SPVLoc: Semantic Panoramic Viewport Matching for 6D Camera Localization in Unseen Environments

0
Sign in to get full access
Overview
• This paper presents SPVLoc, a novel approach for 6D camera localization in unseen environments using semantic panoramic viewport matching. • The key idea is to leverage semantic information from panoramic images to accurately match and localize the camera pose, even in complex environments that the system has not been trained on before. • The paper explores how this semantic panoramic matching can be more effective than traditional approaches that rely solely on low-level visual features.
Plain English Explanation
• Imagine you're trying to figure out where you are in a new place, but you don't have a map or any prior knowledge of the area. SPVLoc is a system that can help you do this by using 360-degree panoramic images. • The key insight is that these panoramic views contain a lot of semantic information - things like what objects and structures are present, their relationships to each other, and so on. By matching this semantic information between the panoramic view you see and a database of reference panoramas, SPVLoc can accurately determine your 3D position and orientation (6D pose) without needing to know the specific environment ahead of time. • This is more powerful than approaches that just look at low-level visual features like edges and textures, which can struggle in complex or unfamiliar scenes. By tapping into the higher-level semantic understanding, SPVLoc can localize you even in places it hasn't been trained on before.
Technical Explanation
• The SPVLoc system works by first capturing a 360-degree panoramic image from the user's camera. It then extracts semantic information from this image, such as the types of objects present, their spatial relationships, and other high-level scene attributes. • This semantic panoramic image is then matched against a database of reference panoramas, each with associated 6D camera poses. By finding the closest semantic match, SPVLoc can determine the user's 6D pose - their 3D position and 3D orientation - within the environment. • The key technical innovations include a novel semantic panorama representation, efficient matching algorithms, and the ability to localize in previously unseen environments [link to "Fully Geometric Panoramic Localization"]. • Experiments demonstrate SPVLoc's superior performance compared to state-of-the-art visual localization approaches, especially in complex and unfamiliar scenes [link to "Unified Spatio-Temporal Tri-Perspective View Representation", "DreamScene360: Unconstrained Text-to-3D Scene Generation", "360Loc Dataset: Benchmark for Omnidirectional Visual Localization Across Scenes", "Photo-SLAM: Real-Time Simultaneous Localization and Photorealistic"].
Critical Analysis
• The paper acknowledges that SPVLoc's performance may degrade in environments with significant changes over time, such as construction or seasonal variations. Further research is needed to address dynamic environments. • The database of reference panoramas required by SPVLoc could be costly to build and maintain, especially for large-scale real-world deployment. Techniques to reduce this overhead would be valuable. • While the semantic approach shows promise, it remains to be seen how SPVLoc would perform relative to emerging deep learning-based localization methods that can also leverage high-level scene understanding [link to relevant papers]. • Overall, the core ideas behind SPVLoc are compelling and represent an interesting direction for improving camera localization in complex, unseen environments.
Conclusion
• The SPVLoc system introduces a new approach to 6D camera localization that leverages semantic information from panoramic images, enabling accurate pose estimation even in unfamiliar environments. • By moving beyond traditional low-level visual features and instead tapping into higher-level scene understanding, SPVLoc demonstrates the potential of semantic-aware localization techniques. • While the current system has some limitations, the underlying concepts represent an exciting step forward in expanding the capabilities of camera localization systems to operate robustly in a wide range of real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
SPVLoc: Semantic Panoramic Viewport Matching for 6D Camera Localization in Unseen Environments
Niklas Gard, Anna Hilsmann, Peter Eisert
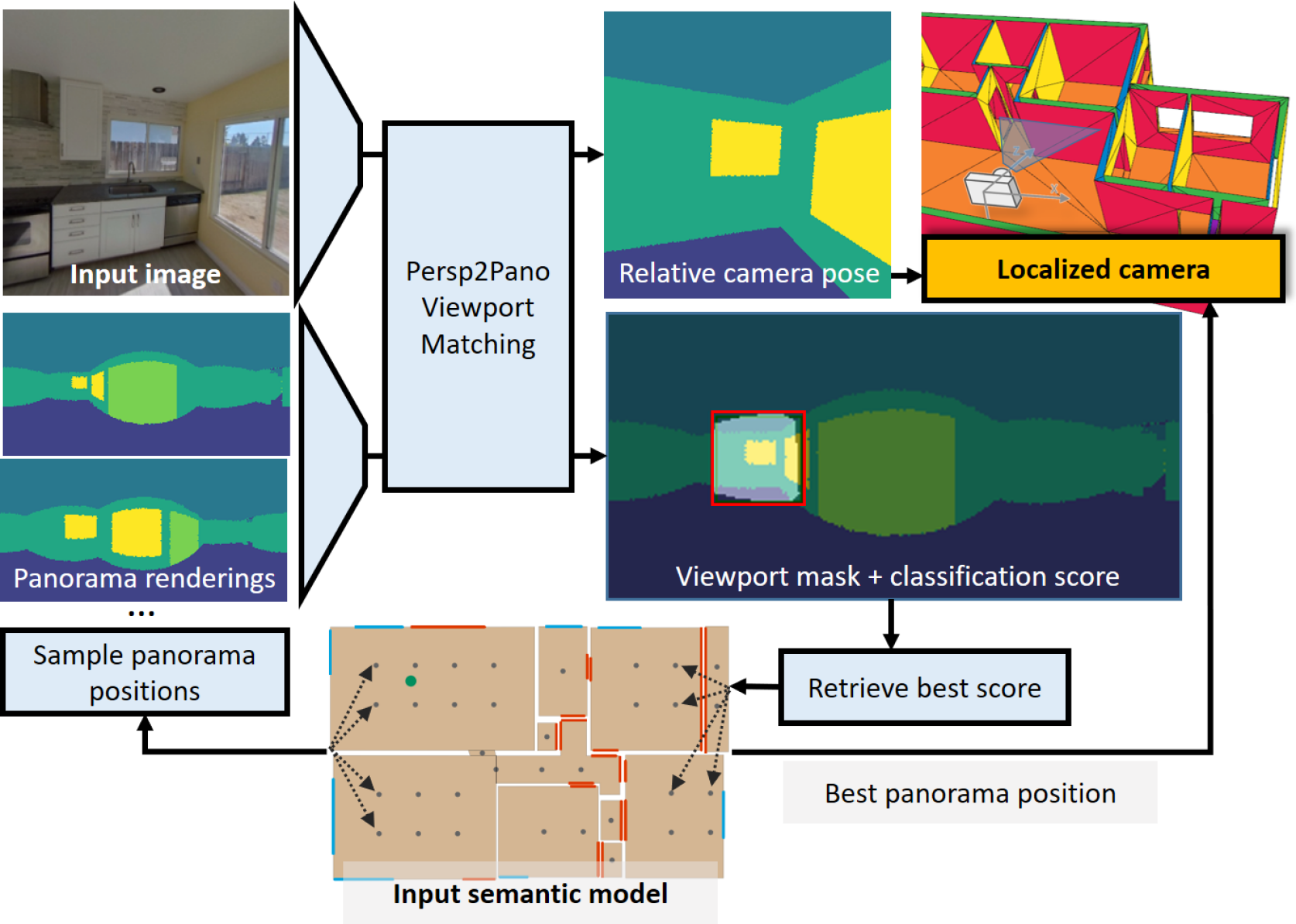
In this paper, we present SPVLoc, a global indoor localization method that accurately determines the six-dimensional (6D) camera pose of a query image and requires minimal scene-specific prior knowledge and no scene-specific training. Our approach employs a novel matching procedure to localize the perspective camera's viewport, given as an RGB image, within a set of panoramic semantic layout representations of the indoor environment. The panoramas are rendered from an untextured 3D reference model, which only comprises approximate structural information about room shapes, along with door and window annotations. We demonstrate that a straightforward convolutional network structure can successfully achieve image-to-panorama and ultimately image-to-model matching. Through a viewport classification score, we rank reference panoramas and select the best match for the query image. Then, a 6D relative pose is estimated between the chosen panorama and query image. Our experiments demonstrate that this approach not only efficiently bridges the domain gap but also generalizes well to previously unseen scenes that are not part of the training data. Moreover, it achieves superior localization accuracy compared to the state of the art methods and also estimates more degrees of freedom of the camera pose. Our source code is publicly available at https://fraunhoferhhi.github.io/spvloc .
Read more7/23/2024
0
Fully Geometric Panoramic Localization
Junho Kim, Jiwon Jeong, Young Min Kim
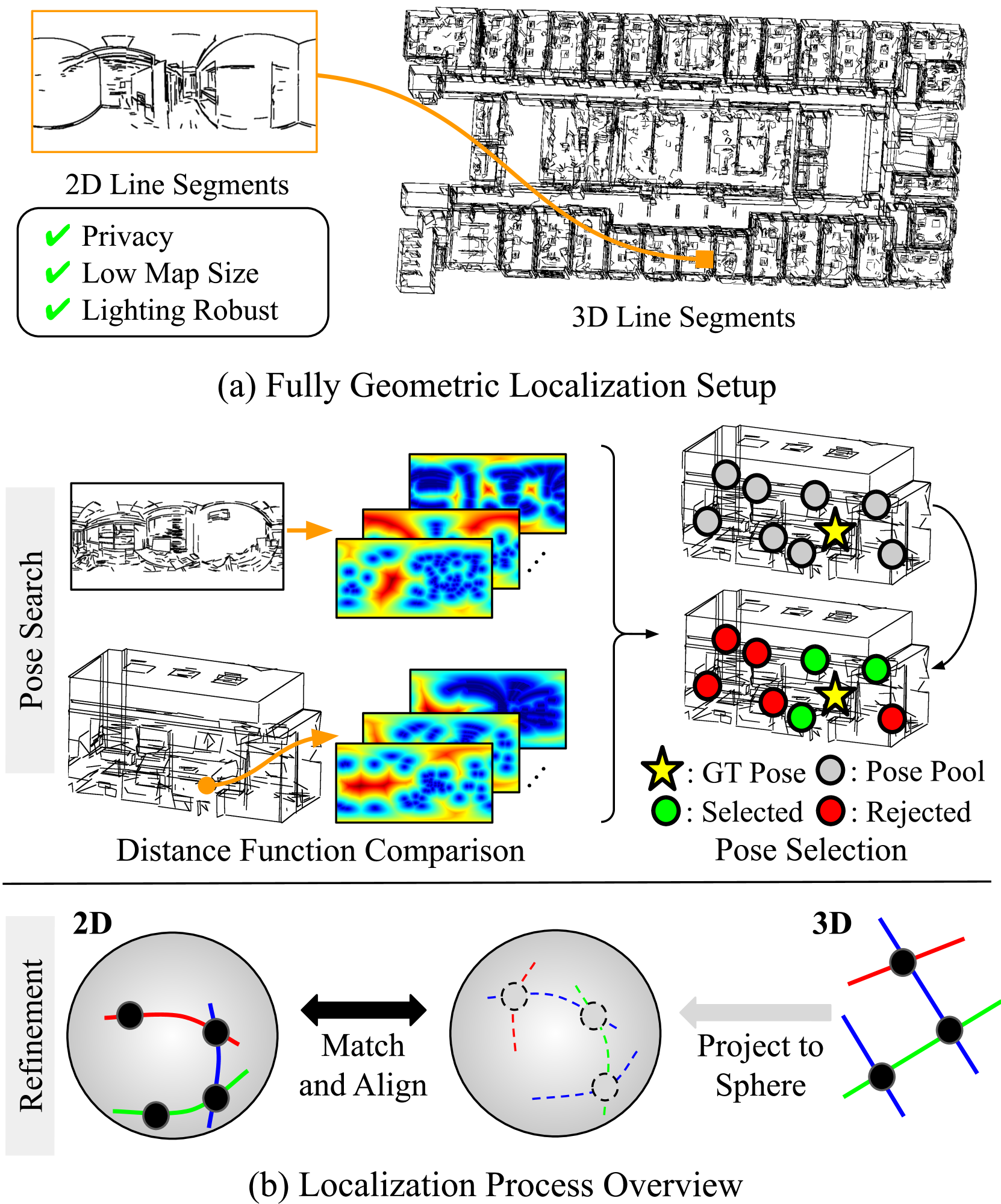
We introduce a lightweight and accurate localization method that only utilizes the geometry of 2D-3D lines. Given a pre-captured 3D map, our approach localizes a panorama image, taking advantage of the holistic 360 view. The system mitigates potential privacy breaches or domain discrepancies by avoiding trained or hand-crafted visual descriptors. However, as lines alone can be ambiguous, we express distinctive yet compact spatial contexts from relationships between lines, namely the dominant directions of parallel lines and the intersection between non-parallel lines. The resulting representations are efficient in processing time and memory compared to conventional visual descriptor-based methods. Given the groups of dominant line directions and their intersections, we accelerate the search process to test thousands of pose candidates in less than a millisecond without sacrificing accuracy. We empirically show that the proposed 2D-3D matching can localize panoramas for challenging scenes with similar structures, dramatic domain shifts or illumination changes. Our fully geometric approach does not involve extensive parameter tuning or neural network training, making it a practical algorithm that can be readily deployed in the real world. Project page including the code is available through this link: https://82magnolia.github.io/fgpl/.
Read more4/1/2024

0
Cross-view image geo-localization with Panorama-BEV Co-Retrieval Network
Junyan Ye, Zhutao Lv, Weijia Li, Jinhua Yu, Haote Yang, Huaping Zhong, Conghui He
Cross-view geolocalization identifies the geographic location of street view images by matching them with a georeferenced satellite database. Significant challenges arise due to the drastic appearance and geometry differences between views. In this paper, we propose a new approach for cross-view image geo-localization, i.e., the Panorama-BEV Co-Retrieval Network. Specifically, by utilizing the ground plane assumption and geometric relations, we convert street view panorama images into the BEV view, reducing the gap between street panoramas and satellite imagery. In the existing retrieval of street view panorama images and satellite images, we introduce BEV and satellite image retrieval branches for collaborative retrieval. By retaining the original street view retrieval branch, we overcome the limited perception range issue of BEV representation. Our network enables comprehensive perception of both the global layout and local details around the street view capture locations. Additionally, we introduce CVGlobal, a global cross-view dataset that is closer to real-world scenarios. This dataset adopts a more realistic setup, with street view directions not aligned with satellite images. CVGlobal also includes cross-regional, cross-temporal, and street view to map retrieval tests, enabling a comprehensive evaluation of algorithm performance. Our method excels in multiple tests on common cross-view datasets such as CVUSA, CVACT, VIGOR, and our newly introduced CVGlobal, surpassing the current state-of-the-art approaches. The code and datasets can be found at url{https://github.com/yejy53/EP-BEV}.
Read more8/13/2024
0
SALVe: Semantic Alignment Verification for Floorplan Reconstruction from Sparse Panoramas
John Lambert, Yuguang Li, Ivaylo Boyadzhiev, Lambert Wixson, Manjunath Narayana, Will Hutchcroft, James Hays, Frank Dellaert, Sing Bing Kang
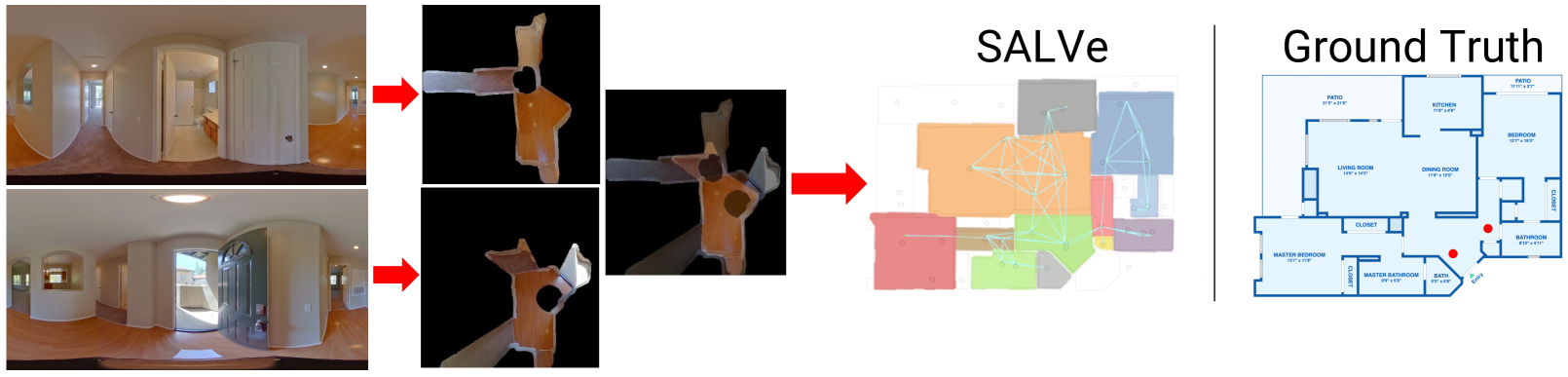
We propose a new system for automatic 2D floorplan reconstruction that is enabled by SALVe, our novel pairwise learned alignment verifier. The inputs to our system are sparsely located 360$^circ$ panoramas, whose semantic features (windows, doors, and openings) are inferred and used to hypothesize pairwise room adjacency or overlap. SALVe initializes a pose graph, which is subsequently optimized using GTSAM. Once the room poses are computed, room layouts are inferred using HorizonNet, and the floorplan is constructed by stitching the most confident layout boundaries. We validate our system qualitatively and quantitatively as well as through ablation studies, showing that it outperforms state-of-the-art SfM systems in completeness by over 200%, without sacrificing accuracy. Our results point to the significance of our work: poses of 81% of panoramas are localized in the first 2 connected components (CCs), and 89% in the first 3 CCs. Code and models are publicly available at https://github.com/zillow/salve.
Read more6/28/2024