Wiki Entity Summarization Benchmark

0
📶
Sign in to get full access
Overview
- The paper proposes a new benchmark called WikES for evaluating entity summarization algorithms on large-scale knowledge graphs.
- Existing datasets are often limited to a few hundred entities and discard the graph structure, particularly for ground-truth summaries.
- WikES combines graph algorithms, NLP models, and different data sources to generate summaries without human annotation, making it cost-effective and scalable.
- The benchmark includes existing datasets for comparison, and empirical studies confirm the usefulness of WikES.
Plain English Explanation
Entity summarization is the process of generating concise summaries for entities (like people, places, or things) in knowledge graphs - large databases that store information about the relationships between different entities. The goal is to provide a quick overview of an entity's key information without having to read through all the details.
However, the datasets and benchmarks used to evaluate entity summarization algorithms have historically been quite limited. They often only include a few hundred entities, and they ignore the connections and structure of the underlying knowledge graph. This is particularly problematic when it comes to the "ground-truth" summaries used to evaluate the algorithms, as there are typically only a handful of these manually-created summaries available.
To address these limitations, the researchers propose a new benchmark called WikES. WikES is a large-scale dataset that includes thousands of entities, their connections, and automatically-generated summaries. The researchers use a combination of graph algorithms and natural language processing (NLP) models to create these summaries, drawing on multiple data sources. This approach is cost-effective and can be applied to knowledge graphs in various domains, without requiring expensive human annotation.
The researchers show that WikES is scalable and can capture the complexities of real-world knowledge graphs. They also include existing datasets in the benchmark, allowing researchers to compare the performance of different entity summarization methods. Empirical studies confirm that WikES is a valuable tool for evaluating and improving these algorithms.
Technical Explanation
The key challenge addressed by the paper is the limited availability of comprehensive benchmarks for evaluating entity summarization algorithms. Existing datasets, such as SumIE, EDiSum, WebCites, and ReflectSumm, are often restricted to a few hundred entities and do not preserve the graph structure of the underlying knowledge base.
To address this, the researchers propose WikES, a large-scale, comprehensive benchmark for entity summarization. WikES includes thousands of entities, their summaries, and the connections between them. Importantly, the researchers use a combination of graph algorithms and NLP models to automatically generate the summaries, drawing on multiple data sources. This approach ensures that WikES does not require expensive human annotation, making it cost-effective and scalable.
The researchers evaluate the usefulness of WikES by testing various entity summarization methods on the benchmark. They find that WikES can capture the complexities of real-world knowledge graphs in terms of topology and semantics, and that the benchmark provides a valuable tool for comparing the performance of different algorithms. The researchers also include existing datasets in WikES, allowing for direct comparisons with previous work.
Critical Analysis
The researchers acknowledge that WikES, like any benchmark, has certain limitations. For example, the automatically-generated summaries may not be as high-quality as human-written ones, and the benchmark may not capture all the nuances of real-world knowledge graph summarization tasks.
Additionally, the researchers do not provide a detailed analysis of the tradeoffs between the different approaches used to generate the summaries (e.g., graph algorithms vs. NLP models). It would be helpful to understand the strengths and weaknesses of each method, as well as the specific factors that influence the quality of the generated summaries.
Moreover, the paper does not discuss the potential biases or inconsistencies that may arise from combining multiple data sources to create the benchmark. It would be valuable to understand how the researchers addressed these issues and ensured the reliability and fairness of the benchmark.
Despite these limitations, the WikES benchmark represents a significant advancement in the field of entity summarization. By providing a large-scale, comprehensive dataset that preserves the structure of knowledge graphs, the researchers have created a valuable tool for researchers and practitioners working in this area. Further research and refinement of the benchmark could lead to even more insightful comparisons of entity summarization algorithms and their real-world applications.
Conclusion
The proposed WikES benchmark addresses a critical limitation in the field of entity summarization by providing a large-scale, comprehensive dataset that preserves the structure and complexity of knowledge graphs. The researchers' approach of combining graph algorithms and NLP models to automatically generate summaries is cost-effective and scalable, making WikES a valuable resource for evaluating and improving entity summarization algorithms.
While the benchmark has some limitations, the researchers' work represents a significant step forward in the field. By making WikES publicly available, they have opened up new opportunities for researchers to explore more advanced entity summarization techniques and their applications in various domains, from information retrieval to data-driven decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Wiki Entity Summarization Benchmark
Saeedeh Javadi, Atefeh Moradan, Mohammad Sorkhpar, Klim Zaporojets, Davide Mottin, Ira Assent
Entity summarization aims to compute concise summaries for entities in knowledge graphs. Existing datasets and benchmarks are often limited to a few hundred entities and discard graph structure in source knowledge graphs. This limitation is particularly pronounced when it comes to ground-truth summaries, where there exist only a few labeled summaries for evaluation and training. We propose WikES, a comprehensive benchmark comprising of entities, their summaries, and their connections. Additionally, WikES features a dataset generator to test entity summarization algorithms in different areas of the knowledge graph. Importantly, our approach combines graph algorithms and NLP models as well as different data sources such that WikES does not require human annotation, rendering the approach cost-effective and generalizable to multiple domains. Finally, WikES is scalable and capable of capturing the complexities of knowledge graphs in terms of topology and semantics. WikES features existing datasets for comparison. Empirical studies of entity summarization methods confirm the usefulness of our benchmark. Data, code, and models are available at: https://github.com/msorkhpar/wiki-entity-summarization.
Read more6/13/2024

0
SUMIE: A Synthetic Benchmark for Incremental Entity Summarization
Eunjeong Hwang, Yichao Zhou, Beliz Gunel, James Bradley Wendt, Sandeep Tata
No existing dataset adequately tests how well language models can incrementally update entity summaries - a crucial ability as these models rapidly advance. The Incremental Entity Summarization (IES) task is vital for maintaining accurate, up-to-date knowledge. To address this, we introduce SUMIE, a fully synthetic dataset designed to expose real-world IES challenges. This dataset effectively highlights problems like incorrect entity association and incomplete information presentation. Unlike common synthetic datasets, ours captures the complexity and nuances found in real-world data. We generate informative and diverse attributes, summaries, and unstructured paragraphs in sequence, ensuring high quality. The alignment between generated summaries and paragraphs exceeds 96%, confirming the dataset's quality. Extensive experiments demonstrate the dataset's difficulty - state-of-the-art LLMs struggle to update summaries with an F1 higher than 80.4%. We will open source the benchmark and the evaluation metrics to help the community make progress on IES tasks.
Read more6/10/2024
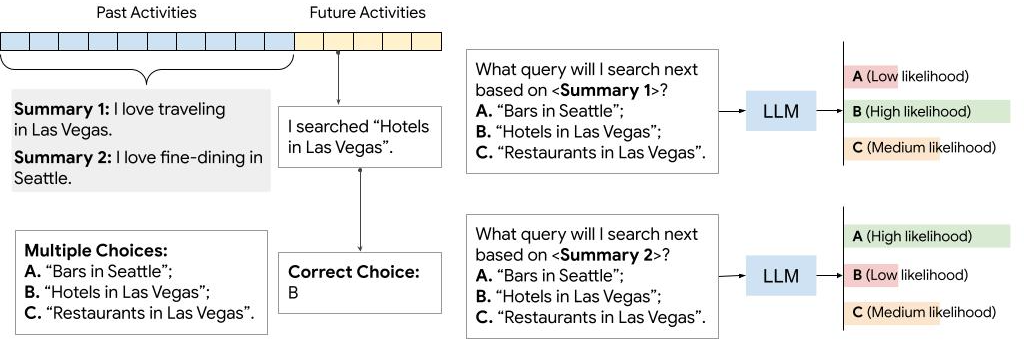
0
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Chao Wang, Neo Wu, Lin Ning, Jiaxing Wu, Luyang Liu, Jun Xie, Shawn O'Banion, Bradley Green
Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
Read more9/9/2024

0
Evidence-Focused Fact Summarization for Knowledge-Augmented Zero-Shot Question Answering
Sungho Ko, Hyunjin Cho, Hyungjoo Chae, Jinyoung Yeo, Dongha Lee
Recent studies have investigated utilizing Knowledge Graphs (KGs) to enhance Quesetion Answering (QA) performance of Large Language Models (LLMs), yet structured KG verbalization remains challengin. Existing methods, such as triple-form or free-form textual conversion of triple-form facts, encounter several issues. These include reduced evidence density due to duplicated entities or relationships, and reduced evidence clarity due to an inability to emphasize crucial evidence. To address these issues, we propose EFSum, an Evidence-focused Fact Summarization framework for enhanced QA with knowledge-augmented LLMs. We optimize an open-source LLM as a fact summarizer through distillation and preference alignment. Our extensive experiments show that EFSum improves LLM's zero-shot QA performance, and it is possible to ensure both the helpfulness and faithfulness of the summary.
Read more6/21/2024