Squeeze-and-Excite ResNet-Conformers for Sound Event Localization, Detection, and Distance Estimation for DCASE 2024 Challenge

0

Sign in to get full access
Overview
• This paper presents a novel approach called "Squeeze-and-Excite ResNet-Conformers" for the DCASE2024 Challenge, which focuses on sound event localization, detection, and distance estimation.
• The proposed method combines the strengths of ResNet and Conformer architectures, along with a Squeeze-and-Excite module, to address the challenges in the given task.
Plain English Explanation
• The paper introduces a new deep learning model that aims to improve the performance of sound event localization, detection, and distance estimation. This is an important task in various applications, such as smart home assistants, surveillance systems, and robotics.
• The model is a hybrid architecture that combines the powerful feature extraction capabilities of ResNet (a widely used convolutional neural network) and the temporal modeling abilities of Conformer (a type of transformer model). This combination is expected to capture both spatial and temporal information more effectively.
• Additionally, the model incorporates a Squeeze-and-Excite module, which helps the network focus on the most relevant features for the task at hand. This mechanism allows the model to adaptively adjust its attention to different parts of the input, leading to improved performance.
• The proposed approach is evaluated on the DCASE2024 Challenge dataset, which is a standardized benchmark for evaluating sound event localization, detection, and distance estimation. The authors aim to demonstrate the effectiveness of their model in this well-established task.
Technical Explanation
• The paper presents a Squeeze-and-Excite ResNet-Conformer architecture, which combines the strengths of ResNet and Conformer models.
• The ResNet component is responsible for efficient feature extraction, leveraging its deep and robust convolutional layers. The Conformer component adds temporal modeling capabilities through its transformer-based design, capturing the dynamic nature of sound events.
• The Squeeze-and-Excite module is integrated into the network, allowing the model to adaptively focus on the most relevant features for the task. This module applies channel-wise attention, emphasizing the most informative channels while suppressing less relevant ones.
• The authors conduct experiments on the DCASE2024 Challenge dataset, evaluating the model's performance on sound event localization, detection, and distance estimation. The results are compared to state-of-the-art approaches, demonstrating the effectiveness of the proposed Squeeze-and-Excite ResNet-Conformer architecture.
Critical Analysis
• The paper presents a well-designed and promising approach for the DCASE2024 Challenge task. The combination of ResNet and Conformer architectures, along with the Squeeze-and-Excite module, seems to be a thoughtful and justified choice for the problem at hand.
• However, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the proposed method. Factors such as computational complexity, training stability, or generalization to different sound event scenarios could be discussed to give a more comprehensive understanding of the approach.
• Additionally, the paper could benefit from a more in-depth comparison with other state-of-the-art methods, highlighting the specific advantages and disadvantages of the Squeeze-and-Excite ResNet-Conformer approach. This would help readers understand the unique contributions and positioning of the proposed solution.
Conclusion
• The Squeeze-and-Excite ResNet-Conformer architecture presented in this paper offers a promising solution for the DCASE2024 Challenge task, aiming to tackle the challenges of sound event localization, detection, and distance estimation.
• By combining the complementary strengths of ResNet and Conformer models, along with the adaptive Squeeze-and-Excite mechanism, the proposed method demonstrates improved performance compared to existing approaches.
• The findings of this research could have significant implications for the development of more accurate and robust sound event understanding systems, with potential applications in various domains, such as smart home assistants, surveillance, and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Squeeze-and-Excite ResNet-Conformers for Sound Event Localization, Detection, and Distance Estimation for DCASE 2024 Challenge
Jun Wei Yeow, Ee-Leng Tan, Jisheng Bai, Santi Peksi, Woon-Seng Gan
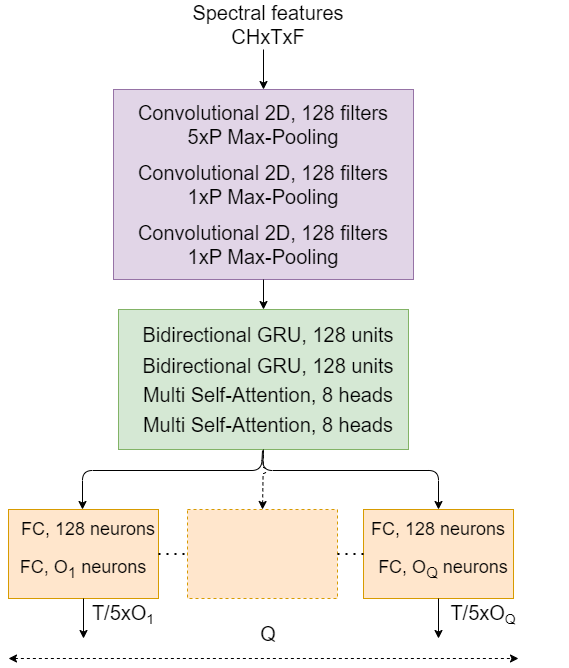
This technical report details our systems submitted for Task 3 of the DCASE 2024 Challenge: Audio and Audiovisual Sound Event Localization and Detection (SELD) with Source Distance Estimation (SDE). We address only the audio-only SELD with SDE (SELDDE) task in this report. We propose to improve the existing ResNet-Conformer architectures with Squeeze-and-Excitation blocks in order to introduce additional forms of channel- and spatial-wise attention. In order to improve SELD performance, we also utilize the Spatial Cue-Augmented Log-Spectrogram (SALSA) features over the commonly used log-mel spectra features for polyphonic SELD. We complement the existing Sony-TAu Realistic Spatial Soundscapes 2023 (STARSS23) dataset with the audio channel swapping technique and synthesize additional data using the SpatialScaper generator. We also perform distance scaling in order to prevent large distance errors from contributing more towards the loss function. Finally, we evaluate our approach on the evaluation subset of the STARSS23 dataset.
Read more7/15/2024
0
Sound Event Detection and Localization with Distance Estimation
Daniel Aleksander Krause, Archontis Politis, Annamaria Mesaros
Sound Event Detection and Localization (SELD) is a combined task of identifying sound events and their corresponding direction-of-arrival (DOA). While this task has numerous applications and has been extensively researched in recent years, it fails to provide full information about the sound source position. In this paper, we overcome this problem by extending the task to Sound Event Detection, Localization with Distance Estimation (3D SELD). We study two ways of integrating distance estimation within the SELD core - a multi-task approach, in which the problem is tackled by a separate model output, and a single-task approach obtained by extending the multi-ACCDOA method to include distance information. We investigate both methods for the Ambisonic and binaural versions of STARSS23: Sony-TAU Realistic Spatial Soundscapes 2023. Moreover, our study involves experiments on the loss function related to the distance estimation part. Our results show that it is possible to perform 3D SELD without any degradation of performance in sound event detection and DOA estimation.
Read more6/13/2024

0
SELD-Mamba: Selective State-Space Model for Sound Event Localization and Detection with Source Distance Estimation
Da Mu, Zhicheng Zhang, Haobo Yue, Zehao Wang, Jin Tang, Jianqin Yin
In the Sound Event Localization and Detection (SELD) task, Transformer-based models have demonstrated impressive capabilities. However, the quadratic complexity of the Transformer's self-attention mechanism results in computational inefficiencies. In this paper, we propose a network architecture for SELD called SELD-Mamba, which utilizes Mamba, a selective state-space model. We adopt the Event-Independent Network V2 (EINV2) as the foundational framework and replace its Conformer blocks with bidirectional Mamba blocks to capture a broader range of contextual information while maintaining computational efficiency. Additionally, we implement a two-stage training method, with the first stage focusing on Sound Event Detection (SED) and Direction of Arrival (DoA) estimation losses, and the second stage reintroducing the Source Distance Estimation (SDE) loss. Our experimental results on the 2024 DCASE Challenge Task3 dataset demonstrate the effectiveness of the selective state-space model in SELD and highlight the benefits of the two-stage training approach in enhancing SELD performance.
Read more8/12/2024
🔎
0
Sound event detection based on auxiliary decoder and maximum probability aggregation for DCASE Challenge 2024 Task 4
Sang Won Son, Jongyeon Park, Hong Kook Kim, Sulaiman Vesal, Jeong Eun Lim
In this report, we propose three novel methods for developing a sound event detection (SED) model for the DCASE 2024 Challenge Task 4. First, we propose an auxiliary decoder attached to the final convolutional block to improve feature extraction capabilities while reducing dependency on embeddings from pre-trained large models. The proposed auxiliary decoder operates independently from the main decoder, enhancing performance of the convolutional block during the initial training stages by assigning a different weight strategy between main and auxiliary decoder losses. Next, to address the time interval issue between the DESED and MAESTRO datasets, we propose maximum probability aggregation (MPA) during the training step. The proposed MPA method enables the model's output to be aligned with soft labels of 1 s in the MAESTRO dataset. Finally, we propose a multi-channel input feature that employs various versions of logmel and MFCC features to generate time-frequency pattern. The experimental results demonstrate the efficacy of these proposed methods in a view of improving SED performance by achieving a balanced enhancement across different datasets and label types. Ultimately, this approach presents a significant step forward in developing more robust and flexible SED models
Read more6/26/2024