Summaries, Highlights, and Action items: Design, implementation and evaluation of an LLM-powered meeting recap system

0
📉
Sign in to get full access
Overview
- Meetings play a critical role in coordinating work.
- Due to the shift to hybrid and remote work, more meetings are happening online.
- This has led to new problems and new opportunities.
- Recent advances in large language models (LLMs) for dialog summarization have the potential to improve the meeting experience.
- However, these LLMs face technological limitations due to long transcripts and inability to capture diverse recap needs.
Plain English Explanation
In-person meetings have long been a crucial part of how organizations and teams coordinate their work. However, the shift to hybrid and remote work has meant that more meetings are now happening online in Computer Mediated Spaces. This has created both new challenges and new opportunities.
On the one hand, people are spending more time in less engaging online meetings, which can be draining. On the other hand, new technologies like automated transcription/captioning and recap support offer ways to improve the meeting experience.
In particular, recent advances in large language models (LLMs) for dialog summarization have the potential to reduce individual meeting load and increase the clarity and alignment of meeting outputs. These AI systems could automatically summarize key points and action items, helping everyone stay on the same page.
However, these LLM-based systems face some technical limitations. Long meeting transcripts can be challenging for them to process, and they may struggle to capture the diverse recap needs of different participants based on their specific context and roles. To address these gaps, the researchers designed, implemented, and evaluated an AI-powered meeting recap system.
Technical Explanation
The researchers first conceptualized two key representations for meeting recaps: important highlights and a structured, hierarchical minutes view. They then developed a system to operationalize these representations using dialogue summarization as the underlying technology.
To evaluate the effectiveness of this system, the researchers worked with seven users in the context of their regular work meetings. The findings showed promise in using LLM-based dialogue summarization for meeting recaps, with both the highlight and minutes view representations proving useful in different contexts.
However, the researchers also identified some key limitations of the current LLM-based approach. The system still lacked a deep understanding of what was personally relevant to each participant, and it sometimes missed important details or made detrimental mis-attributions that could impact group dynamics.
The researchers saw opportunities for collaboration between the AI system and meeting participants, such as through a shared recap document that builds on the system's high-quality summary. They also highlighted the need for the AI to learn and improve from these natural interactions to better understand personal relevance and improve summarization quality over time.
Critical Analysis
The researchers acknowledge several important caveats and limitations in their work. While the LLM-based meeting recap system showed promise, it still struggles with understanding the personal context and relevance for each participant. This is a significant challenge, as meeting participants often have different goals, priorities, and information needs based on their roles and responsibilities.
Additionally, the system's inability to consistently capture all important details, and the potential for harmful mis-attributions, are concerning issues that need to be addressed. These limitations could undermine the system's usefulness and even negatively impact group dynamics if not handled carefully.
The researchers rightly identify the need for the AI system to learn and improve through ongoing collaboration with users. This co-creative approach, where the system learns from natural interactions, is crucial for overcoming the limitations related to personal relevance and summarization quality.
Further research could explore ways to better model and represent individual participant context, as well as techniques for ensuring high-fidelity summarization that maintains the integrity of the original discussion. Exploring the integration of the recap system with other collaboration tools, such as shared documents or task management systems, may also yield valuable insights.
Conclusion
This research highlights both the potential and the current limitations of using LLM-based dialogue summarization for improving the meeting experience. While the proposed meeting recap system shows promise, the researchers identify key challenges around understanding personal relevance and maintaining summarization quality.
Addressing these limitations through ongoing collaboration between the AI system and meeting participants is a promising avenue for future development. By learning from natural interactions and continuously improving its capabilities, the system can become a more effective partner in helping teams stay aligned, reduce meeting load, and make the most of their time together - whether in-person or in Computer Mediated Spaces.
As organizations continue to navigate the shift to hybrid and remote work, innovative AI-powered tools like this meeting recap system could play a crucial role in supporting productive and engaging collaboration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Summaries, Highlights, and Action items: Design, implementation and evaluation of an LLM-powered meeting recap system
Sumit Asthana, Sagih Hilleli, Pengcheng He, Aaron Halfaker
Meetings play a critical infrastructural role in the coordination of work. In recent years, due to shift to hybrid and remote work, more meetings are moving to online Computer Mediated Spaces. This has led to new problems (e.g. more time spent in less engaging meetings) and new opportunities (e.g. automated transcription/captioning and recap support). Recent advances in large language models (LLMs) for dialog summarization have the potential to improve the experience of meetings by reducing individuals' meeting load and increasing the clarity and alignment of meeting outputs. Despite this potential, they face technological limitation due to long transcripts and inability to capture diverse recap needs based on user's context. To address these gaps, we design, implement and evaluate in-context a meeting recap system. We first conceptualize two salient recap representations -- important highlights, and a structured, hierarchical minutes view. We develop a system to operationalize the representations with dialogue summarization as its building blocks. Finally, we evaluate the effectiveness of the system with seven users in the context of their work meetings. Our findings show promise in using LLM-based dialogue summarization for meeting recap and the need for both representations in different contexts. However, we find that LLM-based recap still lacks an understanding of whats personally relevant to participants, can miss important details, and mis-attributions can be detrimental to group dynamics. We identify collaboration opportunities such as a shared recap document that a high quality recap enables. We report on implications for designing AI systems to partner with users to learn and improve from natural interactions to overcome the limitations related to personal relevance and summarization quality.
Read more8/30/2024

0
What's Wrong? Refining Meeting Summaries with LLM Feedback
Frederic Kirstein, Terry Ruas, Bela Gipp
Meeting summarization has become a critical task since digital encounters have become a common practice. Large language models (LLMs) show great potential in summarization, offering enhanced coherence and context understanding compared to traditional methods. However, they still struggle to maintain relevance and avoid hallucination. We introduce a multi-LLM correction approach for meeting summarization using a two-phase process that mimics the human review process: mistake identification and summary refinement. We release QMSum Mistake, a dataset of 200 automatically generated meeting summaries annotated by humans on nine error types, including structural, omission, and irrelevance errors. Our experiments show that these errors can be identified with high accuracy by an LLM. We transform identified mistakes into actionable feedback to improve the quality of a given summary measured by relevance, informativeness, conciseness, and coherence. This post-hoc refinement effectively improves summary quality by leveraging multiple LLMs to validate output quality. Our multi-LLM approach for meeting summarization shows potential for similar complex text generation tasks requiring robustness, action planning, and discussion towards a goal.
Read more7/17/2024

0
Leveraging discourse structure for the creation of meeting extracts
Virgile Rennard, Guokan Shang, Michalis Vazirgiannis, Julie Hunter
We introduce an extractive summarization system for meetings that leverages discourse structure to better identify salient information from complex multi-party discussions. Using discourse graphs to represent semantic relations between the contents of utterances in a meeting, we train a GNN-based node classification model to select the most important utterances, which are then combined to create an extractive summary. Experimental results on AMI and ICSI demonstrate that our approach surpasses existing text-based and graph-based extractive summarization systems, as measured by both classification and summarization metrics. Additionally, we conduct ablation studies on discourse structure and relation type to provide insights for future NLP applications leveraging discourse analysis theory.
Read more9/24/2024
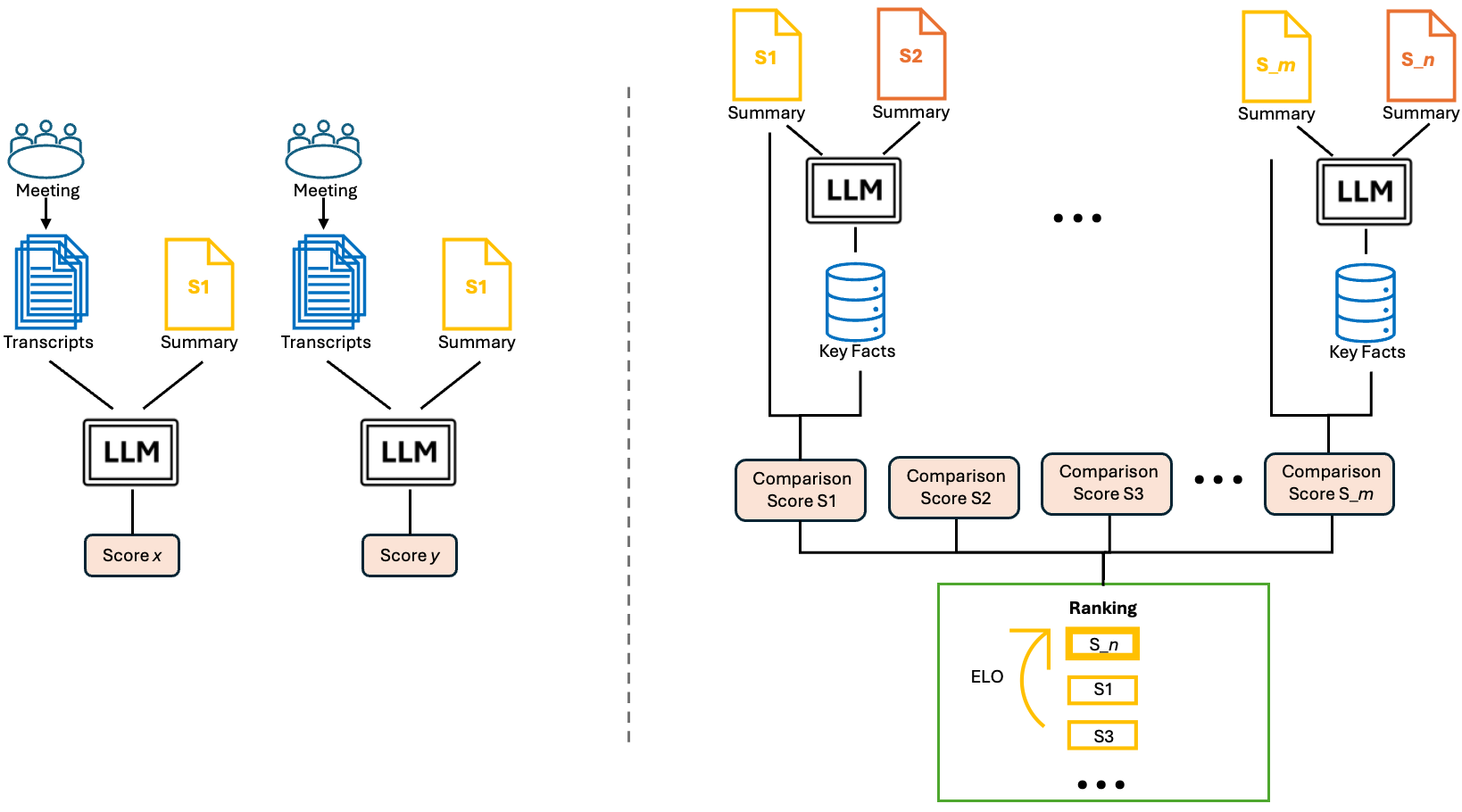
0
CREAM: Comparison-Based Reference-Free ELO-Ranked Automatic Evaluation for Meeting Summarization
Ziwei Gong, Lin Ai, Harshsaiprasad Deshpande, Alexander Johnson, Emmy Phung, Zehui Wu, Ahmad Emami, Julia Hirschberg
Large Language Models (LLMs) have spurred interest in automatic evaluation methods for summarization, offering a faster, more cost-effective alternative to human evaluation. However, existing methods often fall short when applied to complex tasks like long-context summarizations and dialogue-based meeting summarizations. In this paper, we introduce CREAM (Comparison-Based Reference-Free Elo-Ranked Automatic Evaluation for Meeting Summarization), a novel framework that addresses the unique challenges of evaluating meeting summaries. CREAM leverages a combination of chain-of-thought reasoning and key facts alignment to assess conciseness and completeness of model-generated summaries without requiring reference. By employing an ELO ranking system, our approach provides a robust mechanism for comparing the quality of different models or prompt configurations.
Read more9/18/2024