An FPGA-Based Accelerator for Graph Embedding using Sequential Training Algorithm

0
Sign in to get full access
Overview
- This paper presents the design and implementation of an FPGA-based accelerator for the graph embedding algorithm known as node2vec.
- The goal is to speed up the computationally intensive sequential training process of node2vec, which is used to learn low-dimensional vector representations of nodes in a graph.
- The accelerator leverages the parallelism and efficiency of FPGAs to achieve significant performance improvements over CPU-based implementations.
Plain English Explanation
Graphs are a way of representing connections between different objects or entities. For example, a social network can be represented as a graph, where each person is a node and the connections between them are edges. Understanding Potential FPGA-Based Spatial Acceleration of Large Graph Neural Networks and Advancing Network Intrusion Detection by Integrating Graph Neural Networks discuss the importance of graph-based representations.
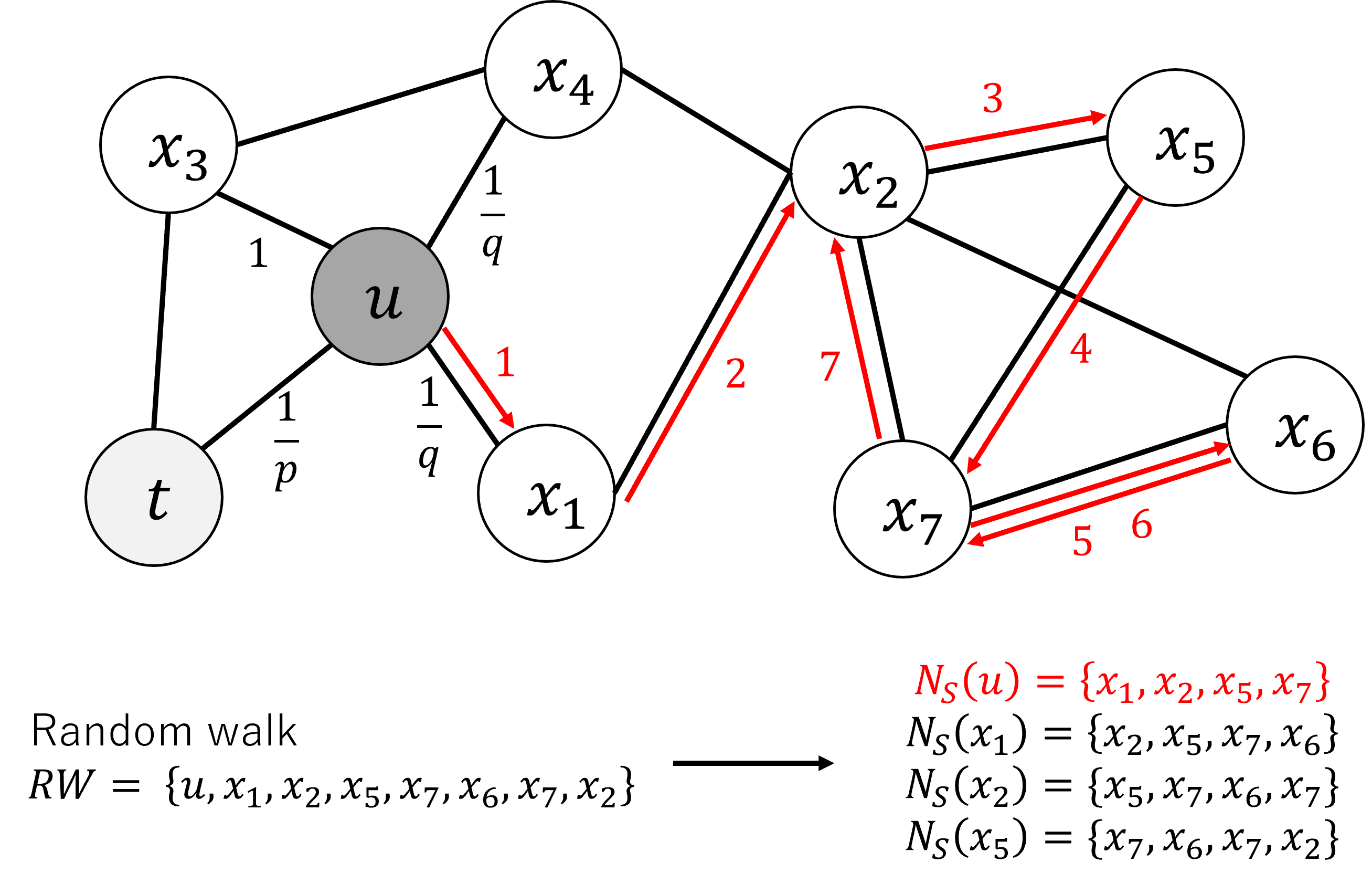
The node2vec algorithm is a way of learning a compact, numerical representation of each node in a graph, called a graph embedding. These embeddings can then be used for various downstream tasks, such as link prediction, node classification, and community detection.
However, the process of training node2vec can be computationally intensive, especially for large graphs. This paper presents a hardware accelerator built using a Field-Programmable Gate Array (FPGA) to speed up the training process. FPGAs are a type of digital circuit that can be programmed to perform specific tasks efficiently in parallel, which can lead to significant performance improvements over traditional CPUs.
Technical Explanation
The paper first provides a detailed overview of the node2vec algorithm, which learns node embeddings by performing random walks on the graph and then optimizing a neural network to predict the context of each node in the walk. GCN-Turbo: End-to-End Acceleration of Graph Convolutional Network Training discusses another graph neural network acceleration approach.
The authors then describe the design of their FPGA-based accelerator, which parallelizes key components of the node2vec training process, such as the random walk generation and the neural network optimization. The accelerator uses custom hardware modules to perform these tasks efficiently, taking advantage of the FPGA's reconfigurable architecture.
The paper presents a comprehensive evaluation of the accelerator, comparing its performance to a CPU-based implementation. The results show that the FPGA-based accelerator can achieve significant speedups, up to 15x, depending on the size of the input graph and other parameters.
Critical Analysis
The paper provides a thorough evaluation of the FPGA-based accelerator and demonstrates its effectiveness in speeding up the node2vec training process. However, the authors acknowledge some limitations of their approach:
- The accelerator is designed for the specific node2vec algorithm and may not generalize well to other graph embedding methods.
- The performance improvements may be less pronounced for smaller graphs, as the overhead of transferring data to the FPGA could outweigh the benefits of the accelerated computation.
- The paper does not explore the energy efficiency of the FPGA-based accelerator, which could be an important consideration in certain applications.
Additionally, the authors do not discuss the potential impact of incremental learning and concept drift detection on the graph embedding process, which could be an interesting area for future research.
Conclusion
This paper presents a novel FPGA-based accelerator for the node2vec graph embedding algorithm, which significantly improves the performance of the computationally intensive training process. The accelerator leverages the parallel processing capabilities of FPGAs to achieve substantial speedups over CPU-based implementations, making it a promising approach for large-scale graph analysis tasks. While the current design is specific to node2vec, the general principles could potentially be applied to other graph embedding methods, further expanding the applications of FPGA-based acceleration in the field of graph learning and analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An FPGA-Based Accelerator for Graph Embedding using Sequential Training Algorithm
Kazuki Sunaga, Keisuke Sugiura, Hiroki Matsutani
A graph embedding is an emerging approach that can represent a graph structure with a fixed-length low-dimensional vector. node2vec is a well-known algorithm to obtain such a graph embedding by sampling neighboring nodes on a given graph with a random walk technique. However, the original node2vec algorithm typically relies on a batch training of graph structures; thus, it is not suited for applications in which the graph structure changes after the deployment. In this paper, we focus on node2vec applications for IoT (Internet of Things) environments. To handle the changes of graph structures after the IoT devices have been deployed in edge environments, in this paper we propose to combine an online sequential training algorithm with node2vec. The proposed sequentially-trainable model is implemented on an FPGA (Field-Programmable Gate Array) device to demonstrate the benefits of our approach. The proposed FPGA implementation achieves up to 205.25 times speedup compared to the original model on ARM Cortex-A53 CPU. Evaluation results using dynamic graphs show that although the accuracy is decreased in the original model, the proposed sequential model can obtain better graph embedding that achieves a higher accuracy even when the graph structure is changed.
Read more4/30/2024
🔍
0
Subgraph2vec: A random walk-based algorithm for embedding knowledge graphs
Elika Bozorgi, Saber Soleimani, Sakher Khalil Alqaiidi, Hamid Reza Arabnia, Krzysztof Kochut
Graph is an important data representation which occurs naturally in the real world applications cite{goyal2018graph}. Therefore, analyzing graphs provides users with better insights in different areas such as anomaly detection cite{ma2021comprehensive}, decision making cite{fan2023graph}, clustering cite{tsitsulin2023graph}, classification cite{wang2021mixup} and etc. However, most of these methods require high levels of computational time and space. We can use other ways like embedding to reduce these costs. Knowledge graph (KG) embedding is a technique that aims to achieve the vector representation of a KG. It represents entities and relations of a KG in a low-dimensional space while maintaining the semantic meanings of them. There are different methods for embedding graphs including random walk-based methods such as node2vec, metapath2vec and regpattern2vec. However, most of these methods bias the walks based on a rigid pattern usually hard-coded in the algorithm. In this work, we introduce textit{subgraph2vec} for embedding KGs where walks are run inside a user-defined subgraph. We use this embedding for link prediction and prove our method has better performance in most cases in comparison with the previous ones.
Read more5/6/2024

0
An Ad-hoc graph node vector embedding algorithm for general knowledge graphs using Kinetica-Graph
B. Kaan Karamete, Eli Glaser
This paper discusses how to generate general graph node embeddings from knowledge graph representations. The embedded space is composed of a number of sub-features to mimic both local affinity and remote structural relevance. These sub-feature dimensions are defined by several indicators that we speculate to catch nodal similarities, such as hop-based topological patterns, the number of overlapping labels, the transitional probabilities (markov-chain probabilities), and the cluster indices computed by our recursive spectral bisection (RSB) algorithm. These measures are flattened over the one dimensional vector space into their respective sub-component ranges such that the entire set of vector similarity functions could be used for finding similar nodes. The error is defined by the sum of pairwise square differences across a randomly selected sample of graph nodes between the assumed embeddings and the ground truth estimates as our novel loss function. The ground truth is estimated to be a combination of pairwise Jaccard similarity and the number of overlapping labels. Finally, we demonstrate a multi-variate stochastic gradient descent (SGD) algorithm to compute the weighing factors among sub-vector spaces to minimize the average error using a random sampling logic.
Read more7/24/2024

0
Encoder Embedding for General Graph and Node Classification
Cencheng Shen
Graph encoder embedding, a recent technique for graph data, offers speed and scalability in producing vertex-level representations from binary graphs. In this paper, we extend the applicability of this method to a general graph model, which includes weighted graphs, distance matrices, and kernel matrices. We prove that the encoder embedding satisfies the law of large numbers and the central limit theorem on a per-observation basis. Under certain condition, it achieves asymptotic normality on a per-class basis, enabling optimal classification through discriminant analysis. These theoretical findings are validated through a series of experiments involving weighted graphs, as well as text and image data transformed into general graph representations using appropriate distance metrics.
Read more5/27/2024