A Study on Developer Behaviors for Validating and Repairing LLM-Generated Code Using Eye Tracking and IDE Actions

0

Sign in to get full access
Overview
- This study examines how developers validate and repair code generated by large language models (LLMs) like GitHub Copilot, using eye tracking and IDE (Integrated Development Environment) action data.
- Researchers analyzed developer behavior to understand their strategies for debugging and improving LLM-generated code.
- The study provides insights into how developers interact with and assess the quality of AI-generated code, which can inform the development of more reliable and user-friendly AI coding assistants.
Plain English Explanation
When AI language models like GitHub Copilot are used to generate code, developers need to carefully validate and repair any issues with the output. This study looked at how developers go about this process, using tools like eye tracking and monitoring their actions in the IDE.
By understanding how developers debug and improve AI-generated code, the researchers hope to guide the development of better AI coding assistants. For example, the AutoCoderOver system aims to automatically improve AI-generated code, while the Reading Between the Lines project models user behavior to understand the costs of interacting with AI systems.
The study provides insights into the strategies developers use to validate the code, identify problems, and make repairs. This can help AI systems like CodeCloak and zero-shot synthetic code generation become more reliable and user-friendly.
Technical Explanation
The researchers conducted an experiment where developers were asked to validate and repair code generated by an LLM. They used eye tracking and IDE action data to analyze the developers' behavior and strategies.
The experiment involved participants working on a coding task where they were presented with LLM-generated code and asked to assess its correctness and make any necessary repairs. The researchers monitored the developers' eye movements and recorded their actions within the IDE, such as navigating the code, making edits, and running tests.
By analyzing the eye tracking and IDE data, the researchers were able to identify patterns in how developers approached the validation and repair process. They found that developers used a variety of strategies, including:
- Closely examining the code to identify potential issues
- Running tests and checking the program's behavior
- Referring to external resources like documentation or online forums
- Iteratively making changes and testing the code
The insights from this study can inform the design of more effective AI coding assistants, helping to improve the reliability and user-friendliness of these systems.
Critical Analysis
The study provides valuable insights into how developers interact with and assess the quality of LLM-generated code. However, it's important to note that the research was conducted in a controlled experimental setting, which may not fully capture the real-world challenges and constraints that developers face when working with AI-generated code.
Additionally, the study focused on a relatively small sample size of developers, which may limit the generalizability of the findings. It would be helpful to see this research replicated with a larger and more diverse group of participants to further validate the results.
Another potential limitation is that the study only examined a single LLM and a specific coding task. It would be interesting to see how the findings might differ when using different LLMs or when developers are working on a wider range of coding problems.
Despite these caveats, the study offers a valuable contribution to the understanding of developer behavior in the context of AI-assisted coding. The insights gained can inform the development of more reliable and user-friendly AI coding assistants, which could have significant implications for the field of software engineering.
Conclusion
This study provides important insights into how developers validate and repair code generated by large language models like GitHub Copilot. By analyzing developer behavior through eye tracking and IDE action data, the researchers have identified the strategies and approaches used by developers to assess the quality of AI-generated code and make necessary improvements.
The findings of this study can inform the development of more effective and user-friendly AI coding assistants, helping to improve the reliability and accessibility of these tools for software engineers. As AI systems become increasingly involved in the coding process, understanding how developers interact with and respond to AI-generated code will be crucial for ensuring the successful integration of these technologies into the software development workflow.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Study on Developer Behaviors for Validating and Repairing LLM-Generated Code Using Eye Tracking and IDE Actions
Ningzhi Tang, Meng Chen, Zheng Ning, Aakash Bansal, Yu Huang, Collin McMillan, Toby Jia-Jun Li
The increasing use of large language model (LLM)-powered code generation tools, such as GitHub Copilot, is transforming software engineering practices. This paper investigates how developers validate and repair code generated by Copilot and examines the impact of code provenance awareness during these processes. We conducted a lab study with 28 participants, who were tasked with validating and repairing Copilot-generated code in three software projects. Participants were randomly divided into two groups: one informed about the provenance of LLM-generated code and the other not. We collected data on IDE interactions, eye-tracking, cognitive workload assessments, and conducted semi-structured interviews. Our results indicate that, without explicit information, developers often fail to identify the LLM origin of the code. Developers generally employ similar validation and repair strategies for LLM-generated code, but exhibit behaviors such as frequent switching between code and comments, different attentional focus, and a tendency to delete and rewrite code. Being aware of the code's provenance led to improved performance, increased search efforts, more frequent Copilot usage, and higher cognitive workload. These findings enhance our understanding of how developers interact with LLM-generated code and carry implications for designing tools that facilitate effective human-LLM collaboration in software development.
Read more5/28/2024
2
Examination of Code generated by Large Language Models
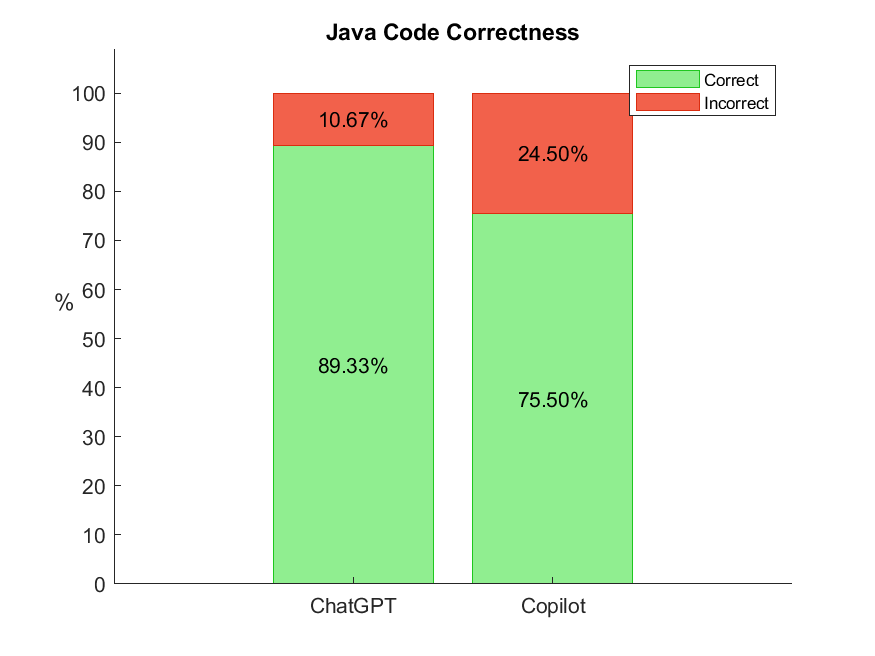
Robin Beer, Alexander Feix, Tim Guttzeit, Tamara Muras, Vincent Muller, Maurice Rauscher, Florian Schaffler, Welf Lowe
Large language models (LLMs), such as ChatGPT and Copilot, are transforming software development by automating code generation and, arguably, enable rapid prototyping, support education, and boost productivity. Therefore, correctness and quality of the generated code should be on par with manually written code. To assess the current state of LLMs in generating correct code of high quality, we conducted controlled experiments with ChatGPT and Copilot: we let the LLMs generate simple algorithms in Java and Python along with the corresponding unit tests and assessed the correctness and the quality (coverage) of the generated (test) codes. We observed significant differences between the LLMs, between the languages, between algorithm and test codes, and over time. The present paper reports these results together with the experimental methods allowing repeated and comparable assessments for more algorithms, languages, and LLMs over time.
Read more8/30/2024
🌀
0
Chain of Targeted Verification Questions to Improve the Reliability of Code Generated by LLMs
Sylvain Kouemo Ngassom, Arghavan Moradi Dakhel, Florian Tambon, Foutse Khomh
LLM-based assistants, such as GitHub Copilot and ChatGPT, have the potential to generate code that fulfills a programming task described in a natural language description, referred to as a prompt. The widespread accessibility of these assistants enables users with diverse backgrounds to generate code and integrate it into software projects. However, studies show that code generated by LLMs is prone to bugs and may miss various corner cases in task specifications. Presenting such buggy code to users can impact their reliability and trust in LLM-based assistants. Moreover, significant efforts are required by the user to detect and repair any bug present in the code, especially if no test cases are available. In this study, we propose a self-refinement method aimed at improving the reliability of code generated by LLMs by minimizing the number of bugs before execution, without human intervention, and in the absence of test cases. Our approach is based on targeted Verification Questions (VQs) to identify potential bugs within the initial code. These VQs target various nodes within the Abstract Syntax Tree (AST) of the initial code, which have the potential to trigger specific types of bug patterns commonly found in LLM-generated code. Finally, our method attempts to repair these potential bugs by re-prompting the LLM with the targeted VQs and the initial code. Our evaluation, based on programming tasks in the CoderEval dataset, demonstrates that our proposed method outperforms state-of-the-art methods by decreasing the number of targeted errors in the code between 21% to 62% and improving the number of executable code instances to 13%.
Read more5/24/2024
🤔
0
Understanding Defects in Generated Codes by Language Models
Ali Mohammadi Esfahani, Nafiseh Kahani, Samuel A. Ajila
This study investigates the reliability of code generation by Large Language Models (LLMs), focusing on identifying and analyzing defects in the generated code. Despite the advanced capabilities of LLMs in automating code generation, ensuring the accuracy and functionality of the output remains a significant challenge. By using a structured defect classification method to understand their nature and origins this study categorizes and analyzes 367 identified defects from code snippets generated by LLMs, with a significant proportion being functionality and algorithm errors. These error categories indicate key areas where LLMs frequently fail, underscoring the need for targeted improvements. To enhance the accuracy of code generation, this paper implemented five prompt engineering techniques, including Scratchpad Prompting, Program of Thoughts Prompting, Chain-of-Thought Prompting, Chain of Code Prompting, and Structured Chain-of-Thought Prompting. These techniques were applied to refine the input prompts, aiming to reduce ambiguities and improve the models' accuracy rate. The research findings suggest that precise and structured prompting significantly mitigates common defects, thereby increasing the reliability of LLM-generated code.
Read more8/27/2024