Universal Batch Learning Under The Misspecification Setting
2405.07252
0
0
🏋️
Abstract
In this paper we consider the problem of universal {em batch} learning in a misspecification setting with log-loss. In this setting the hypothesis class is a set of models $Theta$. However, the data is generated by an unknown distribution that may not belong to this set but comes from a larger set of models $Phi supset Theta$. Given a training sample, a universal learner is requested to predict a probability distribution for the next outcome and a log-loss is incurred. The universal learner performance is measured by the regret relative to the best hypothesis matching the data, chosen from $Theta$. Utilizing the minimax theorem and information theoretical tools, we derive the optimal universal learner, a mixture over the set of the data generating distributions, and get a closed form expression for the min-max regret. We show that this regret can be considered as a constrained version of the conditional capacity between the data and its generating distributions set. We present tight bounds for this min-max regret, implying that the complexity of the problem is dominated by the richness of the hypotheses models $Theta$ and not by the data generating distributions set $Phi$. We develop an extension to the Arimoto-Blahut algorithm for numerical evaluation of the regret and its capacity achieving prior distribution. We demonstrate our results for the case where the observations come from a $K$-parameters multinomial distributions while the hypothesis class $Theta$ is only a subset of this family of distributions.
Create account to get full access
Overview
- This paper explores the problem of universal batch learning in a setting where the data is generated by an unknown distribution that may not belong to the hypothesis class of models used by the learner.
- The goal is for the learner to predict a probability distribution for the next outcome, with performance measured by the regret relative to the best hypothesis in the model set.
- The authors derive the optimal universal learner, which is a mixture over the set of data-generating distributions, and provide a closed-form expression for the min-max regret.
Plain English Explanation
In this paper, the researchers look at a problem called "universal batch learning" when the data doesn't perfectly match the set of models the learning algorithm is using. The idea is that the algorithm has to take a set of training data and then make a prediction for what the next outcome will be, and its performance is judged based on how close its predictions are to the actual outcomes.
The key twist is that the data could be coming from some unknown distribution that isn't perfectly captured by the set of models the algorithm is using. So the algorithm has to do the best it can even though the data might not fit neatly into its model set. [link to https://aimodels.fyi/papers/arxiv/parameter-uncertainties-imperfect-surrogate-models-low-noise]
The researchers show that the best way for the algorithm to do this is to use a mixture of all the possible data-generating distributions, and they provide a formula for calculating the best possible performance, which they call the "min-max regret." This regret measure is like a constrained version of the "conditional capacity" between the data and the set of possible data distributions. [link to https://aimodels.fyi/papers/arxiv/taking-moment-distributional-robustness]
They also show that the complexity of this problem is mainly determined by the richness of the set of models the algorithm is using, rather than the complexity of the actual data-generating distribution. And they develop a way to numerically calculate the regret and the optimal mixture distribution. [link to https://aimodels.fyi/papers/arxiv/universal-growth-rate-learning-smooth-surrogate-losses]
They demonstrate their approach using the example of predicting the outcomes of a multinomial distribution, where the algorithm's model set is a subset of the possible multinomial distributions. [link to https://aimodels.fyi/papers/arxiv/awareness-uncertainty-classification-using-multivariate-model-multi]
Technical Explanation
The paper considers the problem of universal batch learning in a setting where the data is generated by an unknown distribution that may not belong to the hypothesis class Θ of models used by the learner. The learner's goal is to predict a probability distribution for the next outcome, and its performance is measured by the regret relative to the best hypothesis in Θ that matches the data.
Using the minimax theorem and information-theoretic tools, the authors derive the optimal universal learner, which is a mixture over the set of data-generating distributions Φ ⊃ Θ. They obtain a closed-form expression for the min-max regret, which can be interpreted as a constrained version of the conditional capacity between the data and the set of data-generating distributions Φ.
The authors show that the complexity of this problem is dominated by the richness of the hypothesis class Θ rather than the complexity of the data-generating distributions in Φ. They develop an extension to the Arimoto-Blahut algorithm for numerically evaluating the regret and the capacity-achieving prior distribution.
The authors demonstrate their results for the case where the observations come from a K-parameter multinomial distribution, while the hypothesis class Θ is a subset of this family of distributions.
Critical Analysis
The paper provides a thorough theoretical analysis of the universal batch learning problem in a misspecification setting, deriving the optimal universal learner and obtaining a closed-form expression for the min-max regret. The authors' approach of leveraging the minimax theorem and information-theoretic tools is well-justified and technically sound.
One potential limitation of the work is that it focuses on the log-loss function as the performance metric. While log-loss is a common choice in probabilistic prediction tasks, it may not capture all the nuances of real-world applications. It could be valuable to extend the analysis to other loss functions, such as those used in [link to https://aimodels.fyi/papers/arxiv/universal-online-learning-gradient-variations-multi-layer].
Additionally, the authors demonstrate their results only for the case of multinomial distributions. It would be interesting to see how the approach generalizes to other families of distributions or more complex data-generating processes.
Finally, the paper does not discuss the practical implementation challenges of the proposed universal learner. Aspects such as computational complexity, sample complexity, and sensitivity to model misspecification could be important considerations for real-world deployment.
Conclusion
This paper makes important theoretical contributions to the understanding of universal batch learning in misspecification settings. By deriving the optimal universal learner and characterizing the min-max regret, the authors provide valuable insights into the inherent complexity and limitations of this problem.
The results suggest that the richness of the hypothesis class, rather than the complexity of the data-generating distributions, is the key factor determining the difficulty of universal learning. This finding could have implications for the design of practical learning algorithms that need to be robust to model misspecification.
Overall, this work advances the state of the art in universal learning and sets the stage for further research into the practical applications and extensions of this framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
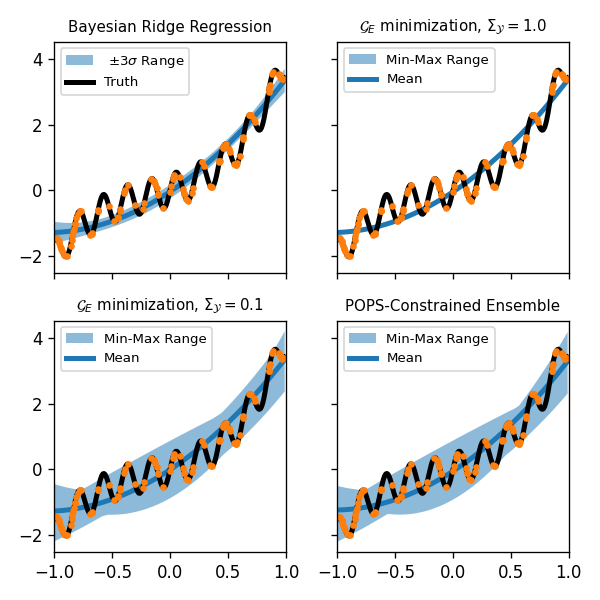
Misspecification uncertainties in near-deterministic regression
Thomas D Swinburne, Danny Perez
0
0
Bayesian regression determines model parameters by minimizing the expected loss, an upper bound to the true generalization error. However, the loss ignores misspecification, where models are imperfect. Parameter uncertainties from Bayesian regression are thus significantly underestimated and vanish in the large data limit. This is particularly problematic when building models of low- noise, or near-deterministic, calculations, as the main source of uncertainty is neglected. We analyze the generalization error of misspecified, near-deterministic surrogate models, a regime of broad relevance in science and engineering. We show posterior distributions must cover every training point to avoid a divergent generalization error and design an ansatz that respects this constraint, which for linear models incurs minimal overhead. This is demonstrated on model problems before application to thousand dimensional datasets in atomistic machine learning. Our efficient misspecification-aware scheme gives accurate prediction and bounding of test errors where existing schemes fail, allowing this important source of uncertainty to be incorporated in computational workflows.
5/8/2024
🏷️
The Real Price of Bandit Information in Multiclass Classification
Liad Erez, Alon Cohen, Tomer Koren, Yishay Mansour, Shay Moran
0
0
We revisit the classical problem of multiclass classification with bandit feedback (Kakade, Shalev-Shwartz and Tewari, 2008), where each input classifies to one of $K$ possible labels and feedback is restricted to whether the predicted label is correct or not. Our primary inquiry is with regard to the dependency on the number of labels $K$, and whether $T$-step regret bounds in this setting can be improved beyond the $smash{sqrt{KT}}$ dependence exhibited by existing algorithms. Our main contribution is in showing that the minimax regret of bandit multiclass is in fact more nuanced, and is of the form $smash{widetilde{Theta}left(min left{|H| + sqrt{T}, sqrt{KT log |H|} right} right) }$, where $H$ is the underlying (finite) hypothesis class. In particular, we present a new bandit classification algorithm that guarantees regret $smash{widetilde{O}(|H|+sqrt{T})}$, improving over classical algorithms for moderately-sized hypothesis classes, and give a matching lower bound establishing tightness of the upper bounds (up to log-factors) in all parameter regimes.
6/21/2024
🛠️
Nearly Minimax Optimal Regret for Multinomial Logistic Bandit
Joongkyu Lee, Min-hwan Oh
0
0
In this paper, we study the contextual multinomial logit (MNL) bandit problem in which a learning agent sequentially selects an assortment based on contextual information, and user feedback follows an MNL choice model. There has been a significant discrepancy between lower and upper regret bounds, particularly regarding the maximum assortment size $K$. Additionally, the variation in reward structures between these bounds complicates the quest for optimality. Under uniform rewards, where all items have the same expected reward, we establish a regret lower bound of $Omega(dsqrt{smash[b]{T/K}})$ and propose a constant-time algorithm, OFU-MNL+, that achieves a matching upper bound of $tilde{O}(dsqrt{smash[b]{T/K}})$. Under non-uniform rewards, we prove a lower bound of $Omega(dsqrt{T})$ and an upper bound of $tilde{O}(dsqrt{T})$, also achievable by OFU-MNL+. Our empirical studies support these theoretical findings. To the best of our knowledge, this is the first work in the contextual MNL bandit literature to prove minimax optimality -- for either uniform or non-uniform reward setting -- and to propose a computationally efficient algorithm that achieves this optimality up to logarithmic factors.
6/24/2024

Taking a Moment for Distributional Robustness
Jabari Hastings, Christopher Jung, Charlotte Peale, Vasilis Syrgkanis
0
0
A rich line of recent work has studied distributionally robust learning approaches that seek to learn a hypothesis that performs well, in the worst-case, on many different distributions over a population. We argue that although the most common approaches seek to minimize the worst-case loss over distributions, a more reasonable goal is to minimize the worst-case distance to the true conditional expectation of labels given each covariate. Focusing on the minmax loss objective can dramatically fail to output a solution minimizing the distance to the true conditional expectation when certain distributions contain high levels of label noise. We introduce a new min-max objective based on what is known as the adversarial moment violation and show that minimizing this objective is equivalent to minimizing the worst-case $ell_2$-distance to the true conditional expectation if we take the adversary's strategy space to be sufficiently rich. Previous work has suggested minimizing the maximum regret over the worst-case distribution as a way to circumvent issues arising from differential noise levels. We show that in the case of square loss, minimizing the worst-case regret is also equivalent to minimizing the worst-case $ell_2$-distance to the true conditional expectation. Although their objective and our objective both minimize the worst-case distance to the true conditional expectation, we show that our approach provides large empirical savings in computational cost in terms of the number of groups, while providing the same noise-oblivious worst-distribution guarantee as the minimax regret approach, thus making positive progress on an open question posed by Agarwal and Zhang (2022).
5/10/2024