A Study on Effect of Reference Knowledge Choice in Generating Technical Content Relevant to SAPPhIRE Model Using Large Language Model

0
📈
Sign in to get full access
Overview
- This research investigates how to accurately generate technical content relevant to the SAPPhIRE model of causality using a Large Language Model (LLM).
- The paper presents a method for hallucination suppression using Retrieval Augmented Generating with LLM to generate technical content supported by scientific information.
- The research emphasizes the importance of selecting the right reference knowledge to provide context to the LLM for generating accurate technical content.
- The outcome of this research is used to build a software support tool to generate the SAPPhIRE model of a given technical system.
Plain English Explanation
The SAPPhIRE model of causality can be a useful tool for designing and understanding technical or natural systems. However, creating a SAPPhIRE model requires extensive knowledge about how the system works, which can be challenging to gather from multiple technical documents. This research explores a way to automatically generate the technical content needed for a SAPPhIRE model using a Large Language Model (LLM).
The key idea is to use a technique called Retrieval Augmented Generating to help the LLM generate accurate and relevant technical information. This involves providing the LLM with carefully selected reference knowledge to use as context when generating the content, rather than just relying on the LLM's own knowledge.
The researchers found that the selection of this reference knowledge is crucial - it needs to be closely aligned with the specific technical details required for the SAPPhIRE model. By getting the right reference information, the LLM can generate technical content that is well-supported by scientific facts, rather than hallucinating or making up information.
This research has led to the development of a software tool that can automatically generate a SAPPhIRE model for a given technical system, based on the LLM-generated content. This could be a valuable asset for designers, engineers, and researchers who need to understand and represent complex systems.
Technical Explanation
This research presents a method for using Retrieval Augmented Generating with LLMs to generate accurate technical content relevant to the SAPPhIRE model of causality.
The key steps of the method are:
- Identifying the relevant technical knowledge required for a SAPPhIRE model of a given system.
- Retrieving reference documents that contain the necessary technical information.
- Using the retrieved reference knowledge to provide context to the LLM when generating the technical content.
- Evaluating the generated content for accuracy and relevance to the SAPPhIRE model.
The researchers found that the selection of the reference knowledge is crucial - it needs to be closely aligned with the specific technical details required for the SAPPhIRE model. If the reference knowledge is not well-matched, the LLM may generate content that is inaccurate or irrelevant.
By using the Retrieval Augmented Generating approach, the researchers were able to suppress hallucination and generate technical content that is well-supported by scientific facts from the reference documents. This resulted in technical descriptions that are suitable for building a SAPPhIRE model of a given system.
Critical Analysis
The research presents a promising approach for automatically generating technical content to support the creation of SAPPhIRE models. However, there are a few potential limitations and areas for further exploration:
-
The effectiveness of the method may be dependent on the quality and relevance of the reference documents retrieved. Improving the document retrieval process could help ensure the LLM has access to the most appropriate technical information.
-
The research focused on generating content for the SAPPhIRE model, but the approach could potentially be applied to other types of technical or scientific content generation tasks. Exploring the broader applicability of the method could be valuable.
-
The evaluation of the generated content was mainly qualitative, based on experts' assessments. Developing more quantitative metrics to assess the accuracy, coherence, and completeness of the generated technical descriptions could strengthen the validation of the approach.
-
While the research demonstrates the potential of this method, further studies are needed to understand its scalability and robustness when applied to a wider range of technical domains and system complexities.
Overall, this research presents an interesting and promising step towards leveraging Large Language Models and Retrieval Augmented Generating to assist in the generation of technical content for system modeling and design.
Conclusion
This research investigates a method for using Large Language Models and Retrieval Augmented Generating to accurately generate technical content relevant to the SAPPhIRE model of causality. The key findings are:
- The selection of the reference knowledge used to provide context to the LLM is crucial for generating technical content that is well-supported by scientific facts.
- The Retrieval Augmented Generating approach can help suppress hallucination and ensure the generated content is relevant and appropriate for building a SAPPhIRE model.
- The outcome of this research has been used to develop a software tool that can automatically generate SAPPhIRE models for technical systems, which could be a valuable asset for designers, engineers, and researchers.
While the research demonstrates the potential of this method, further exploration is needed to address potential limitations and explore its broader applicability beyond the SAPPhIRE modeling domain. Overall, this work represents an interesting step towards leveraging advanced language models to assist in the generation of technical and scientific content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
A Study on Effect of Reference Knowledge Choice in Generating Technical Content Relevant to SAPPhIRE Model Using Large Language Model
Kausik Bhattacharya, Anubhab Majumder, Amaresh Chakrabarti
Representation of systems using the SAPPhIRE model of causality can be an inspirational stimulus in design. However, creating a SAPPhIRE model of a technical or a natural system requires sourcing technical knowledge from multiple technical documents regarding how the system works. This research investigates how to generate technical content accurately relevant to the SAPPhIRE model of causality using a Large Language Model, also called LLM. This paper, which is the first part of the two-part research, presents a method for hallucination suppression using Retrieval Augmented Generating with LLM to generate technical content supported by the scientific information relevant to a SAPPhIRE con-struct. The result from this research shows that the selection of reference knowledge used in providing context to the LLM for generating the technical content is very important. The outcome of this research is used to build a software support tool to generate the SAPPhIRE model of a given technical system.
Read more7/2/2024
🛸
0
Development and Evaluation of a Retrieval-Augmented Generation Tool for Creating SAPPhIRE Models of Artificial Systems
Anubhab Majumder, Kausik Bhattacharya, Amaresh Chakrabarti
Representing systems using the SAPPhIRE causality model is found useful in supporting design-by-analogy. However, creating a SAPPhIRE model of artificial or biological systems is an effort-intensive process that requires human experts to source technical knowledge from multiple technical documents regarding how the system works. This research investigates how to leverage Large Language Models (LLMs) in creating structured descriptions of systems using the SAPPhIRE model of causality. This paper, the second part of the two-part research, presents a new Retrieval-Augmented Generation (RAG) tool for generating information related to SAPPhIRE constructs of artificial systems and reports the results from a preliminary evaluation of the tool's success - focusing on the factual accuracy and reliability of outcomes.
Read more7/1/2024
0
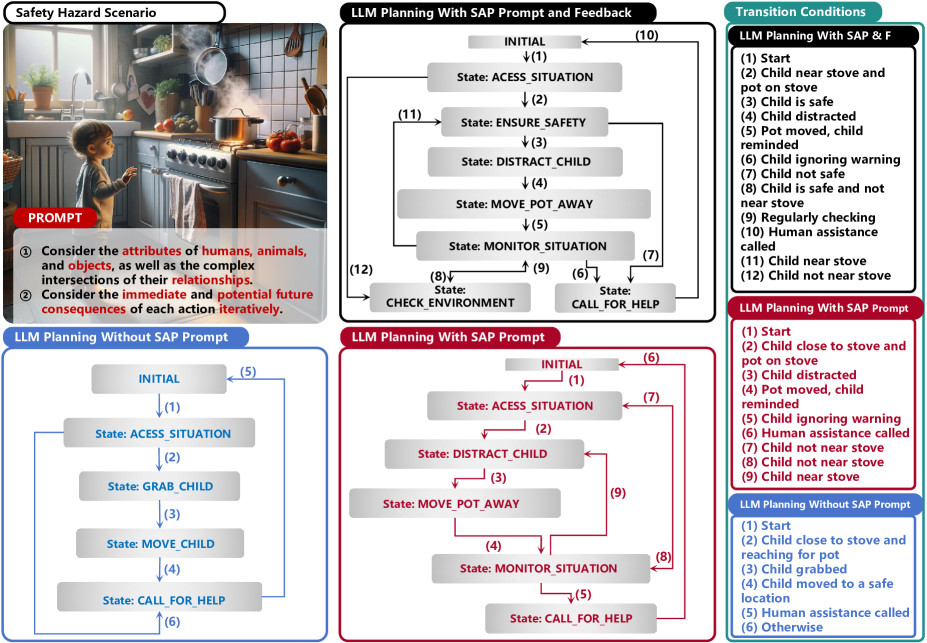
LLM-SAP: Large Language Models Situational Awareness Based Planning
Liman Wang, Hanyang Zhong
This study explores integrating large language models (LLMs) with situational awareness-based planning (SAP) to enhance the decision-making capabilities of AI agents in dynamic and uncertain environments. We employ a multi-agent reasoning framework to develop a methodology that anticipates and actively mitigates potential risks through iterative feedback and evaluation processes. Our approach diverges from traditional automata theory by incorporating the complexity of human-centric interactions into the planning process, thereby expanding the planning scope of LLMs beyond structured and predictable scenarios. The results demonstrate significant improvements in the model's ability to provide comparative safe actions within hazard interactions, offering a perspective on proactive and reactive planning strategies. This research highlights the potential of LLMs to perform human-like action planning, thereby paving the way for more sophisticated, reliable, and safe AI systems in unpredictable real-world applications.
Read more6/18/2024
0
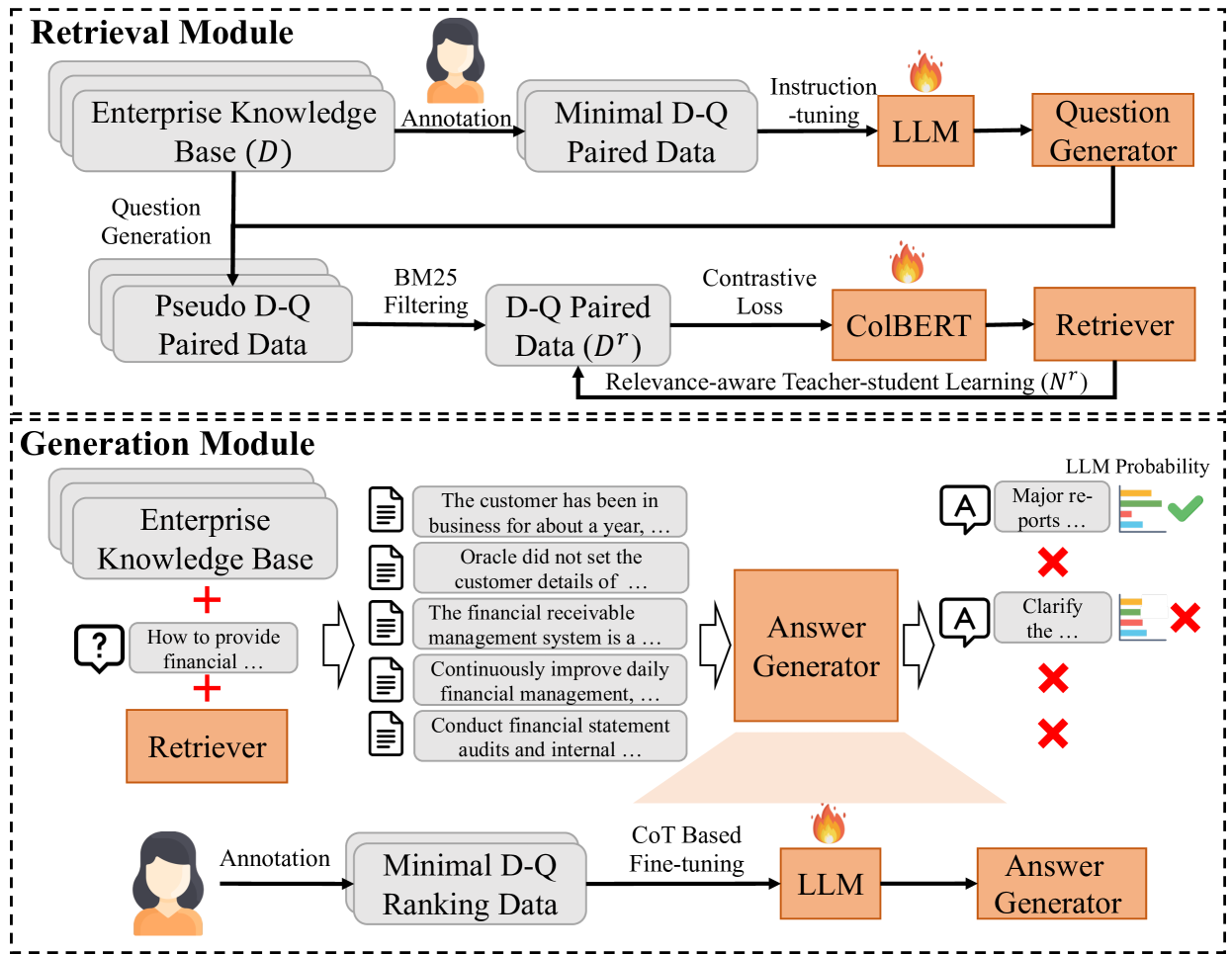
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Read more4/23/2024