STLLaVA-Med: Self-Training Large Language and Vision Assistant for Medical

0

Sign in to get full access
Overview
- The paper introduces "STLLaVA-Med", a large language and vision model trained for medical applications using self-supervised learning techniques.
- STLLaVA-Med aims to advance the state-of-the-art in high-resolution vision-language models for biomedicine, building on recent progress in vision-language models for medical report generation and injecting medical visual knowledge.
- The model is designed to be adaptable to various medical tasks, like learning to adapt large vision-language models for surgical applications.
Plain English Explanation
The paper introduces a new "assistant" model called STLLaVA-Med that is trained to understand and work with both language and visual information, with a focus on medical applications. This model builds on recent advances in vision-language models that can process both text and images, as well as work that has looked at injecting medical knowledge into these types of models.
The goal of STLLaVA-Med is to create a versatile tool that can be adapted to tackle various medical tasks, similar to how large vision-language models have been adapted for surgical applications. This could include things like automatically generating medical reports based on medical images, or assisting clinicians by answering questions about medical conditions and treatments.
The key innovation in this work is the use of self-supervised learning techniques to train the STLLaVA-Med model on a large amount of medical data, allowing it to learn general medical knowledge and skills without being explicitly programmed for specific tasks. This "self-training" approach is meant to make the model more adaptable and powerful than models trained on a narrow set of tasks.
Technical Explanation
The paper proposes a new self-training approach for building a large language and vision model called "STLLaVA-Med" that is tailored for medical applications. The model is designed to advance the state-of-the-art in high-resolution vision-language models for biomedicine, building on recent progress in vision-language models for medical report generation and injecting medical visual knowledge.
The self-training approach involves first pre-training the model on a large corpus of general text and image data using self-supervised objectives like masked language modeling and contrastive image-text matching. The model is then further fine-tuned on medical-specific datasets through an iterative process of prediction, self-labeling, and re-training. This allows the model to learn general medical knowledge and skills in a data-efficient manner.
The resulting STLLaVA-Med model is designed to be adaptable to a variety of medical tasks, similar to how large vision-language models have been adapted for surgical applications. Experiments demonstrate the model's strong performance on benchmarks for medical image captioning, visual question answering, and other medical language understanding tasks.
Critical Analysis
The paper presents a promising approach for building a versatile medical language and vision model through self-supervised pre-training and iterative fine-tuning. However, the authors acknowledge several caveats and limitations that warrant further investigation.
One potential issue is the reliance on large-scale medical datasets, which may be difficult to obtain or curate, especially for sensitive clinical data. The authors note that data privacy and ethical considerations will be crucial in deploying such models in real-world medical settings.
Additionally, while the self-training approach aims to make the model more adaptable, the authors do not provide extensive evaluation of the model's transfer learning capabilities across diverse medical tasks. Further research is needed to fully understand the model's flexibility and generalization abilities.
Finally, the paper does not address potential biases or fairness concerns that may arise from the model's training on potentially biased medical data. As these models become more widely deployed, it will be important to carefully audit them for unintended biases that could lead to disparities in healthcare delivery.
Despite these caveats, the work represents an important step forward in advancing high-resolution vision-language models for biomedicine and demonstrates the potential of self-supervised learning techniques to create powerful and adaptable medical AI assistants.
Conclusion
The STLLaVA-Med model introduced in this paper aims to push the boundaries of large language and vision models for medical applications. By leveraging self-supervised pre-training and iterative fine-tuning, the authors have developed a versatile system that can be adapted to tackle a variety of medical tasks, from generating medical reports to injecting medical visual knowledge and learning to adapt large vision-language models for surgical applications.
While the paper identifies some important caveats and areas for further research, the core contributions represent a significant step forward in advancing high-resolution vision-language models for biomedicine. If successful, models like STLLaVA-Med could have transformative implications for medical practice, enabling more efficient and personalized healthcare delivery through the power of large-scale language and vision AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
STLLaVA-Med: Self-Training Large Language and Vision Assistant for Medical
Guohao Sun, Can Qin, Huazhu Fu, Linwei Wang, Zhiqiang Tao
Large Vision-Language Models (LVLMs) have shown significant potential in assisting medical diagnosis by leveraging extensive biomedical datasets. However, the advancement of medical image understanding and reasoning critically depends on building high-quality visual instruction data, which is costly and labor-intensive to obtain, particularly in the medical domain. To mitigate this data-starving issue, we introduce Self-Training Large Language and Vision Assistant for Medical (STLLaVA-Med). The proposed method is designed to train a policy model (an LVLM) capable of auto-generating medical visual instruction data to improve data efficiency, guided through Direct Preference Optimization (DPO). Specifically, a more powerful and larger LVLM (e.g., GPT-4o) is involved as a biomedical expert to oversee the DPO fine-tuning process on the auto-generated data, encouraging the policy model to align efficiently with human preferences. We validate the efficacy and data efficiency of STLLaVA-Med across three major medical Visual Question Answering (VQA) benchmarks, demonstrating competitive zero-shot performance with the utilization of only 9% of the medical data.
Read more7/1/2024
0
Advancing High Resolution Vision-Language Models in Biomedicine
Zekai Chen, Arda Pekis, Kevin Brown
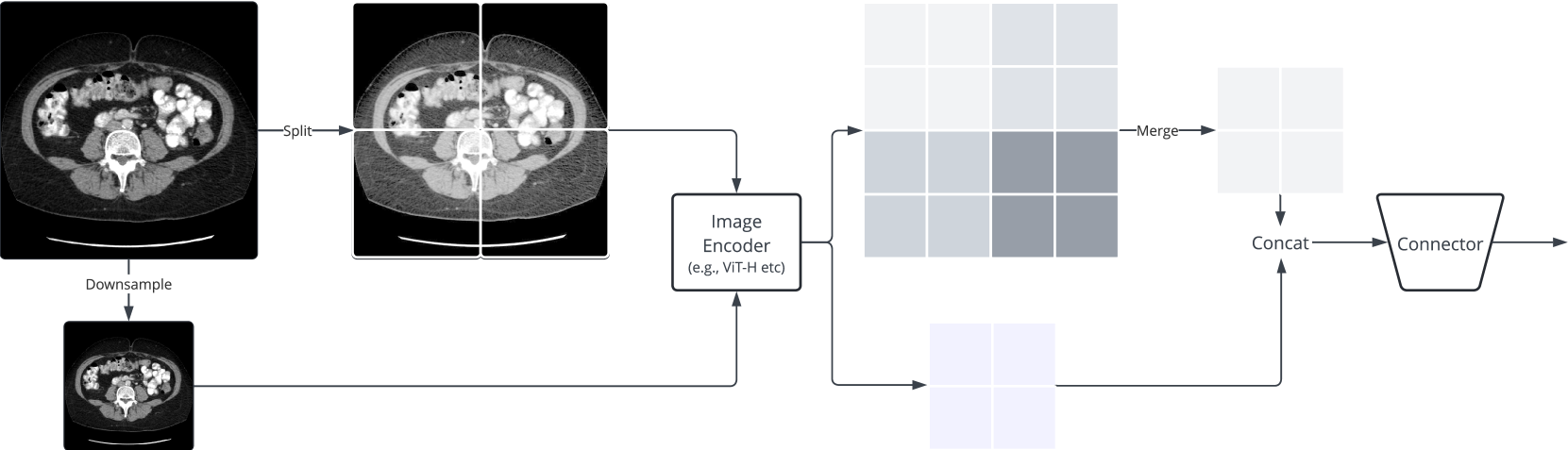
Multi-modal learning has significantly advanced generative AI, especially in vision-language modeling. Innovations like GPT-4V and open-source projects such as LLaVA have enabled robust conversational agents capable of zero-shot task completions. However, applying these technologies in the biomedical field presents unique challenges. Recent initiatives like LLaVA-Med have started to adapt instruction-tuning for biomedical contexts using large datasets such as PMC-15M. Our research offers three key contributions: (i) we present a new instruct dataset enriched with medical image-text pairs from Claude3-Opus and LLaMA3 70B, (ii) we propose a novel image encoding strategy using hierarchical representations to improve fine-grained biomedical visual comprehension, and (iii) we develop the Llama3-Med model, which achieves state-of-the-art zero-shot performance on biomedical visual question answering benchmarks, with an average performance improvement of over 10% compared to previous methods. These advancements provide more accurate and reliable tools for medical professionals, bridging gaps in current multi-modal conversational assistants and promoting further innovations in medical AI.
Read more6/17/2024

0
SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant
Guohao Sun, Can Qin, Jiamian Wang, Zeyuan Chen, Ran Xu, Zhiqiang Tao
Recent advances in vision-language models have shown notable generalization in broad tasks through visual instruction tuning. However, bridging the gap between the pre-trained vision encoder and the large language models (LLMs) becomes the whole network's bottleneck. To improve cross-modality alignment, existing works usually consider more visual instruction data covering a broader range of vision tasks to fine-tune the model for question-answering, which, however, is costly to obtain and has not thoroughly explored the rich contextual information contained in images. This paper first attempts to harness the overlooked context within visual instruction data, training the model to self-supervised learning how to ask high-quality questions. In this way, we introduce a novel framework named SQ-LLaVA: Self-Questioning for Large Vision-Language Assistant. SQ-LLaVA exhibits proficiency in generating flexible and meaningful image-related questions while analyzing the visual clue and prior language knowledge, signifying an advanced level of generalized visual understanding. Moreover, fine-tuning SQ-LLaVA on higher-quality instruction data shows a performance improvement compared with traditional visual-instruction tuning methods. This improvement highlights the efficacy of self-questioning techniques in achieving a deeper and more nuanced comprehension of visual content across various contexts.
Read more7/16/2024

0
PA-LLaVA: A Large Language-Vision Assistant for Human Pathology Image Understanding
Dawei Dai, Yuanhui Zhang, Long Xu, Qianlan Yang, Xiaojing Shen, Shuyin Xia, Guoyin Wang
The previous advancements in pathology image understanding primarily involved developing models tailored to specific tasks. Recent studies has demonstrated that the large vision-language model can enhance the performance of various downstream tasks in medical image understanding. In this study, we developed a domain-specific large language-vision assistant (PA-LLaVA) for pathology image understanding. Specifically, (1) we first construct a human pathology image-text dataset by cleaning the public medical image-text data for domain-specific alignment; (2) Using the proposed image-text data, we first train a pathology language-image pretraining (PLIP) model as the specialized visual encoder for pathology image, and then we developed scale-invariant connector to avoid the information loss caused by image scaling; (3) We adopt two-stage learning to train PA-LLaVA, first stage for domain alignment, and second stage for end to end visual question & answering (VQA) task. In experiments, we evaluate our PA-LLaVA on both supervised and zero-shot VQA datasets, our model achieved the best overall performance among multimodal models of similar scale. The ablation experiments also confirmed the effectiveness of our design. We posit that our PA-LLaVA model and the datasets presented in this work can promote research in field of computational pathology. All codes are available at: https://github.com/ddw2AIGROUP2CQUPT/PA-LLaVA}{https://github.com/ddw2AIGROUP2CQUPT/PA-LLaVA
Read more8/20/2024