LOQA: Learning with Opponent Q-Learning Awareness

0

Sign in to get full access
Overview
- This paper introduces a new reinforcement learning algorithm called LOQA (Learning with Opponent Q-Learning Awareness) for multi-agent environments.
- LOQA aims to improve performance in competitive multi-agent settings by having agents model and account for the learning behaviors of their opponents.
- The key idea is for agents to explicitly track the Q-values of their opponents and use this information to guide their own decision-making and learning.
Plain English Explanation
In many real-world scenarios, such as business negotiations or competitive games, we often have to interact with other intelligent agents who are also trying to achieve their own goals. In these multi-agent environments, the actions of one agent can significantly impact the outcomes for the others.
The ROMA: Reward-Oriented Meta-Adaptation Approach for Objective Alignment and n-Agent Ad-Hoc Teamwork papers have explored ways for agents to cooperate and coordinate in these settings. However, in truly competitive situations, agents may need to model and account for the learning behaviors of their opponents in order to succeed.
That's where LOQA comes in. The key idea behind LOQA is for agents to explicitly track the Q-values (a measure of expected future reward) of their opponents. By understanding how their opponents are learning and what actions they are likely to take, LOQA agents can adjust their own decision-making and learning in order to outperform their competitors.
For example, imagine a negotiation scenario where two companies are trying to secure the best deal. A LOQA agent would not only consider its own potential payoffs, but also try to predict how the other company is evaluating the situation and what moves it is likely to make. This opponent modeling allows the LOQA agent to adopt strategies that are more likely to lead to a favorable outcome, even in the face of a savvy competitor.
Technical Explanation
The LOQA algorithm builds on the well-known Q-learning reinforcement learning technique. In standard Q-learning, an agent learns a value function Q(s, a) that estimates the expected future reward for taking action a in state s. LOQA extends this by having each agent also learn a model of the Q-values of its opponents, denoted as Q^opp(s, a).
By tracking the opponent's Q-values, the LOQA agent can better anticipate the actions the opponent is likely to take. This allows the agent to choose actions that not only maximize its own expected reward, but also minimize the opponent's expected reward. The Best Response Shaping paper explores similar ideas for shaping agent behavior in multi-agent settings.
The LOQA agents update their own Q-values based on a combination of their own rewards and their predictions of the opponent's future actions, as encoded in the opponent's Q-values. This "opponent-aware" Q-learning allows the LOQA agents to converge to strategies that outperform standard Q-learning, especially in highly competitive environments.
The authors evaluate LOQA on several benchmark multi-agent tasks, including a variation of the classic Prisoner's Dilemma game. The results show that LOQA agents consistently outperform standard Q-learning agents, demonstrating the benefits of explicit opponent modeling and awareness.
Critical Analysis
The LOQA paper makes a compelling case for the importance of opponent modeling in competitive multi-agent settings. By having agents track and reason about the learning behaviors of their competitors, the LOQA algorithm is able to achieve better outcomes than standard reinforcement learning approaches.
However, the paper does not address some potential limitations and areas for further research. For example, the LOQA agents are assumed to have perfect information about their opponents' Q-values, which may not be realistic in many real-world scenarios. The Mesa-Cooperative: Meta-Exploration for Multi-Agent Learning paper explores ways to learn opponent models with partial information.
Additionally, the paper focuses on relatively simple multi-agent environments. It would be interesting to see how LOQA performs in more complex, dynamic settings with larger state and action spaces, or when agents have the ability to deceive or mislead their opponents. The Group Decision Making Among Privacy-Aware Agents paper explores some of these challenges in a multi-agent context.
Overall, the LOQA algorithm represents a promising step forward in the field of multi-agent reinforcement learning. By explicitly incorporating opponent modeling into the learning process, it demonstrates the potential for agents to outperform their competitors in adversarial environments. Further research into the practical applicability and robustness of LOQA could yield valuable insights for a wide range of real-world multi-agent systems.
Conclusion
The LOQA algorithm introduces a novel approach to multi-agent reinforcement learning that emphasizes the importance of opponent modeling and awareness. By having agents track and reason about the learning behaviors of their competitors, LOQA is able to outperform standard Q-learning techniques, especially in highly competitive environments.
While the paper focuses on relatively simple benchmark tasks, the core ideas behind LOQA could have far-reaching implications for a wide range of real-world multi-agent systems, from business negotiations to strategic decision-making. Further research into the practical applicability and robustness of LOQA could yield valuable insights for the field of artificial intelligence and its role in complex, adversarial interactions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
LOQA: Learning with Opponent Q-Learning Awareness
Milad Aghajohari, Juan Agustin Duque, Tim Cooijmans, Aaron Courville
In various real-world scenarios, interactions among agents often resemble the dynamics of general-sum games, where each agent strives to optimize its own utility. Despite the ubiquitous relevance of such settings, decentralized machine learning algorithms have struggled to find equilibria that maximize individual utility while preserving social welfare. In this paper we introduce Learning with Opponent Q-Learning Awareness (LOQA), a novel, decentralized reinforcement learning algorithm tailored to optimizing an agent's individual utility while fostering cooperation among adversaries in partially competitive environments. LOQA assumes the opponent samples actions proportionally to their action-value function Q. Experimental results demonstrate the effectiveness of LOQA at achieving state-of-the-art performance in benchmark scenarios such as the Iterated Prisoner's Dilemma and the Coin Game. LOQA achieves these outcomes with a significantly reduced computational footprint, making it a promising approach for practical multi-agent applications.
Read more5/3/2024
0
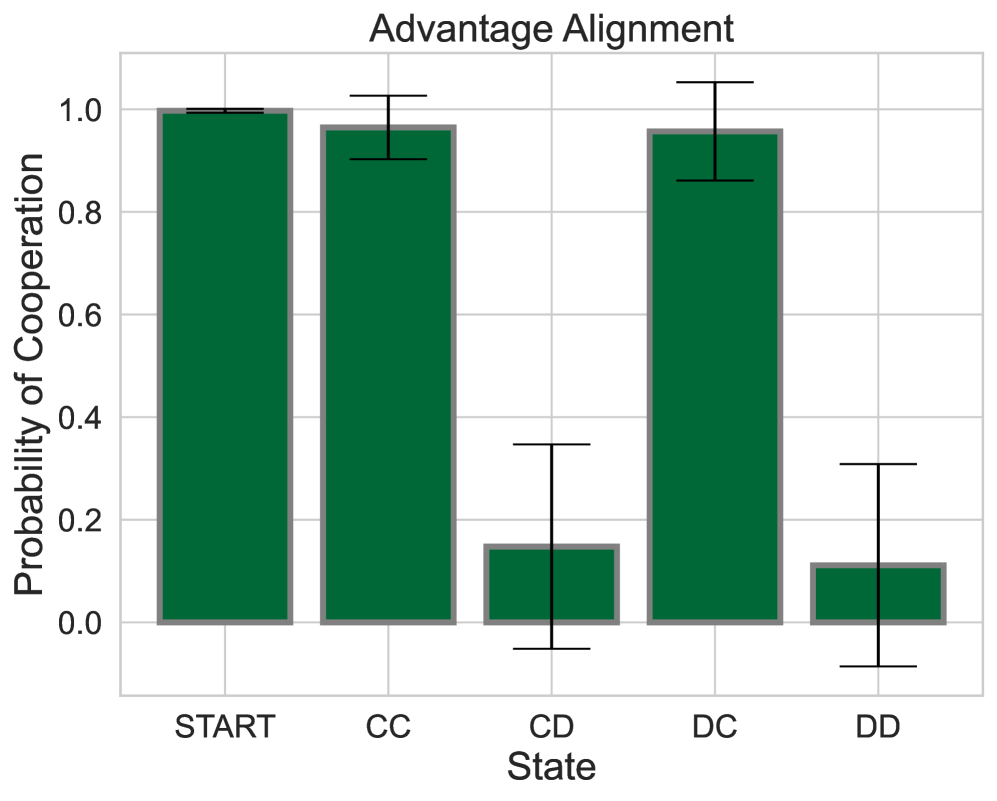
Advantage Alignment Algorithms
Juan Agustin Duque, Milad Aghajohari, Tim Cooijmans, Tianyu Zhang, Aaron Courville
The growing presence of artificially intelligent agents in everyday decision-making, from LLM assistants to autonomous vehicles, hints at a future in which conflicts may arise from each agent optimizing individual interests. In general-sum games these conflicts are apparent, where naive Reinforcement Learning agents get stuck in Pareto-suboptimal Nash equilibria. Consequently, opponent shaping has been introduced as a method with success at finding socially beneficial equilibria in social dilemmas. In this work, we introduce Advantage Alignment, a family of algorithms derived from first principles that perform opponent shaping efficiently and intuitively. This is achieved by aligning the advantages of conflicting agents in a given game by increasing the probability of mutually-benefiting actions. We prove that existing opponent shaping methods, including LOLA and LOQA, implicitly perform Advantage Alignment. Compared to these works, Advantage Alignment mathematically simplifies the formulation of opponent shaping and seamlessly works for continuous action domains. We also demonstrate the effectiveness of our algorithm in a wide range of social dilemmas, achieving state of the art results in each case, including a social dilemma version of the Negotiation Game.
Read more6/24/2024

0
Strategizing against Q-learners: A Control-theoretical Approach
Yuksel Arslantas, Ege Yuceel, Muhammed O. Sayin
In this paper, we explore the susceptibility of the independent Q-learning algorithms (a classical and widely used multi-agent reinforcement learning method) to strategic manipulation of sophisticated opponents in normal-form games played repeatedly. We quantify how much strategically sophisticated agents can exploit naive Q-learners if they know the opponents' Q-learning algorithm. To this end, we formulate the strategic actors' interactions as a stochastic game (whose state encompasses Q-function estimates of the Q-learners) as if the Q-learning algorithms are the underlying dynamical system. We also present a quantization-based approximation scheme to tackle the continuum state space and analyze its performance for two competing strategic actors and a single strategic actor both analytically and numerically.
Read more7/17/2024

0
A Multi-Agent Multi-Environment Mixed Q-Learning for Partially Decentralized Wireless Network Optimization
Talha Bozkus, Urbashi Mitra
Q-learning is a powerful tool for network control and policy optimization in wireless networks, but it struggles with large state spaces. Recent advancements, like multi-environment mixed Q-learning (MEMQ), improves performance and reduces complexity by integrating multiple Q-learning algorithms across multiple related environments so-called digital cousins. However, MEMQ is designed for centralized single-agent networks and is not suitable for decentralized or multi-agent networks. To address this challenge, we propose a novel multi-agent MEMQ algorithm for partially decentralized wireless networks with multiple mobile transmitters (TXs) and base stations (BSs), where TXs do not have access to each other's states and actions. In uncoordinated states, TXs act independently to minimize their individual costs. In coordinated states, TXs use a Bayesian approach to estimate the joint state based on local observations and share limited information with leader TX to minimize joint cost. The cost of information sharing scales linearly with the number of TXs and is independent of the joint state-action space size. The proposed scheme is 50% faster than centralized MEMQ with only a 20% increase in average policy error (APE) and is 25% faster than several advanced decentralized Q-learning algorithms with 40% less APE. The convergence of the algorithm is also demonstrated.
Read more9/26/2024