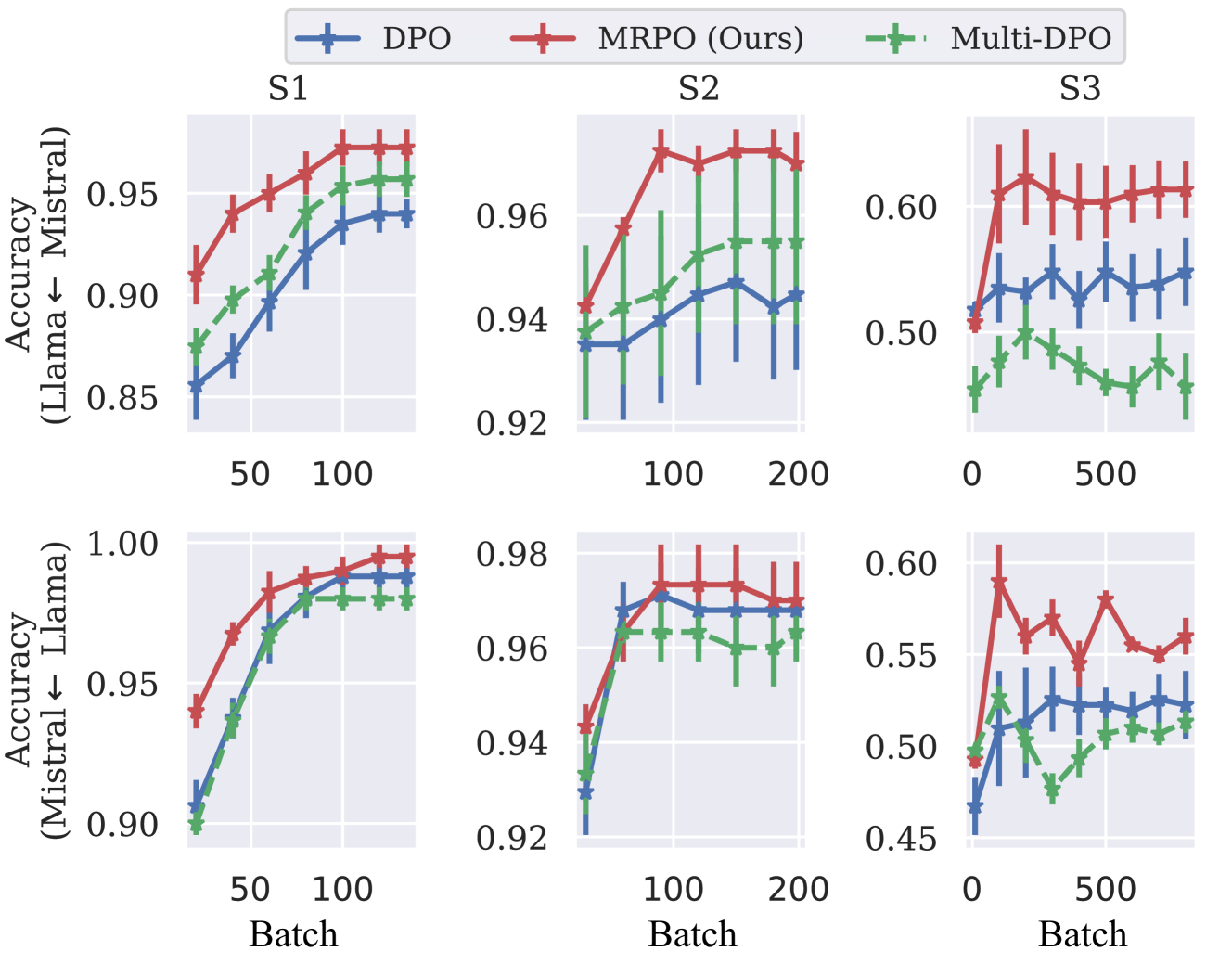
Multi-Reference Preference Optimization for Large Language Models
Hung Le, Quan Tran, Dung Nguyen, Kien Do, Saloni Mittal, Kelechi Ogueji, Svetha Venkatesh
0
0
How can Large Language Models (LLMs) be aligned with human intentions and values? A typical solution is to gather human preference on model outputs and finetune the LLMs accordingly while ensuring that updates do not deviate too far from a reference model. Recent approaches, such as direct preference optimization (DPO), have eliminated the need for unstable and sluggish reinforcement learning optimization by introducing close-formed supervised losses. However, a significant limitation of the current approach is its design for a single reference model only, neglecting to leverage the collective power of numerous pretrained LLMs. To overcome this limitation, we introduce a novel closed-form formulation for direct preference optimization using multiple reference models. The resulting algorithm, Multi-Reference Preference Optimization (MRPO), leverages broader prior knowledge from diverse reference models, substantially enhancing preference learning capabilities compared to the single-reference DPO. Our experiments demonstrate that LLMs finetuned with MRPO generalize better in various preference data, regardless of data scarcity or abundance. Furthermore, MRPO effectively finetunes LLMs to exhibit superior performance in several downstream natural language processing tasks such as GSM8K and TruthfulQA.
5/28/2024
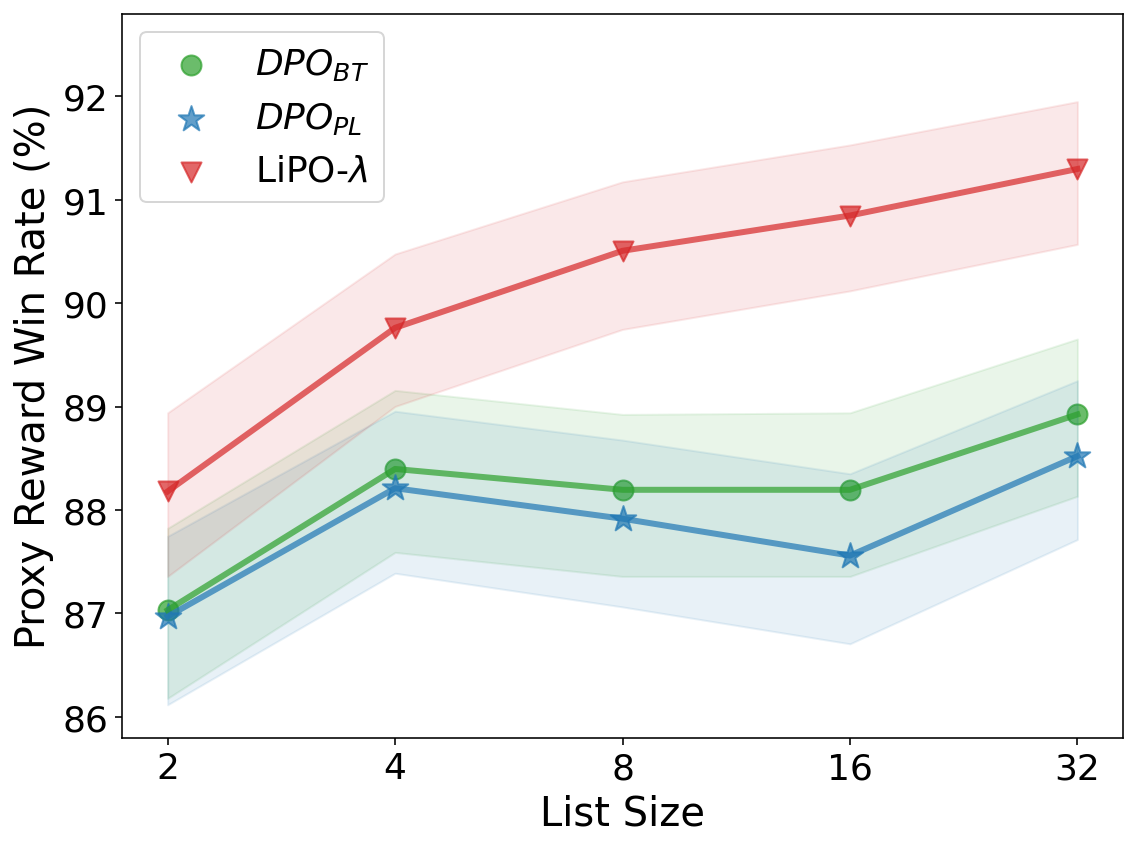
LiPO: Listwise Preference Optimization through Learning-to-Rank
Tianqi Liu, Zhen Qin, Junru Wu, Jiaming Shen, Misha Khalman, Rishabh Joshi, Yao Zhao, Mohammad Saleh, Simon Baumgartner, Jialu Liu, Peter J. Liu, Xuanhui Wang
0
0
Aligning language models (LMs) with curated human feedback is critical to control their behaviors in real-world applications. Several recent policy optimization methods, such as DPO and SLiC, serve as promising alternatives to the traditional Reinforcement Learning from Human Feedback (RLHF) approach. In practice, human feedback often comes in a format of a ranked list over multiple responses to amortize the cost of reading prompt. Multiple responses can also be ranked by reward models or AI feedback. There lacks such a thorough study on directly fitting upon a list of responses. In this work, we formulate the LM alignment as a textit{listwise} ranking problem and describe the LiPO framework, where the policy can potentially learn more effectively from a ranked list of plausible responses given the prompt. This view draws an explicit connection to Learning-to-Rank (LTR), where most existing preference optimization work can be mapped to existing ranking objectives. Following this connection, we provide an examination of ranking objectives that are not well studied for LM alignment with DPO and SLiC as special cases when list size is two. In particular, we highlight a specific method, LiPO-$lambda$, which leverages a state-of-the-art textit{listwise} ranking objective and weights each preference pair in a more advanced manner. We show that LiPO-$lambda$ can outperform DPO variants and SLiC by a clear margin on several preference alignment tasks with both curated and real rankwise preference data.
5/24/2024