Subobject-level Image Tokenization

0

Sign in to get full access
Overview
- Introduces a new approach for image tokenization at the subobject level
- Aims to improve upon existing image tokenization methods by breaking down images into more granular, semantically meaningful components
- Potential applications include improved image understanding, object detection, and segmentation
Plain English Explanation
The paper proposes a novel method for Subobject-level Image Tokenization. Traditional image tokenization typically breaks an image down into a grid of fixed-size patches or tokens. However, this can miss important semantic information about the actual objects and substructures within an image.
The key idea behind this research is to instead segment the image into subobjects - smaller, more meaningful components that correspond to distinct parts of the overall scene. This could include things like individual people, vehicles, furniture, and so on. By tokenizing at the subobject level rather than a rigid grid, the model can better capture the underlying semantics and structure of the image.
The researchers demonstrate how this subobject-level tokenization can lead to performance gains on various computer vision tasks like object detection and image segmentation. The approach could also enable new applications in areas like zero-shot segmentation and visual feature extraction.
Technical Explanation
The core of the proposed method is a subobject segmentation module that breaks down the input image into a set of semantically meaningful regions or subobjects. This is achieved through a combination of instance and semantic segmentation techniques.
First, the image is passed through a instance segmentation model to identify individual objects. Then, a semantic segmentation model is used to classify each instance into semantic categories (e.g. person, car, chair). The resulting segmentation map represents the image decomposed into its constituent subobjects.
These subobjects are then used as the basis for image tokenization. Rather than using a fixed grid, the model generates a variable number of tokens corresponding to the detected subobjects. Each token encodes the visual features and semantic information of its respective subobject.
The researchers evaluate this subobject-level tokenization approach on a range of computer vision benchmarks. They demonstrate improvements over baseline grid-based tokenization, particularly for tasks that require fine-grained understanding of image structure and semantics.
Critical Analysis
The paper presents a compelling approach to image tokenization that aims to better capture the underlying semantics of visual scenes. By moving beyond a rigid grid structure, the subobject-level tokenization appears to offer advantages for downstream tasks that require detailed scene understanding.
That said, the authors acknowledge several limitations and avenues for future work. For example, the subobject segmentation module relies on pre-trained instance and semantic segmentation models, which could introduce biases or errors. There may also be challenges in scaling the approach to handle highly complex or crowded scenes.
Additionally, the paper does not provide an in-depth analysis of the computational costs and runtime performance of the subobject-level tokenization. This would be an important practical consideration, especially for real-world deployment in resource-constrained environments.
Overall, the research represents an interesting step forward in image tokenization and opens up new directions for further exploration in areas like zero-shot segmentation and visual feature extraction. However, as with any new technique, it will be important to carefully evaluate its strengths, limitations, and potential trade-offs as the field continues to evolve.
Conclusion
The proposed Subobject-level Image Tokenization approach represents a novel way of breaking down visual scenes into more semantically meaningful components. By moving beyond a rigid grid-based tokenization, the method aims to better capture the underlying structure and semantics of images, with potential benefits for a range of computer vision tasks.
While the paper demonstrates promising results, it also highlights the need for further research to address the technique's limitations and explore its broader applications. As the field of computer vision continues to advance, innovations like this subobject-level tokenization could play an important role in developing more powerful and versatile image understanding systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Subobject-level Image Tokenization
Delong Chen, Samuel Cahyawijaya, Jianfeng Liu, Baoyuan Wang, Pascale Fung
Transformer-based vision models typically tokenize images into fixed-size square patches as input units, which lacks the adaptability to image content and overlooks the inherent pixel grouping structure. Inspired by the subword tokenization widely adopted in language models, we propose an image tokenizer at a subobject level, where the subobjects are represented by semantically meaningful image segments obtained by segmentation models (e.g., segment anything models). To implement a learning system based on subobject tokenization, we first introduced a Direct Segment Anything Model (DirectSAM) that efficiently produces comprehensive segmentation of subobjects, then embed subobjects into compact latent vectors and fed them into a large language model for vision language learning. Empirical results demonstrated that our subobject-level tokenization significantly facilitates efficient learning of translating images into object and attribute descriptions compared to the traditional patch-level tokenization. Codes and models are open-sourced at https://github.com/ChenDelong1999/subobjects.
Read more4/24/2024
👀
0
A Spitting Image: Modular Superpixel Tokenization in Vision Transformers
Marius Aasan, Odd Kolbj{o}rnsen, Anne Schistad Solberg, Ad'in Ramirez Rivera
Vision Transformer (ViT) architectures traditionally employ a grid-based approach to tokenization independent of the semantic content of an image. We propose a modular superpixel tokenization strategy which decouples tokenization and feature extraction; a shift from contemporary approaches where these are treated as an undifferentiated whole. Using on-line content-aware tokenization and scale- and shape-invariant positional embeddings, we perform experiments and ablations that contrast our approach with patch-based tokenization and randomized partitions as baselines. We show that our method significantly improves the faithfulness of attributions, gives pixel-level granularity on zero-shot unsupervised dense prediction tasks, while maintaining predictive performance in classification tasks. Our approach provides a modular tokenization framework commensurable with standard architectures, extending the space of ViTs to a larger class of semantically-rich models.
Read more8/16/2024
🛠️
0
Tokenize Anything via Prompting
Ting Pan, Lulu Tang, Xinlong Wang, Shiguang Shan
We present a unified, promptable model capable of simultaneously segmenting, recognizing, and captioning anything. Unlike SAM, we aim to build a versatile region representation in the wild via visual prompting. To achieve this, we train a generalizable model with massive segmentation masks, eg, SA-1B masks, and semantic priors from a pre-trained CLIP model with 5 billion parameters. Specifically, we construct a promptable image decoder by adding a semantic token to each mask token. The semantic token is responsible for learning the semantic priors in a predefined concept space. Through joint optimization of segmentation on mask tokens and concept prediction on semantic tokens, our model exhibits strong regional recognition and localization capabilities. For example, an additional 38M-parameter causal text decoder trained from scratch sets a new record with a CIDEr score of 164.7 on the Visual Genome region captioning task. We believe this model can be a versatile region-level image tokenizer, capable of encoding general-purpose region context for a broad range of visual perception tasks. Code and models are available at {footnotesize url{https://github.com/baaivision/tokenize-anything}}.
Read more7/18/2024
0
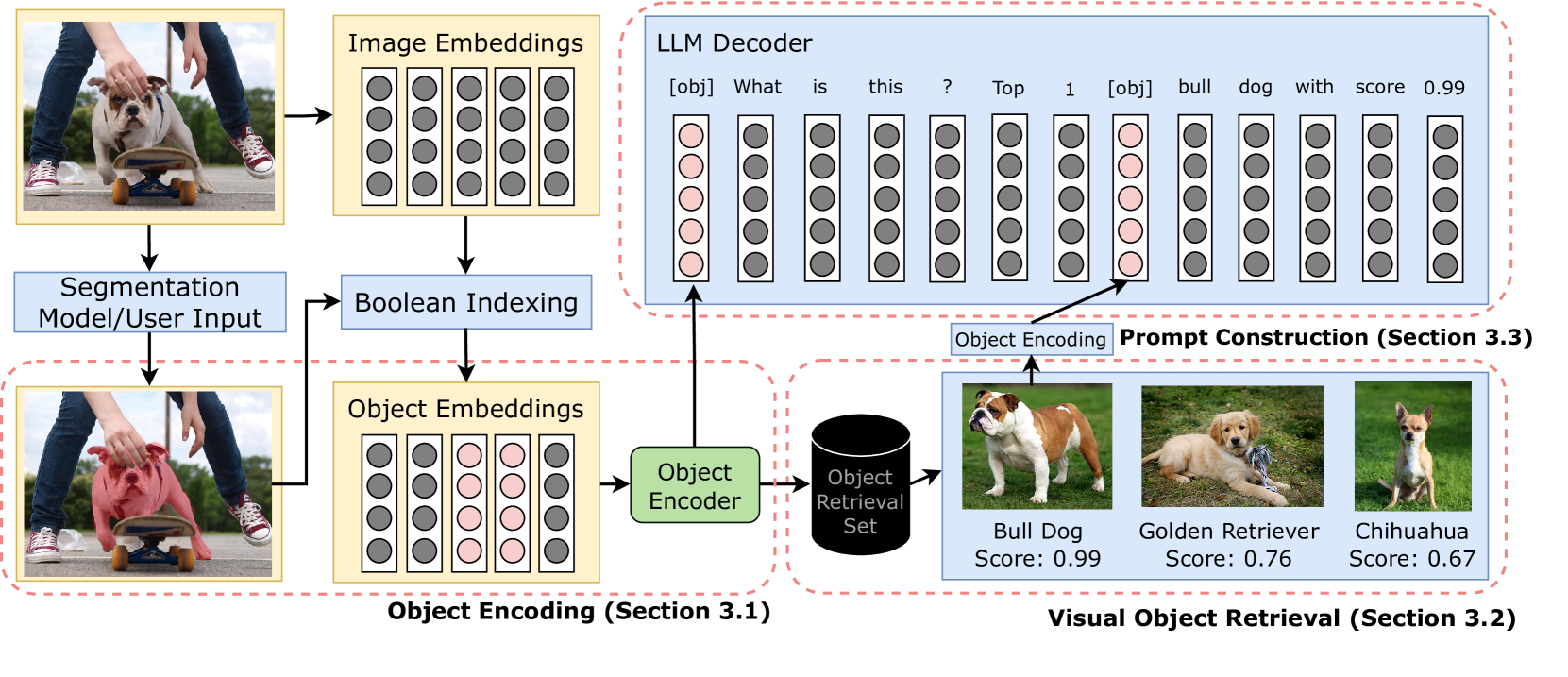
OLIVE: Object Level In-Context Visual Embeddings
Timothy Ossowski, Junjie Hu
Recent generalist vision-language models (VLMs) have demonstrated impressive reasoning capabilities across diverse multimodal tasks. However, these models still struggle with fine-grained object-level understanding and grounding. In terms of modeling, existing VLMs implicitly align text tokens with image patch tokens, which is ineffective for embedding alignment at the same granularity and inevitably introduces noisy spurious background features. Additionally, these models struggle when generalizing to unseen visual concepts and may not be reliable for domain-specific tasks without further fine-tuning. To address these limitations, we propose a novel method to prompt large language models with in-context visual object vectors, thereby enabling controllable object-level reasoning. This eliminates the necessity of fusing a lengthy array of image patch features and significantly speeds up training. Furthermore, we propose region-level retrieval using our object representations, facilitating rapid adaptation to new objects without additional training. Our experiments reveal that our method achieves competitive referring object classification and captioning performance, while also offering zero-shot generalization and robustness to visually challenging contexts.
Read more6/4/2024