Stateful Large Language Model Serving with Pensieve

0
Sign in to get full access
Overview
- This paper introduces Pensieve, a system for efficiently serving stateful large language models (LLMs) with long-context inputs.
- Pensieve addresses challenges in serving LLMs, such as managing the large memory requirements and slow inference speeds, by leveraging techniques like attention store and memory sharing.
- The authors demonstrate the effectiveness of Pensieve on various benchmarks, showing significant improvements in latency and memory usage compared to traditional approaches.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, serving these models efficiently can be a challenge, especially when dealing with long input contexts.
The Pensieve system addresses this challenge by using innovative techniques to manage the memory and speed requirements of LLMs. It leverages ideas like "attention store," which allows the model to reuse past attention information, and "memory sharing," which enables multiple LLM-based agents to efficiently share their memory.
By applying these and other optimizations, Pensieve is able to serve LLMs much more quickly and with lower memory usage than traditional approaches. This makes it easier to deploy these powerful models in real-world applications, where fast and efficient performance is essential.
Technical Explanation
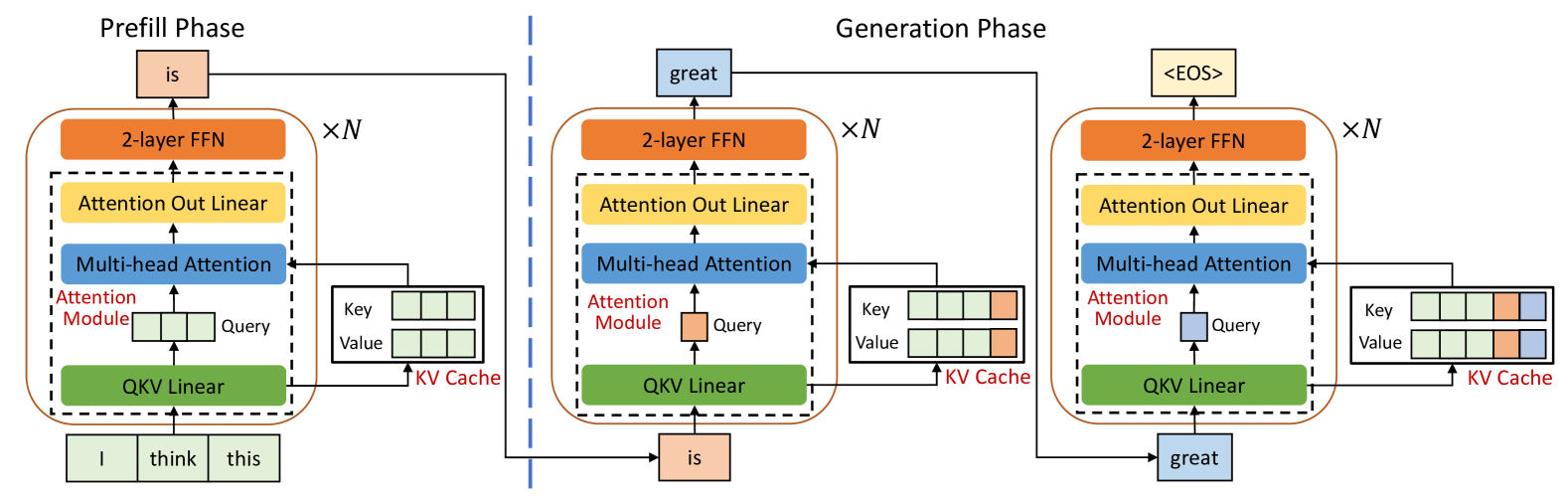
The paper first provides background on LLMs and the attention mechanism, which is a key component of these models. The attention mechanism allows LLMs to focus on the most relevant parts of their input when generating output, but this can also be computationally expensive.
To address the challenges of serving LLMs, the authors introduce the Pensieve system. Pensieve uses a few key techniques:
-
Attention Store: Pensieve stores the attention weights from previous model invocations, allowing it to reuse this information and avoid the need to recompute attention for identical inputs. This is described in more detail in the AttentionStore paper.
-
Memory Sharing: Pensieve enables multiple LLM-based agents to efficiently share their memory, reducing the overall memory footprint. This is covered in the Memory Sharing paper.
-
Long-Context Serving: Pensieve is designed to handle long input contexts, which can be a challenge for traditional LLM serving approaches. It uses techniques like LoongServe to optimize performance in these cases.
The paper evaluates Pensieve on several benchmarks, demonstrating significant improvements in latency and memory usage compared to baseline approaches. For example, Pensieve is able to achieve up to 10x lower latency and 5x lower memory usage on certain tasks.
Critical Analysis
The Pensieve paper presents a novel and promising approach to serving stateful LLMs efficiently. The key techniques, such as attention store and memory sharing, appear to be well-designed and effectively address important challenges in this domain.
However, the paper does not explore the potential limitations or downsides of these approaches. For example, the authors do not discuss the impact of attention store on model accuracy or the trade-offs involved in memory sharing. Additionally, the evaluation is limited to a few specific benchmarks, and it would be valuable to see how Pensieve performs on a wider range of tasks and real-world applications.
Furthermore, the paper does not address potential ethical considerations around the deployment of powerful LLMs, such as issues of bias, transparency, or misuse. As these models become more prevalent, it will be important for the research community to consider these broader societal implications.
Overall, the Pensieve system represents an important step forward in making LLMs more practical and accessible. However, further research and analysis would be beneficial to fully understand the capabilities, limitations, and implications of this approach.
Conclusion
The Pensieve paper introduces a novel system for efficiently serving stateful large language models with long-context inputs. By leveraging techniques like attention store and memory sharing, Pensieve is able to significantly improve the latency and memory usage of LLM serving, making these powerful models more practical for real-world applications.
The key innovations and insights presented in this paper could have a significant impact on the field of large language models, enabling faster and more resource-efficient deployment of these transformative AI systems. As the research and development in this area continues, it will be important to also consider the broader societal implications and challenges associated with the use of LLMs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Stateful Large Language Model Serving with Pensieve
Lingfan Yu, Jinyang Li
Large Language Models (LLMs) are wildly popular today and it is important to serve them efficiently. Existing LLM serving systems are stateless across requests. Consequently, when LLMs are used in the common setting of multi-turn conversations, a growing log of the conversation history must be processed alongside any request by the serving system at each turn, resulting in repeated processing. In this paper, we design Pensieve, a system optimized for multi-turn conversation LLM serving. Pensieve maintains the conversation state across requests by caching previously processed history to avoid duplicate processing. Pensieve's multi-tier caching strategy can utilize both GPU and CPU memory to efficiently store and retrieve cached data. Pensieve also generalizes the recent PagedAttention kernel to support attention between multiple input tokens with a GPU cache spread over non-contiguous memory. Our evaluation shows that Pensieve can achieve 13-58% more throughput compared to vLLM and TensorRT-LLM and significantly reduce latency.
Read more5/29/2024

0
vTensor: Flexible Virtual Tensor Management for Efficient LLM Serving
Jiale Xu, Rui Zhang, Cong Guo, Weiming Hu, Zihan Liu, Feiyang Wu, Yu Feng, Shixuan Sun, Changxu Shao, Yuhong Guo, Junping Zhao, Ke Zhang, Minyi Guo, Jingwen Leng
Large Language Models (LLMs) are widely used across various domains, processing millions of daily requests. This surge in demand poses significant challenges in optimizing throughput and latency while keeping costs manageable. The Key-Value (KV) cache, a standard method for retaining previous computations, makes LLM inference highly bounded by memory. While batching strategies can enhance performance, they frequently lead to significant memory fragmentation. Even though cutting-edge systems like vLLM mitigate KV cache fragmentation using paged Attention mechanisms, they still suffer from inefficient memory and computational operations due to the tightly coupled page management and computation kernels. This study introduces the vTensor, an innovative tensor structure for LLM inference based on GPU virtual memory management (VMM). vTensor addresses existing limitations by decoupling computation from memory defragmentation and offering dynamic extensibility. Our framework employs a CPU-GPU heterogeneous approach, ensuring efficient, fragmentation-free memory management while accommodating various computation kernels across different LLM architectures. Experimental results indicate that vTensor achieves an average speedup of 1.86x across different models, with up to 2.42x in multi-turn chat scenarios. Additionally, vTensor provides average speedups of 2.12x and 3.15x in kernel evaluation, reaching up to 3.92x and 3.27x compared to SGLang Triton prefix-prefilling kernels and vLLM paged Attention kernel, respectively. Furthermore, it frees approximately 71.25% (57GB) of memory on the NVIDIA A100 GPU compared to vLLM, enabling more memory-intensive workloads.
Read more7/23/2024

0
Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, Wei Lin
Large Language Models (LLMs) demonstrate substantial potential across a diverse array of domains via request serving. However, as trends continue to push for expanding context sizes, the autoregressive nature of LLMs results in highly dynamic behavior of the attention layers, showcasing significant differences in computational characteristics and memory requirements from the non-attention layers. This presents substantial challenges for resource management and performance optimization in service systems. Existing static model parallelism and resource allocation strategies fall short when dealing with this dynamicity. To address the issue, we propose Infinite-LLM, a novel LLM serving system designed to effectively handle dynamic context lengths. Infinite-LLM disaggregates attention layers from an LLM's inference process, facilitating flexible and independent resource scheduling that optimizes computational performance and enhances memory utilization jointly. By leveraging a pooled GPU memory strategy across a cluster, Infinite-LLM not only significantly boosts system throughput but also supports extensive context lengths. Evaluated on a dataset with context lengths ranging from a few to 2000K tokens across a cluster with 32 A100 GPUs, Infinite-LLM demonstrates throughput improvement of 1.35-3.4x compared to state-of-the-art methods, enabling efficient and elastic LLM deployment.
Read more7/8/2024
0
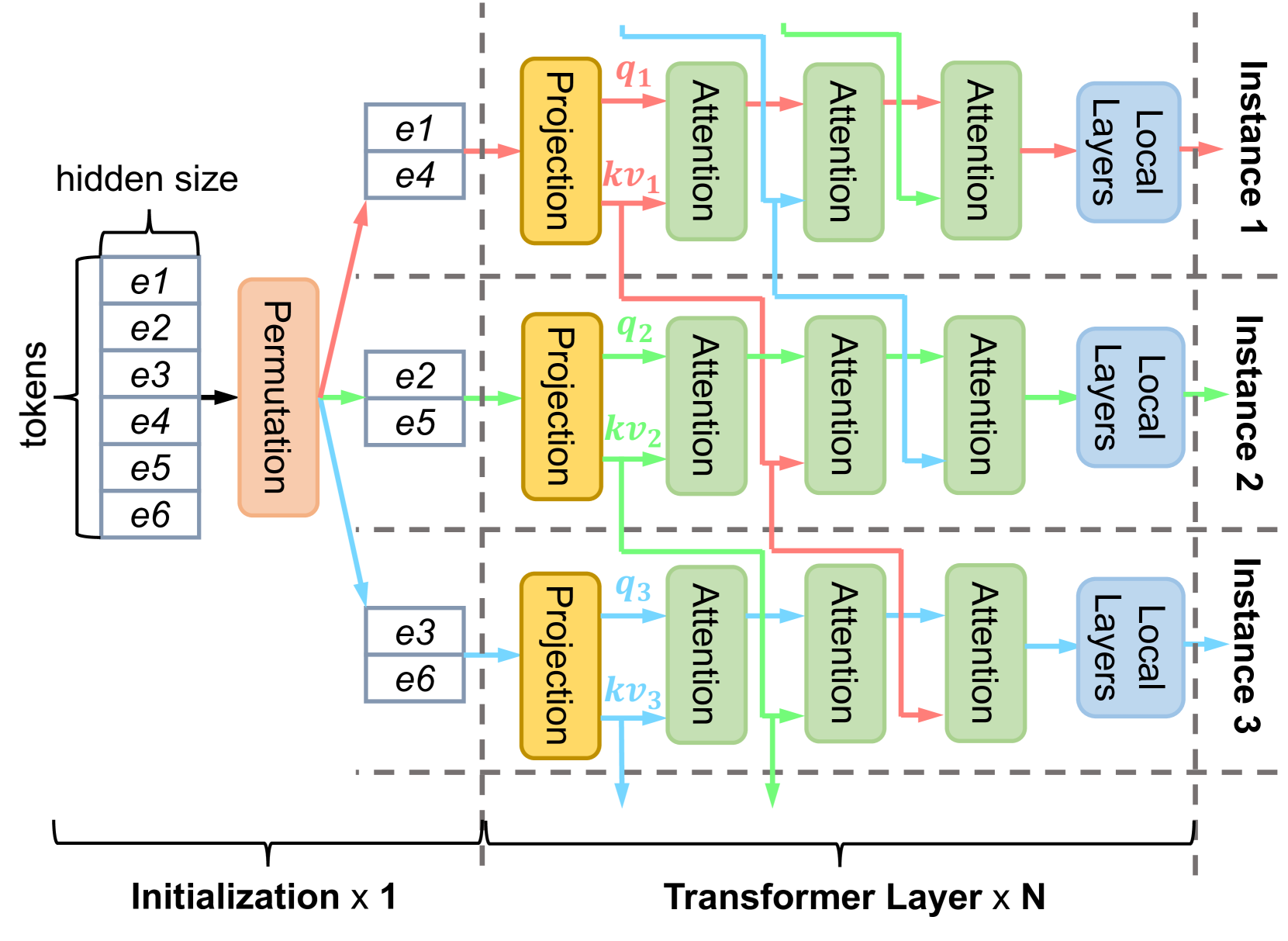
LoongServe: Efficiently Serving Long-context Large Language Models with Elastic Sequence Parallelism
Bingyang Wu, Shengyu Liu, Yinmin Zhong, Peng Sun, Xuanzhe Liu, Xin Jin
The context window of large language models (LLMs) is rapidly increasing, leading to a huge variance in resource usage between different requests as well as between different phases of the same request. Restricted by static parallelism strategies, existing LLM serving systems cannot efficiently utilize the underlying resources to serve variable-length requests in different phases. To address this problem, we propose a new parallelism paradigm, elastic sequence parallelism (ESP), to elastically adapt to the variance between different requests and phases. Based on ESP, we design and build LoongServe, an LLM serving system that (1) improves computation efficiency by elastically adjusting the degree of parallelism in real-time, (2) improves communication efficiency by reducing key-value cache migration overhead and overlapping partial decoding communication with computation, and (3) improves GPU memory efficiency by reducing key-value cache fragmentation across instances. Our evaluation under diverse real-world datasets shows that LoongServe improves the maximum throughput by up to 3.85$times$ compared to the chunked prefill and 5.81$times$ compared to the prefill-decoding disaggregation.
Read more4/16/2024