Stabilizing Estimates of Shapley Values with Control Variates

0
↗️
Sign in to get full access
Overview
- Shapley values are a popular tool for explaining predictions of complex machine learning models.
- However, their high computational cost often requires using sampling approximations, which can introduce significant uncertainty.
- This paper proposes an approach called ControlSHAP that uses a Monte Carlo technique called control variates to stabilize these Shapley value estimates.
- ControlSHAP can be applied to any machine learning model and requires minimal extra computation or modeling effort.
- The authors find that ControlSHAP can dramatically reduce the Monte Carlo variability of Shapley value estimates on several high-dimensional datasets.
Plain English Explanation
Machine learning models, especially complex "black box" ones, can be difficult to understand. Shapley values are a popular way to explain the predictions of these models by breaking down the contribution of each input feature. However, calculating exact Shapley values is computationally expensive, so researchers often use sampling approximations instead.
The problem is that these sampling-based Shapley value estimates can be quite uncertain and unstable. This paper introduces a new technique called ControlSHAP that uses a statistical method called control variates to make the Shapley value estimates more reliable and consistent. ControlSHAP can be applied to any machine learning model without requiring much additional work.
The key idea behind ControlSHAP is to use information about the machine learning model, like how sensitive the predictions are to each input, to help "control" or stabilize the Shapley value estimates. The authors show that this approach can dramatically reduce the variability in the Shapley value estimates, making the explanations much more trustworthy.
This is important because being able to reliably explain complex machine learning models is crucial for building trust, debugging issues, and deploying these models responsibly in high-stakes applications like healthcare or finance. ControlSHAP provides a simple yet powerful way to improve the quality of these model explanations.
Technical Explanation
The paper proposes a new approach called ControlSHAP to stabilize the Shapley value estimates used to explain the predictions of complex machine learning models. Shapley values are a popular technique for model interpretability, but their high computational cost often requires using sampling approximations, which can introduce significant uncertainty.
ControlSHAP uses the statistical technique of control variates from the Monte Carlo literature to reduce the variance of these Shapley value estimates. The key idea is to leverage additional information about the machine learning model, such as the gradients of the predictions with respect to the inputs, to construct a control variate that is correlated with the Shapley value but cheaper to compute.
The authors show that ControlSHAP can be applied to any differentiable machine learning model with minimal extra computation or modeling effort. On several high-dimensional datasets, they demonstrate that ControlSHAP can achieve dramatic reductions in the Monte Carlo variability of the Shapley value estimates compared to standard sampling approaches.
Critical Analysis
The ControlSHAP method proposed in this paper represents a significant advance in stabilizing the Shapley value explanations of complex machine learning models. The authors have provided a well-designed and rigorous evaluation of their approach, showing clear improvements over existing sampling-based Shapley value estimation techniques.
That said, the paper does acknowledge some limitations of the ControlSHAP method. Firstly, it requires the machine learning model to be differentiable, which may not always be the case, especially for more complex models like decision trees or neural networks with non-smooth activation functions. The authors suggest exploring alternative control variate constructions to address this limitation.
Additionally, the paper focuses on reducing the variance of the Shapley value estimates, but does not explicitly consider the potential for bias introduced by the control variate approach. Further research may be needed to fully characterize the bias-variance tradeoffs of ControlSHAP compared to other Shapley value estimation methods.
Overall, this paper makes a valuable contribution to the field of interpretable machine learning by providing a practical and effective technique for stabilizing Shapley value explanations. The ControlSHAP method represents an important step forward in making complex models more transparent and trustworthy.
Conclusion
This paper introduces ControlSHAP, a new approach for stabilizing the Shapley value explanations of complex machine learning models. Shapley values are a popular tool for interpreting model predictions, but their high computational cost often requires using sampling approximations that can introduce significant uncertainty.
ControlSHAP leverages the technique of control variates from the Monte Carlo literature to dramatically reduce the variability in these Shapley value estimates. The method can be applied to any differentiable machine learning model with minimal extra effort, and the authors demonstrate its effectiveness on several high-dimensional datasets.
By improving the reliability and consistency of Shapley value explanations, ControlSHAP represents an important advance in making complex machine learning models more transparent and trustworthy. This is especially crucial for deploying these models in high-stakes applications where being able to understand and audit their behavior is of paramount importance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
↗️
0
Stabilizing Estimates of Shapley Values with Control Variates
Jeremy Goldwasser, Giles Hooker
Shapley values are among the most popular tools for explaining predictions of blackbox machine learning models. However, their high computational cost motivates the use of sampling approximations, inducing a considerable degree of uncertainty. To stabilize these model explanations, we propose ControlSHAP, an approach based on the Monte Carlo technique of control variates. Our methodology is applicable to any machine learning model and requires virtually no extra computation or modeling effort. On several high-dimensional datasets, we find it can produce dramatic reductions in the Monte Carlo variability of Shapley estimates.
Read more4/11/2024
🌿
0
Fast Shapley Value Estimation: A Unified Approach
Borui Zhang, Baotong Tian, Wenzhao Zheng, Jie Zhou, Jiwen Lu
Shapley values have emerged as a widely accepted and trustworthy tool, grounded in theoretical axioms, for addressing challenges posed by black-box models like deep neural networks. However, computing Shapley values encounters exponential complexity as the number of features increases. Various approaches, including ApproSemivalue, KernelSHAP, and FastSHAP, have been explored to expedite the computation. In our analysis of existing approaches, we observe that stochastic estimators can be unified as a linear transformation of randomly summed values from feature subsets. Based on this, we investigate the possibility of designing simple amortized estimators and propose a straightforward and efficient one, SimSHAP, by eliminating redundant techniques. Extensive experiments conducted on tabular and image datasets validate the effectiveness of our SimSHAP, which significantly accelerates the computation of accurate Shapley values.
Read more5/24/2024

0
Shapley Marginal Surplus for Strong Models
Daniel de Marchi, Michael Kosorok, Scott de Marchi
Shapley values have seen widespread use in machine learning as a way to explain model predictions and estimate the importance of covariates. Accurately explaining models is critical in real-world models to both aid in decision making and to infer the properties of the true data-generating process (DGP). In this paper, we demonstrate that while model-based Shapley values might be accurate explainers of model predictions, machine learning models themselves are often poor explainers of the DGP even if the model is highly accurate. Particularly in the presence of interrelated or noisy variables, the output of a highly predictive model may fail to account for these relationships. This implies explanations of a trained model's behavior may fail to provide meaningful insight into the DGP. In this paper we introduce a novel variable importance algorithm, Shapley Marginal Surplus for Strong Models, that samples the space of possible models to come up with an inferential measure of feature importance. We compare this method to other popular feature importance methods, both Shapley-based and non-Shapley based, and demonstrate significant outperformance in inferential capabilities relative to other methods.
Read more8/19/2024
0
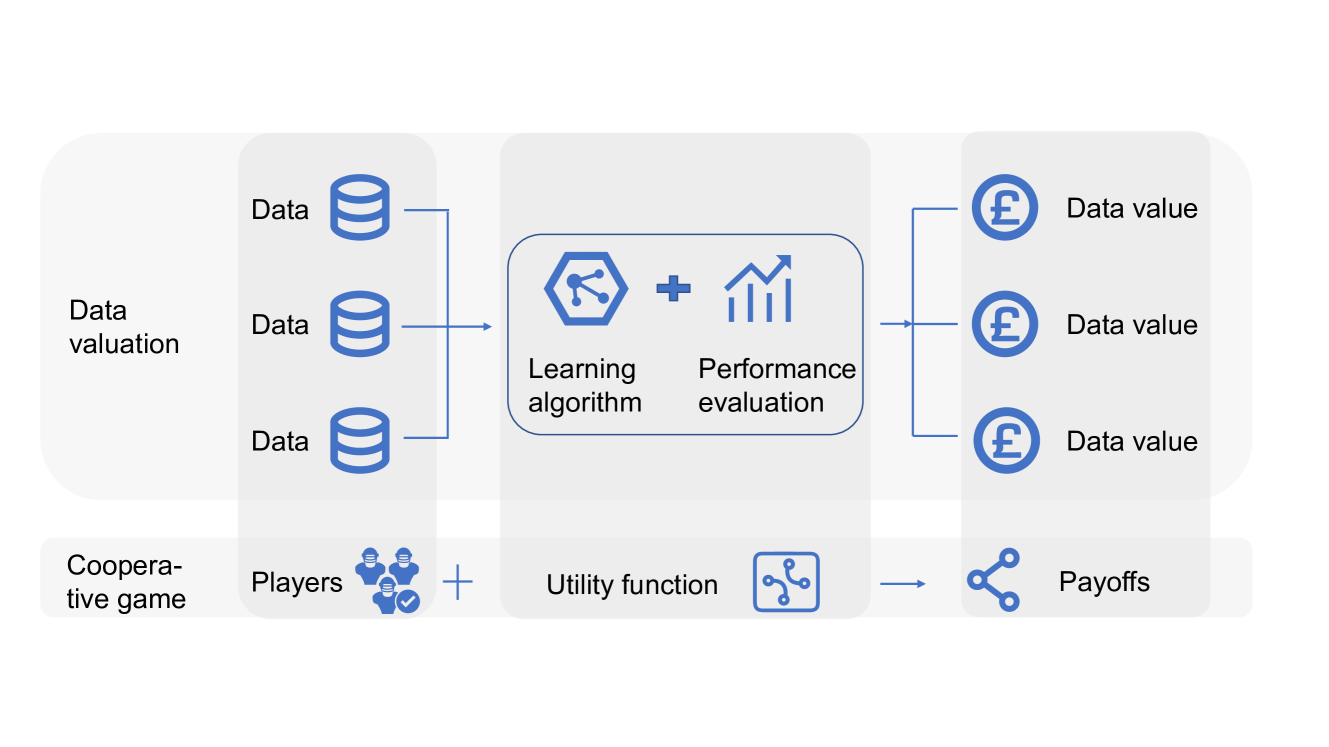
Uncertainty Quantification of Data Shapley via Statistical Inference
Mengmeng Wu, Zhihong Liu, Xiang Li, Ruoxi Jia, Xiangyu Chang
As data plays an increasingly pivotal role in decision-making, the emergence of data markets underscores the growing importance of data valuation. Within the machine learning landscape, Data Shapley stands out as a widely embraced method for data valuation. However, a limitation of Data Shapley is its assumption of a fixed dataset, contrasting with the dynamic nature of real-world applications where data constantly evolves and expands. This paper establishes the relationship between Data Shapley and infinite-order U-statistics and addresses this limitation by quantifying the uncertainty of Data Shapley with changes in data distribution from the perspective of U-statistics. We make statistical inferences on data valuation to obtain confidence intervals for the estimations. We construct two different algorithms to estimate this uncertainty and provide recommendations for their applicable situations. We also conduct a series of experiments on various datasets to verify asymptotic normality and propose a practical trading scenario enabled by this method.
Read more7/30/2024