TabSynDex: A Universal Metric for Robust Evaluation of Synthetic Tabular Data
2207.05295
0
0
📊
Abstract
Synthetic tabular data generation becomes crucial when real data is limited, expensive to collect, or simply cannot be used due to privacy concerns. However, producing good quality synthetic data is challenging. Several probabilistic, statistical, generative adversarial networks (GANs), and variational auto-encoder (VAEs) based approaches have been presented for synthetic tabular data generation. Once generated, evaluating the quality of the synthetic data is quite challenging. Some of the traditional metrics have been used in the literature but there is lack of a common, robust, and single metric. This makes it difficult to properly compare the effectiveness of different synthetic tabular data generation methods. In this paper we propose a new universal metric, TabSynDex, for robust evaluation of synthetic data. The proposed metric assesses the similarity of synthetic data with real data through different component scores which evaluate the characteristics that are desirable for ``high quality'' synthetic data. Being a single score metric and having an implicit bound, TabSynDex can also be used to observe and evaluate the training of neural network based approaches. This would help in obtaining insights that was not possible earlier. We present several baseline models for comparative analysis of the proposed evaluation metric with existing generative models. We also give a comparative analysis between TabSynDex and existing synthetic tabular data evaluation metrics. This shows the effectiveness and universality of our metric over the existing metrics. Source Code: url{https://github.com/vikram2000b/tabsyndex}
Create account to get full access
Overview
- Synthetic tabular data generation is crucial when real data is limited, expensive, or cannot be used due to privacy concerns
- Producing high-quality synthetic data is challenging, and several probabilistic, statistical, GAN, and VAE-based approaches have been proposed
- Evaluating the quality of synthetic data is also quite challenging, with a lack of a common, robust, and single metric to compare the effectiveness of different methods
Plain English Explanation
Synthetic data is computer-generated information that looks and behaves like real-world data, but doesn't contain any private or sensitive details. Generating high-quality synthetic data becomes important when the real data we have is limited, costly to collect, or can't be used due to privacy concerns.
Creating good synthetic data is difficult. Researchers have tried using different statistical and machine learning techniques, like generative adversarial networks (GANs) and variational autoencoders (VAEs), to generate synthetic data that closely matches the real thing.
But once the synthetic data is created, how do we know if it's any good? There's no single, reliable way to evaluate the quality of synthetic data, unlike with real data. Existing evaluation methods have limitations, making it hard to properly compare different data generation techniques.
Technical Explanation
This paper proposes a new universal metric called TabSynDex to robustly evaluate the quality of synthetic tabular data. TabSynDex assesses the similarity between synthetic and real data through various component scores that look at desirable characteristics, like statistical properties and patterns.
Being a single score with an implicit bound, TabSynDex can also be used to monitor the training of neural network-based data generation approaches. This provides insights that weren't possible with previous evaluation methods.
The paper presents several baseline models for comparative analysis, and compares TabSynDex to existing synthetic tabular data evaluation metrics. This demonstrates the effectiveness and universality of the proposed metric.
Critical Analysis
The paper acknowledges that while TabSynDex is a step forward, evaluating synthetic data quality is still a challenging problem. The metric relies on certain assumptions and may not capture all nuances of complex, high-dimensional datasets.
Additionally, the paper does not explore the impact of dataset size, dimensionality, or other characteristics on the performance of TabSynDex. Further research is needed to understand the limitations and potential biases of the proposed metric.
The authors also mention the need for a supervised generative optimization approach to incorporate domain knowledge and better align synthetic data with specific use cases.
Conclusion
This paper presents a new evaluation metric, TabSynDex, to assess the quality of synthetic tabular data. By providing a robust, universal, and easy-to-interpret score, TabSynDex aims to help researchers and practitioners better compare different synthetic data generation techniques.
While not a perfect solution, TabSynDex represents an important step towards addressing the challenges of synthetic data quality evaluation. As the field of synthetic data generation continues to evolve, tools like TabSynDex will become increasingly valuable for ensuring the reliability and usefulness of computer-generated data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Systematic Assessment of Tabular Data Synthesis Algorithms
Yuntao Du, Ninghui Li
0
0
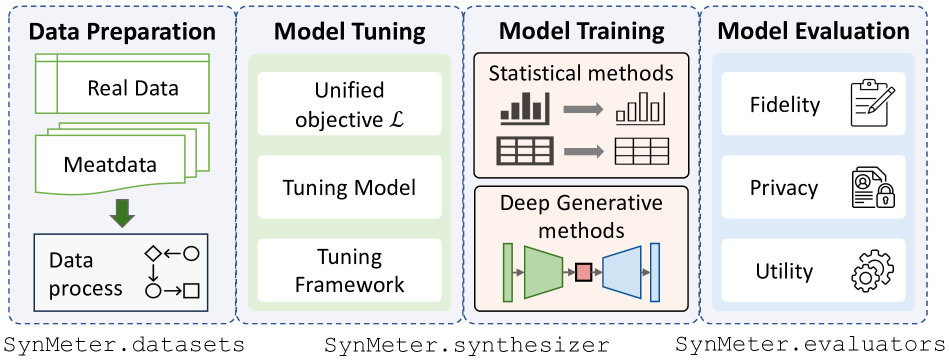
Data synthesis has been advocated as an important approach for utilizing data while protecting data privacy. A large number of tabular data synthesis algorithms (which we call synthesizers) have been proposed. Some synthesizers satisfy Differential Privacy, while others aim to provide privacy in a heuristic fashion. A comprehensive understanding of the strengths and weaknesses of these synthesizers remains elusive due to drawbacks in evaluation metrics and missing head-to-head comparisons of newly developed synthesizers that take advantage of diffusion models and large language models with state-of-the-art marginal-based synthesizers. In this paper, we present a systematic evaluation framework for assessing tabular data synthesis algorithms. Specifically, we examine and critique existing evaluation metrics, and introduce a set of new metrics in terms of fidelity, privacy, and utility to address their limitations. Based on the proposed metrics, we also devise a unified objective for tuning, which can consistently improve the quality of synthetic data for all methods. We conducted extensive evaluations of 8 different types of synthesizers on 12 real-world datasets and identified some interesting findings, which offer new directions for privacy-preserving data synthesis.
4/16/2024
Structured Evaluation of Synthetic Tabular Data
Scott Cheng-Hsin Yang, Baxter Eaves, Michael Schmidt, Ken Swanson, Patrick Shafto
0
0
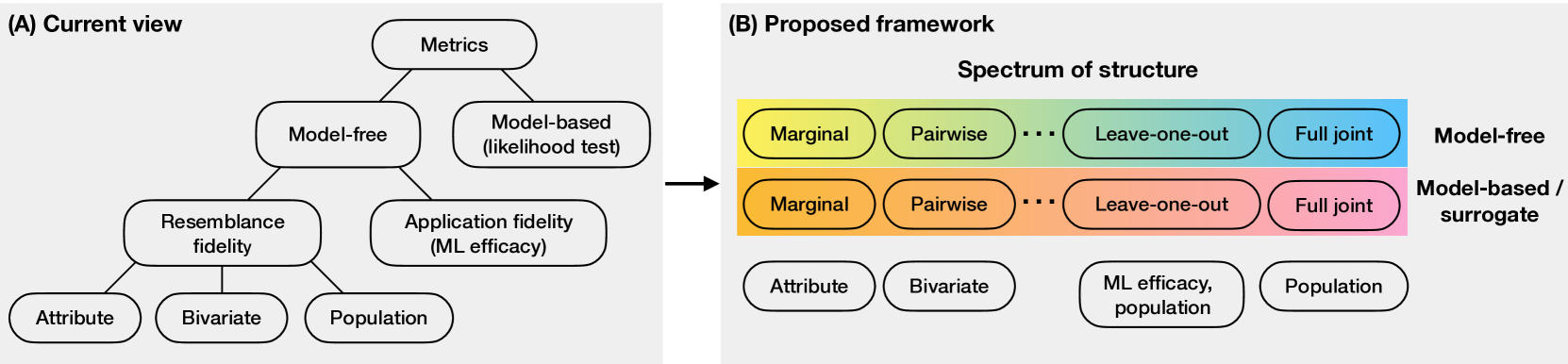
Tabular data is common yet typically incomplete, small in volume, and access-restricted due to privacy concerns. Synthetic data generation offers potential solutions. Many metrics exist for evaluating the quality of synthetic tabular data; however, we lack an objective, coherent interpretation of the many metrics. To address this issue, we propose an evaluation framework with a single, mathematical objective that posits that the synthetic data should be drawn from the same distribution as the observed data. Through various structural decomposition of the objective, this framework allows us to reason for the first time the completeness of any set of metrics, as well as unifies existing metrics, including those that stem from fidelity considerations, downstream application, and model-based approaches. Moreover, the framework motivates model-free baselines and a new spectrum of metrics. We evaluate structurally informed synthesizers and synthesizers powered by deep learning. Using our structured framework, we show that synthetic data generators that explicitly represent tabular structure outperform other methods, especially on smaller datasets.
4/1/2024
Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Balasubramaniam Srinivasan, Zhengyuan Shen, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
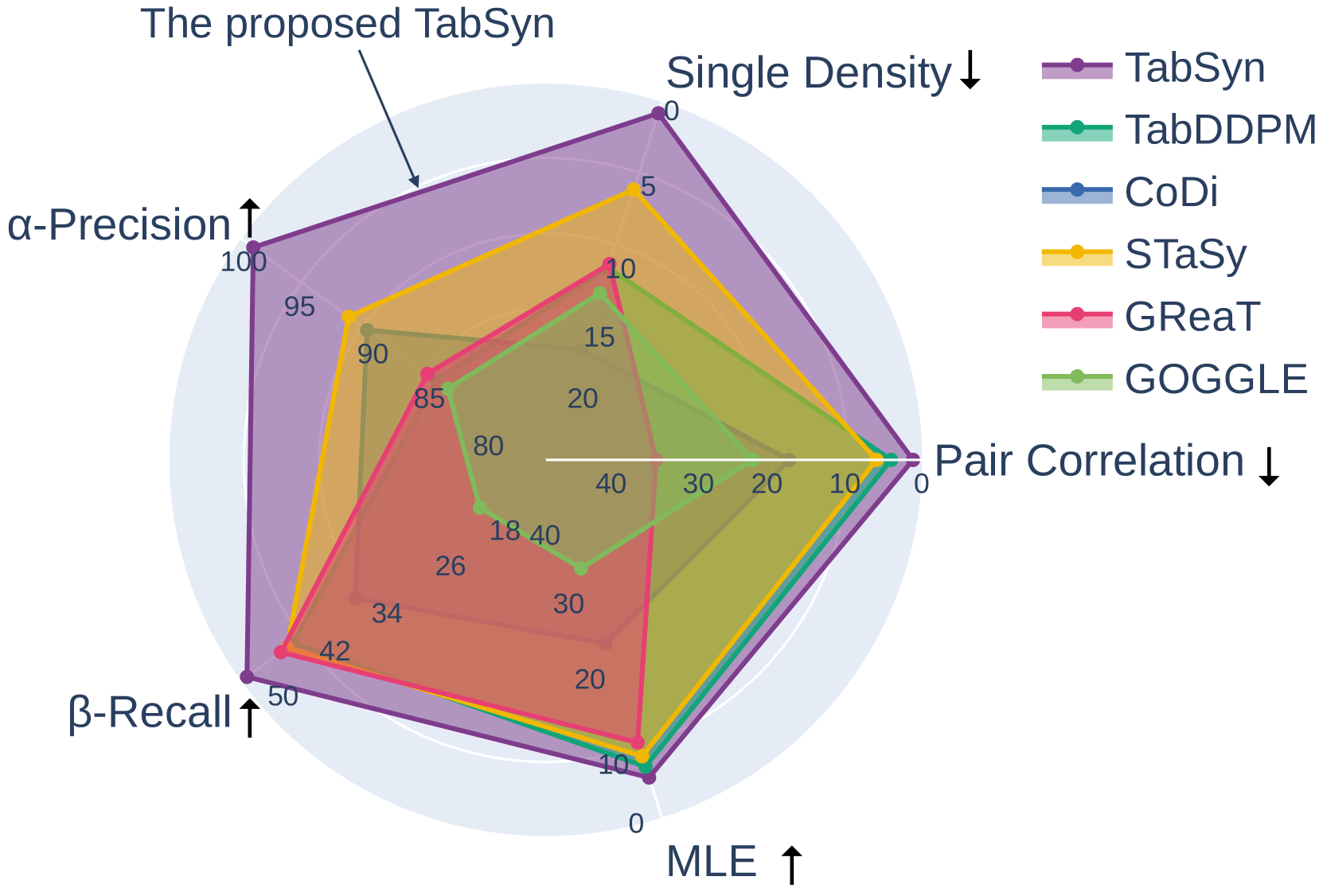
Recent advances in tabular data generation have greatly enhanced synthetic data quality. However, extending diffusion models to tabular data is challenging due to the intricately varied distributions and a blend of data types of tabular data. This paper introduces Tabsyn, a methodology that synthesizes tabular data by leveraging a diffusion model within a variational autoencoder (VAE) crafted latent space. The key advantages of the proposed Tabsyn include (1) Generality: the ability to handle a broad spectrum of data types by converting them into a single unified space and explicitly capture inter-column relations; (2) Quality: optimizing the distribution of latent embeddings to enhance the subsequent training of diffusion models, which helps generate high-quality synthetic data, (3) Speed: much fewer number of reverse steps and faster synthesis speed than existing diffusion-based methods. Extensive experiments on six datasets with five metrics demonstrate that Tabsyn outperforms existing methods. Specifically, it reduces the error rates by 86% and 67% for column-wise distribution and pair-wise column correlation estimations compared with the most competitive baselines.
5/14/2024
A Multi-Faceted Evaluation Framework for Assessing Synthetic Data Generated by Large Language Models
Yefeng Yuan, Yuhong Liu, Liang Cheng
0
0
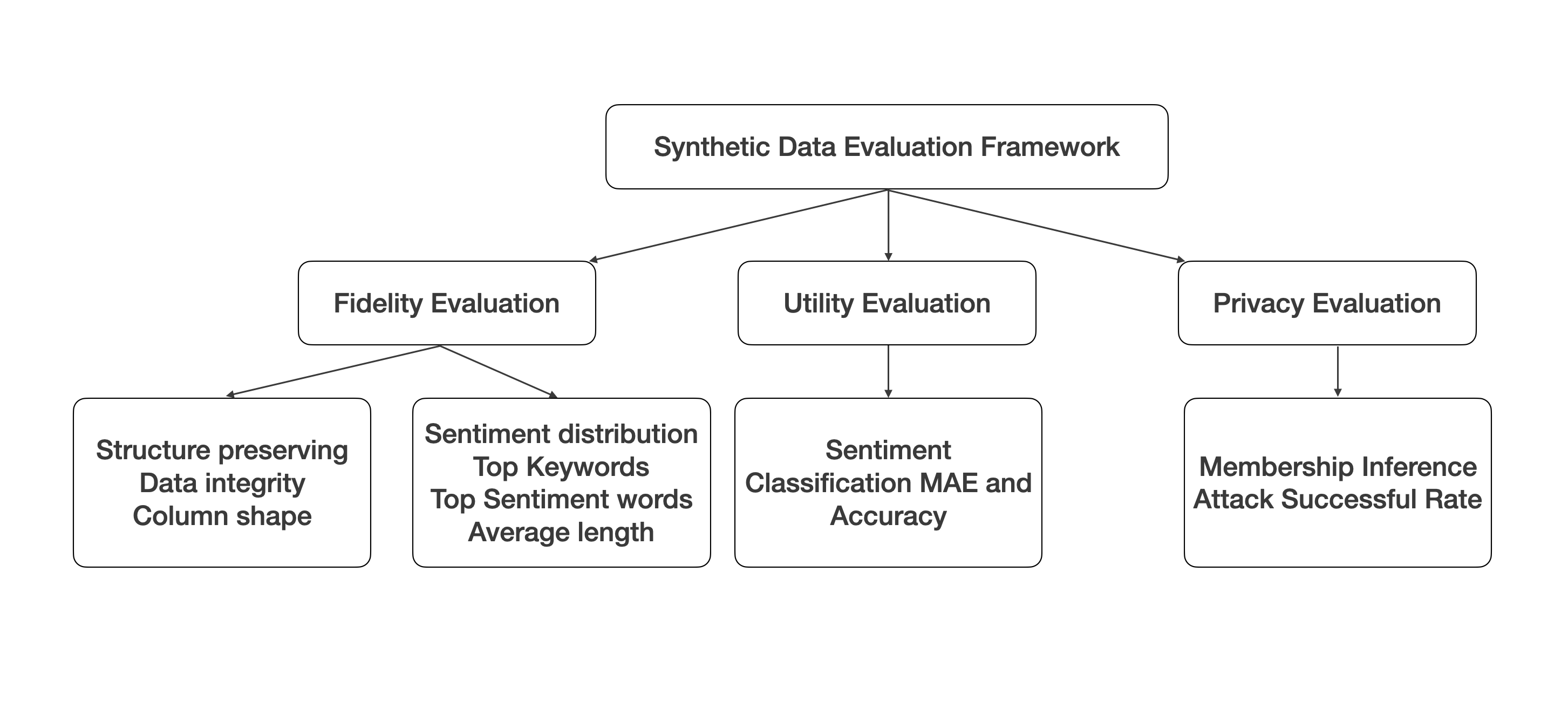
The rapid advancements in generative AI and large language models (LLMs) have opened up new avenues for producing synthetic data, particularly in the realm of structured tabular formats, such as product reviews. Despite the potential benefits, concerns regarding privacy leakage have surfaced, especially when personal information is utilized in the training datasets. In addition, there is an absence of a comprehensive evaluation framework capable of quantitatively measuring the quality of the generated synthetic data and their utility for downstream tasks. In response to this gap, we introduce SynEval, an open-source evaluation framework designed to assess the fidelity, utility, and privacy preservation of synthetically generated tabular data via a suite of diverse evaluation metrics. We validate the efficacy of our proposed framework - SynEval - by applying it to synthetic product review data generated by three state-of-the-art LLMs: ChatGPT, Claude, and Llama. Our experimental findings illuminate the trade-offs between various evaluation metrics in the context of synthetic data generation. Furthermore, SynEval stands as a critical instrument for researchers and practitioners engaged with synthetic tabular data,, empowering them to judiciously determine the suitability of the generated data for their specific applications, with an emphasis on upholding user privacy.
4/24/2024