Language Model Can Listen While Speaking

0

Sign in to get full access
Overview
- Language models can now listen while speaking, enabling more natural and efficient conversations.
- This paper presents a new architecture that allows language models to process input and generate output simultaneously.
- The model is evaluated on spoken dialogue tasks, demonstrating significant improvements in conversational flow and user experience.
Plain English Explanation
The research paper describes a new language model that can listen and speak at the same time, rather than taking turns. This enables more natural and efficient conversations, like how humans communicate.
Traditionally, conversational AI systems have operated in a turn-based fashion, with the user speaking and then the system responding. However, this can feel unnatural and disrupt the flow of dialogue.
The new model developed in this paper allows the AI to process the user's input while simultaneously generating its own response. This full-duplex capability makes the conversation feel more seamless and human-like, with the AI able to interject, ask clarifying questions, or provide feedback as the user is still speaking.
The researchers tested this model on spoken dialogue tasks and found significant improvements in conversational flow and user experience compared to traditional turn-based systems. This breakthrough represents an important step towards more natural and efficient human-AI interactions.
Technical Explanation
The paper introduces a novel language model architecture that enables simultaneous listening and speaking. The key innovation is the use of a parallel processing approach, where the model can ingest user input and generate its own output concurrently.
Traditionally, language models have operated in a strictly sequential manner, first processing the user's utterance and then generating a response. In contrast, the new architecture uses a dual-stream design, with separate pathways for comprehension and generation. This allows the model to continuously attend to the user's speech while simultaneously producing its own output.
The model is evaluated on a range of spoken dialogue tasks, including task-oriented conversations and open-ended chatting. The results demonstrate significant improvements in conversational flow and user experience compared to turn-based baselines. Users report feeling that the interactions are more natural and efficient, with the AI able to provide timely feedback and ask clarifying questions as the conversation unfolds.
The paper also includes an in-depth analysis of the model's inner workings, shedding light on how the parallel processing capabilities are achieved. The researchers explore the architectural choices and training strategies that enable this breakthrough in conversational AI.
Critical Analysis
The paper presents a compelling advance in language model capabilities, enabling more natural and efficient human-AI interactions. The simultaneous listening and speaking approach addresses a key limitation of traditional turn-based systems, which can disrupt the flow of dialogue.
However, the authors acknowledge several caveats and areas for further research. For instance, the model is currently limited to spoken dialogue tasks and may not generalize as well to other modalities like text-based chat. Additionally, the researchers note that the parallel processing introduces additional complexity and computational requirements, which could pose challenges for real-world deployment.
Further research is needed to explore the long-term impacts of this technology on user trust, mental models, and social dynamics. It will be important to study how people adapt to and interact with language models that can listen and speak concurrently, and whether this changes their expectations and perceptions of the AI system.
Additionally, the researchers did not address potential ethical concerns, such as the risk of the AI interrupting or talking over users, or the implications for privacy and data ownership in always-on conversational settings. Future work should carefully consider these important issues.
Overall, the paper presents an exciting and significant advancement in the field of conversational AI. By enabling language models to listen while speaking, the researchers have taken an important step towards more natural and efficient human-AI interactions. However, the implications of this technology will require continued scrutiny and research to ensure it is developed and deployed responsibly.
Conclusion
This research paper introduces a groundbreaking new language model architecture that allows for simultaneous listening and speaking, enabling more natural and efficient conversational experiences. By processing user input and generating output in parallel, the model can provide timely feedback, ask clarifying questions, and maintain a more seamless flow of dialogue compared to traditional turn-based systems.
The researchers demonstrated the effectiveness of this approach through evaluations on spoken dialogue tasks, showing significant improvements in user experience and conversational flow. This represents an important advancement in the field of conversational AI, bringing us closer to language models that can engage in truly natural and human-like interactions.
While the paper presents an exciting technical breakthrough, it also highlights the need for further research to address the complexities and potential risks of this technology. Continued exploration of the long-term impacts, ethical considerations, and real-world deployment challenges will be crucial as these models are developed and scaled.
Overall, the ability of language models to listen while speaking is a significant milestone, with the potential to transform the way we interact with conversational AI systems. This research lays the groundwork for a future where human-AI interactions feel more natural, efficient, and seamless.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Language Model Can Listen While Speaking
Ziyang Ma, Yakun Song, Chenpeng Du, Jian Cong, Zhuo Chen, Yuping Wang, Yuxuan Wang, Xie Chen
Dialogue serves as the most natural manner of human-computer interaction (HCI). Recent advancements in speech language models (SLM) have significantly enhanced speech-based conversational AI. However, these models are limited to turn-based conversation, lacking the ability to interact with humans in real-time spoken scenarios, for example, being interrupted when the generated content is not satisfactory. To address these limitations, we explore full duplex modeling (FDM) in interactive speech language models (iSLM), focusing on enhancing real-time interaction and, more explicitly, exploring the quintessential ability of interruption. We introduce a novel model design, namely listening-while-speaking language model (LSLM), an end-to-end system equipped with both listening and speaking channels. Our LSLM employs a token-based decoder-only TTS for speech generation and a streaming self-supervised learning (SSL) encoder for real-time audio input. LSLM fuses both channels for autoregressive generation and detects turn-taking in real time. Three fusion strategies -- early fusion, middle fusion, and late fusion -- are explored, with middle fusion achieving an optimal balance between speech generation and real-time interaction. Two experimental settings, command-based FDM and voice-based FDM, demonstrate LSLM's robustness to noise and sensitivity to diverse instructions. Our results highlight LSLM's capability to achieve duplex communication with minimal impact on existing systems. This study aims to advance the development of interactive speech dialogue systems, enhancing their applicability in real-world contexts.
Read more8/6/2024
🗣️
0
A Full-duplex Speech Dialogue Scheme Based On Large Language Models
Peng Wang, Songshuo Lu, Yaohua Tang, Sijie Yan, Yuanjun Xiong, Wei Xia
We present a generative dialogue system capable of operating in a full-duplex manner, allowing for seamless interaction. It is based on a large language model (LLM) carefully aligned to be aware of a perception module, a motor function module, and the concept of a simple finite state machine (called neural FSM) with two states. The perception and motor function modules operate simultaneously, allowing the system to simultaneously speak and listen to the user. The LLM generates textual tokens for inquiry responses and makes autonomous decisions to start responding to, wait for, or interrupt the user by emitting control tokens to the neural FSM. All these tasks of the LLM are carried out as next token prediction on a serialized view of the dialogue in real-time. In automatic quality evaluations simulating real-life interaction, the proposed system reduces the average conversation response latency by more than 3 folds compared with LLM-based half-duplex dialogue systems while responding within less than 500 milliseconds in more than 50% of evaluated interactions. Running a LLM with only 8 billion parameters, our system exhibits a 8% higher interruption precision rate than the best available commercial LLM for voice-based dialogue.
Read more5/31/2024

0
Beyond the Turn-Based Game: Enabling Real-Time Conversations with Duplex Models
Xinrong Zhang, Yingfa Chen, Shengding Hu, Xu Han, Zihang Xu, Yuanwei Xu, Weilin Zhao, Maosong Sun, Zhiyuan Liu
As large language models (LLMs) increasingly permeate daily lives, there is a growing demand for real-time interactions that mirror human conversations. Traditional turn-based chat systems driven by LLMs prevent users from verbally interacting with the system while it is generating responses. To overcome these limitations, we adapt existing LLMs to textit{duplex models} so that these LLMs can listen for users while generating output and dynamically adjust themselves to provide users with instant feedback. % such as in response to interruptions. Specifically, we divide the queries and responses of conversations into several time slices and then adopt a time-division-multiplexing (TDM) encoding-decoding strategy to pseudo-simultaneously process these slices. Furthermore, to make LLMs proficient enough to handle real-time conversations, we build a fine-tuning dataset consisting of alternating time slices of queries and responses as well as covering typical feedback types in instantaneous interactions. Our experiments show that although the queries and responses of conversations are segmented into incomplete slices for processing, LLMs can preserve their original performance on standard benchmarks with a few fine-tuning steps on our dataset. Automatic and human evaluation indicate that duplex models make user-AI interactions more natural and human-like, and greatly improve user satisfaction compared to vanilla LLMs. Our duplex model and dataset will be released.
Read more6/26/2024
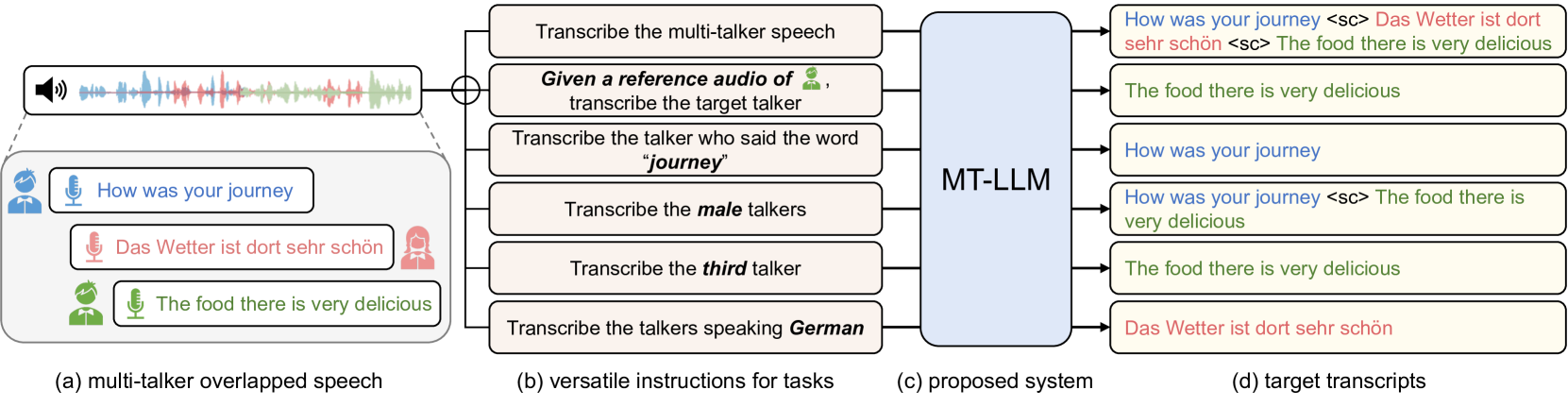
0
New!Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Lingwei Meng, Shujie Hu, Jiawen Kang, Zhaoqing Li, Yuejiao Wang, Wenxuan Wu, Xixin Wu, Xunying Liu, Helen Meng
Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Read more9/16/2024